使用opencv实现通过摄像头自动输入阿里云身份宝验证码
最近工作中开始使用opencv来做一些跟图像相关的机器学习项目,开始对图像处理产生浓厚的兴趣。搜索资料的时候偶然看到有一些使用opencv读取摄像头的小demo,在输入烦人的阿里云数加身份宝验证码的时候,突发奇想,为何不用摄像头自动识别验证码,实现快速输入。当然,出于学习目的可以用摄像头来输入,如果是公司里,追求短平快和稳定,直接对手机截屏进行识别才是正路。
说干就干,公司台式机没有摄像头,先买一个。19块的看上去有点low,太便宜的一个是担心容易坏,另外是担心拍出来字符不清晰。29的看上去还可以,
再加10块可以买个好看点的,跟公司的显示器气质比较搭。所以最终败了这个:

避免广告嫌疑,牌子就不说了。
免驱,安装后到硬件管理器把音频禁用掉,反正只需要摄像头。
硬件到手,来列一下接下来我们需要完成的任务:
- 使用opencv获取到摄像头的图片
- 正确抠出我们需要识别的数字区域(ROI,region of interest)
- 用机器学习的方法,正确识别图片上的数字
- 起一个http服务,方便调用
- 写一个浏览器小脚本,自动调用我们的http识别服务获取到6位验证码。
整体流程如下图
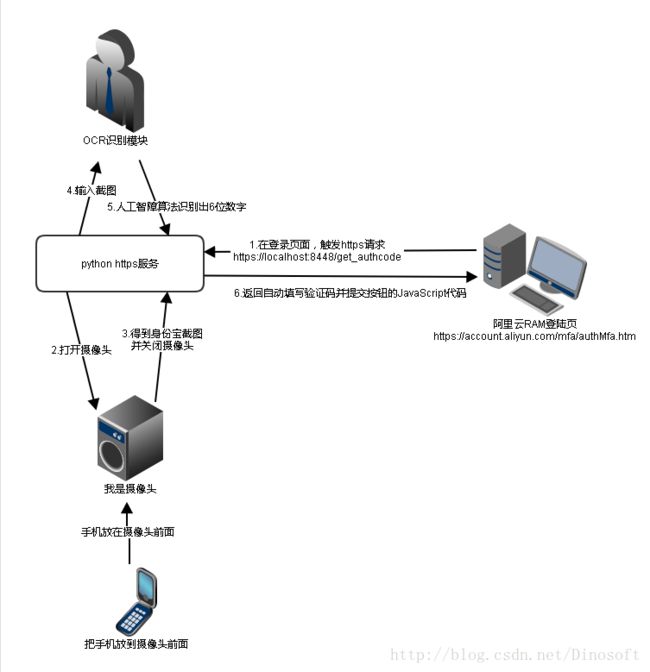
opencv读取摄像头
我们的需求比较简单,从
http://docs.opencv.org/3.0-beta/doc/py_tutorials/py_gui/py_video_display/py_video_display.html
这里找到的一个代码框架完全够用了。
开发的时候可以先从摄像头截取几张图来调试代码。这样图片是固定的,方便debug和调整参数。然后根据相机方向旋转图像。opencv没有直接旋转90度,180度这种函数,但是简单的组合transpose和flip可以实现。

