Python深度学习笔记(一)简要框架和数学基础
Python深度学习笔记(一)简要框架和数学基础
最近看了《Python深度学习》这本书,学到不少东西,在这里以笔记的形式分享给大家。
简要框架
首先,我们需要明白人工智能,机器学习和深度学习的概念和区别。在这本书中,作者将人工智能定义为:努力将通常由人类完成的智力任务自动化。由此可以看出人工智能是一个综合性的领域。而机器学习和深度学习只是其中的一个分支。
对于机器学习,我最初的印象是给一个机器输进去一套代码,它可以去学习我们人类的知识来实现其智能化。但是读完这本书,我才发现我理解的是肤浅的。机器学习和单片机的编程不一样,单片机编程是给机器输入的是一套规则(也可以说成是程序),机器从外界通过传感器来获取数据来做出相应的反应。机器学习是向机器输入的是一些数据和对应的答案,让机器通过数据和答案来学习(训练),最终机器获取的是一个模型。如下图:
我个人认为机器学习可以这样来理解:通过输入数据和预期的结果通过一种衡量算法效果好坏的方法,使机器学习到执行一项数据处理任务的规则。衡量方法是一种反馈机制,它是用来调节我们机器学习算法一种方法。深度学习是机器学习的一个重要分支。机器学习和深度学习的核心问题在于有意义的变换数据。也可以理解为:让机器通过学习输入的数据和答案,找到一种合适的规则,这种规则可以有意义地处理数据,从而的出我们想要的答案。由此可以看出机器学习重点就是寻找那个合适的规则。接下来我们重点来看一下深度学习。
深度学习是从连续的层(layer)中进行学习的。深度学习的“深度”指的是模型的深度,指一系列连续的表示层。在深度学习中构建模型总是使用神经网络的模型。
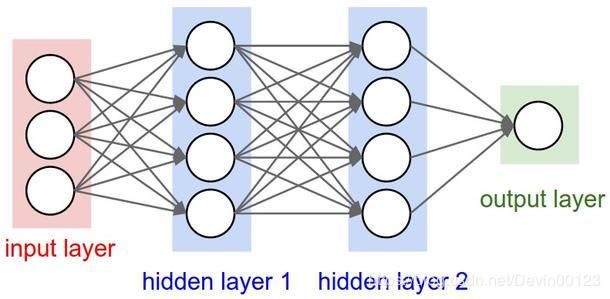
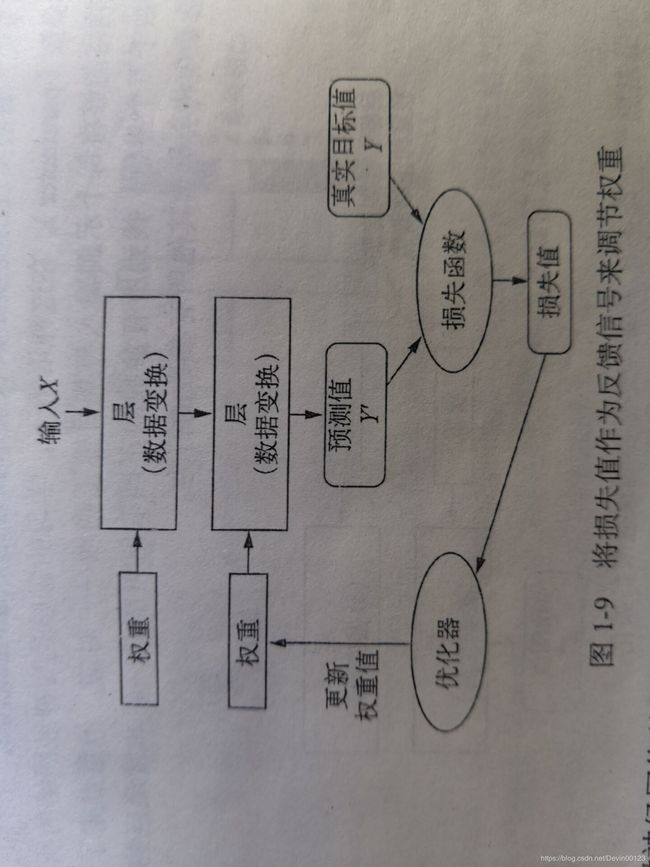
神经网络中每层对输入数据所做的具体操作保存在该层的权重(weight)中,权重其实就是该层的参数。学习的目的就是找到一组权重值,使得该网络能够将每个输入量与其目标一一对应起来。但是随着网络的结构变得复杂,参数的数量也会变得很庞大,同时修改某一参数值会影响其他参数值。这使得寻找一组合适的参数值变得十分困难。这时我们就需要一种方法来控制神经网络的输出并且还能更新参数值,使找到一组合适的参数值。我们就需要用到损失函数和优化器。损失函数又叫目标函数,它其实就是用来衡量输出值和预期值之间的距离。优化器是用来调节神经网络的参数值的。它从损失函数那里获取距离值,将该距离值作为一个反馈信号对参数值进行微调,来减少对应的损失值。优化器使用的是一种反向传播的算法。深度学习的框图如下图所示。
数学基础
深度学习中会经常用到“张量”,张量,张量运算,微分,梯度下降。其实我们只要了解张量的概念即可,至于运算,微分和梯度下降我们可以通过调用库函数就可以实现。那么什么是张量呢?
张量这一概念的核心就在于,它是一个数据容器。我们熟悉的矩阵,它是二维张量(张量的维度通常叫做轴(axis))。
1.标量(0D张量)
仅包含一个数字的张量叫做标量(也叫标量张量,零维张量等),在[Numpy]中,一个float32和float64的数字就是一个张量。可以用[ndim]属性来查看张量的轴的个数。标量张量有0个轴。
>>> import nump as np
>>> x=np.array(12)
>>> x
array(12)
>>>x.ndim
0
2.向量(1D张量)
数字组成的数字叫做向量或者一维张量。一维张量只有一个轴。
>>> x=np.array([12, 3, 6, 7, 8])
>>> x
array([12, 3, 6, 7, 8])
>>> x.ndim
1
这个向量有5个元素,所以称为5D向量。但5D向量和5D张量不一样。向量只有一个轴,5D向量在这个轴上有5个维度。而5D张量有5个轴。因此,为了区分两者,我们经常会说5阶张量(张量的阶数等于轴的个数)。
3.矩阵(2D张量)
向量组成的数组叫做矩阵或二维张量,矩阵有2个轴(行和列)。
>>> x = np.array([[5, 7, 8, 9, 10]
[6, 8, 9, 6, 12]
[7, 9, 5, 7, 15]])
>>> x.ndim
2
第一个轴上的元素叫行(row),第二个轴上的元素叫列(column)。
4.3D张量与更高维张量
多个矩阵组成新数组,可以得到一个3D张量。
>>> x = np.array( [ [ [5, 7, 8, 9, 10]
[6, 8, 9, 6, 12]
[7, 9, 5, 7, 15] ]
[ [5, 7, 8, 7, 9]
[7, 9, 5, 7, 1]
[6, 8, 9, 6, 12] ] ])
>>> x.ndim
3
深度学习处理的一般是0D到4D的张量。
至此,第一部分笔记到这里结束了,初次写博客水平有限,如若文中有明显错误,恳请指出,不胜感激。