使用styleGAN-encoder学习控制图片的向量
目录
- 前言
- 人脸特征标记数据集
- 使用线性模型学习向量
- 性能评估
前言
使用styleGAN-encoder对生成的图片进行控制 这篇文章中我们使用了储存库内置的向量对生成的图片进行控制,那么接下来我们尝试自己训练一个这样的向量.
人脸特征标记数据集
我们使用一个[潜码对应各种属性]的数据集latent_training_data.pkl.
https://pan.baidu.com/s/1oBs7ayqr_lurywRdFYeU4g 提取码: 1926
数据集共有20307组数据,其中一组长这样:
{'faceAttributes': {'accessories': [],
'age': 50.0,
'blur': {'blurLevel': 'low', 'value': 0.06},
'emotion': {'anger': 0.0,
'contempt': 0.0,
'disgust': 0.0,
'fear': 0.0,
'happiness': 0.999,
'neutral': 0.001,
'sadness': 0.0,
'surprise': 0.0},
'exposure': {'exposureLevel': 'goodExposure', 'value': 0.71},
'facialHair': {'beard': 0.1, 'moustache': 0.1, 'sideburns': 0.1},
'gender': 'male',
'glasses': 'NoGlasses',
'hair': {'bald': 0.11,
'hairColor': [{'color': 'brown', 'confidence': 1.0},
{'color': 'gray', 'confidence': 0.65},
{'color': 'blond', 'confidence': 0.36},
{'color': 'black', 'confidence': 0.23},
{'color': 'red', 'confidence': 0.2},
{'color': 'other', 'confidence': 0.04}],
'invisible': False},
'headPose': {'pitch': 0.0, 'roll': -0.4, 'yaw': 3.1},
'makeup': {'eyeMakeup': False, 'lipMakeup': False},
'noise': {'noiseLevel': 'low', 'value': 0.09},
'occlusion': {'eyeOccluded': False,
'foreheadOccluded': False,
'mouthOccluded': False},
'smile': 0.999},
'faceId': 'b6807d9a-0ab5-4595-9037-c69c656c5c38',
'faceLandmarks': {'eyeLeftBottom': {'x': 386.5, 'y': 497.1},
'eyeLeftInner': {'x': 424.6, 'y': 487.6},
'eyeLeftOuter': {'x': 345.4, 'y': 485.3},
'eyeLeftTop': {'x': 385.2, 'y': 464.8},
'eyeRightBottom': {'x': 644.9, 'y': 496.9},
'eyeRightInner': {'x': 603.8, 'y': 485.0},
'eyeRightOuter': {'x': 686.7, 'y': 485.3},
'eyeRightTop': {'x': 646.0, 'y': 466.2},
'eyebrowLeftInner': {'x': 466.8, 'y': 442.9},
'eyebrowLeftOuter': {'x': 304.3, 'y': 441.0},
'eyebrowRightInner': {'x': 572.8, 'y': 448.0},
'eyebrowRightOuter': {'x': 738.0, 'y': 445.0},
'mouthLeft': {'x': 388.9, 'y': 748.0},
'mouthRight': {'x': 645.1, 'y': 741.8},
'noseLeftAlarOutTip': {'x': 425.6, 'y': 643.8},
'noseLeftAlarTop': {'x': 456.7, 'y': 590.5},
'noseRightAlarOutTip': {'x': 595.7, 'y': 638.2},
'noseRightAlarTop': {'x': 564.5, 'y': 587.1},
'noseRootLeft': {'x': 475.1, 'y': 493.3},
'noseRootRight': {'x': 547.5, 'y': 493.9},
'noseTip': {'x': 518.0, 'y': 648.1},
'pupilLeft': {'x': 386.0, 'y': 480.7},
'pupilRight': {'x': 641.7, 'y': 481.1},
'underLipBottom': {'x': 525.5, 'y': 800.8},
'underLipTop': {'x': 522.6, 'y': 770.5},
'upperLipBottom': {'x': 523.8, 'y': 756.8},
'upperLipTop': {'x': 524.0, 'y': 737.2}},
'faceRectangle': {'height': 584, 'left': 223, 'top': 322, 'width': 584}}
这个数据集对应的应该是karras2019stylegan-ffhq-1024x1024.pkl这个人脸生成styleGAN模型,然后用程序对生成的人脸进行特征识别形成的.