ROI识别
找到了几篇相关的文章,比如这篇。但是没有完整的代码,所以自己简单尝试一下吧。
基本思路是
| 步骤 | 对应的opencv函数 |
|---|---|
| 1.图片黑白二值化 | cv2.cvtColor(image, cv2.COLOR_BGR2GRAY); cv2.threshold |
| 2.找contours | cv2.findContours |
| 3.从contours框出对应的boundingBox | cv2.boundingRect |
因为我们的场景比较简单,通过opencv的简单函数基本可以把ROI提取到,其他类型的图片识别问题就得需要复杂点的方法。比如调试的时候,我不小心截图把窗口边框也截图进去了,这样找boundingBox识别到的是窗口那个框框,就有问题了。把用到的这几个函数对应的文档仔细读读,还挺简单的。
BoundingBox提取出来之后,用一些小trick过滤出我们想要的数字即可。注意数字1比较窄,要特殊照顾一下。
#先按x排序,再按y排序
candidates = sorted(candidates, key=lambda x: x[0] * 10000 + x[1]
for cad in candidates:
x, y, w, h = cad
#面积大小和长宽比例要合适
if image_area * 0.015 > w * h > image_area * 0.0001 and w > 5 and h > 20 and h > 1.2 * w:
if pre_cnt is None:
pre_cnt = [x, y, w, h]
auth_code_img.append(pre_cnt)
continue
x2, y2, w2, h2 = pre_cnt
pre_cnt = [x, y, w, h]
#位置、面积要接近
if abs(x - x2) + abs(y - y2) < w + h and max(w * h, w2 * h2) / min(w * h, w2 * h2) < 5:
auth_code_img.append(pre_cnt)
if len(auth_code_img) == 6:
return auth_code_img
else:
auth_code_img = [pre_cnt]数字OCR
刚开始以为这种打印字体识别起来应该很简单,比如我之前这篇博客介绍的《Digit Recognizer – 从KNN,LR,SVM,RF到深度学习》,结果被现实狠狠打脸了。
先用了一个toy数据集 sklearn.datasets.load_digits,见 http://scikit-learn.org/stable/datasets/index.html。
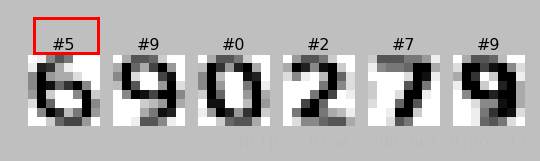
可以发现6识别错了。
算了,放大招mnist数据集
from sklearn.datasets import fetch_mldata
mnist = fetch_mldata('MNIST original', data_home=custom_data_home)可能网络不太好,可以自己到mldata.org下载,打开fetch_mldata的源码看看就知道了,下载用的是matlab格式的数据。
然后加载的时候发现报错了
Process finished with exit code -1073741819 (0xC0000005)
查了一下,是scipy版本过低,https://github.com/ContinuumIO/anaconda-issues/issues/650。自己升级一下吧。
然后用svm训练一把,发现训练很难收敛,结果也很差。最后终于找出来是忘记输入归一化。简直吐血,说多了都是泪。
但是bug改正后,发现效果居然比原来的更差了。

又开始怀疑人生了。。。
分析了一下,训练数据是手写体的,有各种歪歪曲曲的数据,跟我们的机器字体分布不同。而且图片没有crop到中心且最大化,灰度保留[0,255]的范围,没有离散化。load_digits的数据反而把灰度离散化成1到16。

怎么办,svm这种算法解释性并不好,训练出来的模型也难以人工调整。但我们的ground truth是比较明确的。
最后想出一个办法,直接屏幕截图把0-9十个数字搞到,然后比较跟哪个数字比较接近,懒得去查到底是什么字体,反正直接截图挺快的。这种土方法可以算是knn在n_neighbors=1的特例。所以我们用sklearn提供的KNeighborsClassifier来实现就好了。
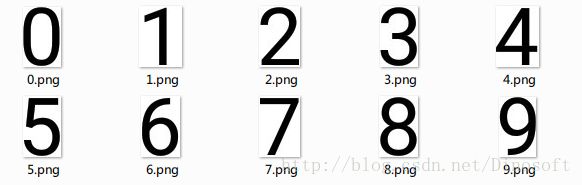
识别的时候,会把图像缩放到固定大小,但是数字1提取处理的图像比较窄,拉伸到标准长宽之后就变得很像7了。所以数字1稍微特殊处理一下,特别窄的直接输出1。
结果发现效果贼好。
simple http server
很简单,例子 http://coolshell.cn/articles/1480.html
自己重写一下do_GET就可以了
class AuthCodeRequestHandler(SimpleHTTPRequestHandler):
def do_GET(self):
print self.path;
if self.path.startswith('/get_authcode'):但是,随着https的普及,问题来了。阿里云的页面是https的,如果插件嵌入我们的http内容,会报错
Mixed Content: The page at ‘https://XX’ was loaded over HTTPS, but requested an insecure resource ‘http://XXXXX‘.
This request has been blocked; the content must be served over HTTPS.
不过还好,python代码只需要加一行
httpd.socket = ssl.wrap_socket (httpd.socket, certfile='D:/X.cer', keyfile='D:/X.pvk', server_side=True)问题是怎么生成https的证书文件。找了一些方法,比如 这个虽然勉强可以运行,但是有难看的不安全标签。