使用线性模型学习向量
import os
import pickle
import config
import dnnlib
import gzip
import json
import numpy as np
from tqdm import tqdm_notebook
import warnings
import matplotlib.pylab as plt
%matplotlib inline
warnings.filterwarnings("ignore")
# 加载数据集
model_dir='./models/latent_training_data.pkl'
qlatent_data, dlatent_data, labels_data = pickle.load(open(model_dir,"rb"))
# qlatent_data Z (20307, 512)
# dlatent_data W+ (20307, 18, 512)
# labels_data 20307
# 格式化数据
X_data = dlatent_data.reshape((-1, 18*512))
y_age_data = np.array([x['faceAttributes']['age'] for x in labels_data])
y_gender_data = np.array([x['faceAttributes']['gender'] == 'male' for x in labels_data])
assert(len(X_data) == len(y_age_data) == len(y_gender_data))
len(X_data)
# 查看数据分布情况
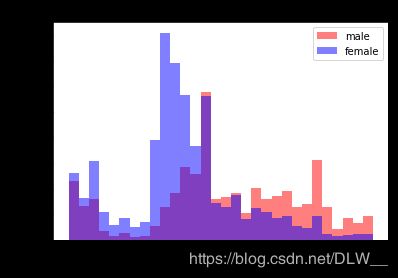
plt.hist(y_age_data[y_gender_data], bins=30, color='red', alpha=0.5, label='male')
plt.hist(y_age_data[~y_gender_data], bins=30, color='blue', alpha=0.5, label='female')
plt.legend()
plt.title('Distribution of age within gender')
plt.xlabel('Age')
plt.ylabel('Population')
plt.show()
# 线性模型库
from sklearn.linear_model import LogisticRegression, SGDClassifier
from sklearn.model_selection import StratifiedKFold, cross_val_score, train_test_split
from sklearn.metrics import accuracy_score
# 执行线性回归,得到性别向量 gender_direction
clf = LogisticRegression(class_weight='balanced').fit(X_data, y_gender_data)
gender_direction = clf.coef_.reshape((18, 512))
性能评估
# 性能评估
clf = SGDClassifier('log', class_weight='balanced') # SGB model for performance sake
scores = cross_val_score(clf, X_data, y_gender_data, scoring='accuracy', cv=5)
clf.fit(X_data, y_gender_data)
print(scores)
print('Mean: ', np.mean(scores))
# [0.87616937 0.88330871 0.88749385 0.88746614 0.84236453]
# Mean: 0.8753605216743173
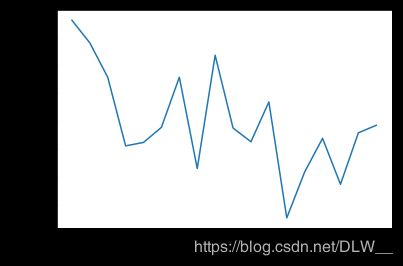
# 评估误差和年龄的关系,可以看出模型不能太好地区分婴儿的性别(我也不行)
bins, bin_edges = np.histogram(y_age_data, bins=30)
errors,_ = np.histogram(y_age_data[clf.predict(X_data) != y_gender_data], bin_edges)
plt.plot(errors / bins)
plt.title('Dependency of gender detection errors on age')
plt.ylabel('Gender detection error rate')
plt.xlabel('Age')
plt.show()
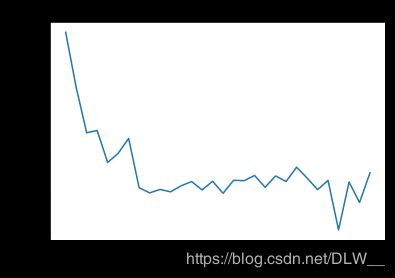
# 评估数据大小对模型准确率的影响,可见在100个标记样本的情况下模型就能达到较高准确率(80%)
nb_folds = 5
splits = 20
scores = np.zeros((splits, nb_folds))
dataset_size = list()
for fold_id, (train_idx, test_idx) in enumerate(StratifiedKFold(nb_folds, True, 42).split(X_data, y_gender_data)):
X_train, X_test = X_data[train_idx][:1000], X_data[test_idx]
y_train, y_test = y_gender_data[train_idx][:1000], y_gender_data[test_idx]
for split_id in range(splits):
nb_samples = int((len(X_train)/splits) * (split_id+1))
dataset_size.append(nb_samples)
clf = SGDClassifier('log', class_weight='balanced').fit(X_train[:nb_samples], y_train[:nb_samples])
scores[split_id][fold_id] = accuracy_score(y_test, clf.predict(X_test))
plt.plot(dataset_size[:splits], scores.mean(axis=1))
plt.title('Dependency of accuracy on training data size')
plt.xlabel('Dataset size')
plt.ylabel('Accuracy')
plt.show()
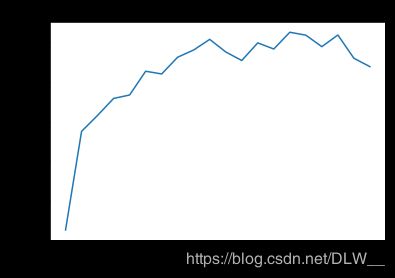
# 评估每一个潜在层的重要性,感觉都挺重要的(真的吗?)
scores = list()
for layer in tqdm_notebook(range(18)):
clf = SGDClassifier('log', class_weight='balanced')
scores.append(cross_val_score(clf, X_data.reshape((-1, 18, 512))[:,layer], y_gender_data, scoring='accuracy', cv=5).mean())
plt.plot(np.arange(0,18), scores)
plt.xlabel('Layer')
plt.ylabel('Accuracy')
plt.show()