最后还是在这里找到解决方案 https://stackoverflow.com/questions/43929436/subject-alternative-name-missing-err-ssl-version-or-cipher-mismatch
现在好看多了

openssl在git Bash有,如果你有git,可以不用单独再安装。
浏览器脚本
chrome安装一个Tampermonkey插件,然后就可以简单添加各种小脚本到我们需要的页面去执行。
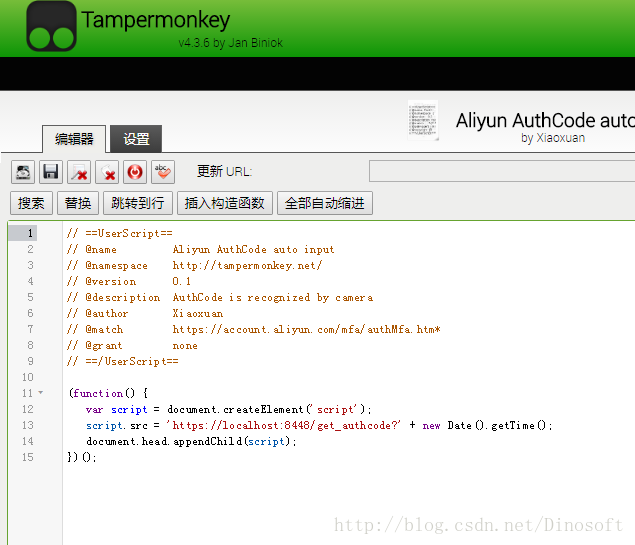
登陆页面的url是https://account.aliyun.com/mfa/authMfa.htm*
我们要做的操作其实只有两步
//第一步,填验证码
document.getElementsByName('authCode')[0].value= 'XXXXXX';
//第二步,点提交按钮
document.getElementById('confirm').click(); 因为是跨域,不能直接用ajax。但逻辑比较简单,可以不用jsonp,http接口直接返回上面两行代码就行。
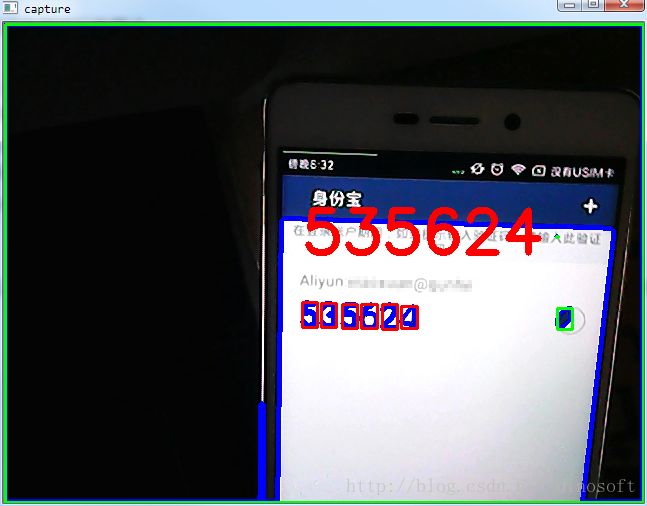
最终效果

跟显示器挺搭的。
小结
可以发现,用摄像头直接获取图片由于环境和输入条件的不同,会出现画面倾斜变形,关照不足等情况,为了提高算法鲁棒性,是需要继续优化的。但是我们这个场景比较简单,而且手机屏幕是自发光的,问题不太严重。这个识别问题继续扩展一下就是车牌识别了,继续学习可以参考EasyPR
另外就是算法实际中应用会发现各种坑,有时候简单粗暴的方法确实有效。
代码整理一下,再放到github上。
https://github.com/dinosoft/aliyun-authcode-recognizer 没怎么仔细整理 随便看看