【分享】腾讯业务系统监控的修炼之路
-
关于监控告警一些需要提前交代的概念。
-
立体化监控体系的阐述。
我现在是织云监控告警产品线的产品经理,而且这部分的产品也在分版本的持续建设中。所以后续主要的产品规划、设计、实现的讲述都是基于织云这个载体上实现。
寻觅初心
以前做QQ业务运维的时候,有一类平台是自己天天会用,那这类平台是什么呢?就是监控告警平台,每天在上面查大量的业务视图、查异常、确认告警、处理告警等等。
对于运维同学来说,如果从使用频率这个维度看,监控告警类平台的使用频率要大于自动化类平台,毕竟自动化类平台多数都是由例行变更触发,而监控告警平台是我们7X24小时都要使用的。当时自己名下有较多的业务和几千台机器,那时有过一天收1000多条告警的记录,相当崩溃。
其实告警如果一天超过几十条就基本是无效的,即关注不过来,也处理不过来。在业务运维这个角色中,我更多的是从使用者这个视角去看监控的。
去年下半年我从业务运维转型为产品经理,现在负责腾讯织云(企业级运维管理平台)监控告警产品线的规划与落地。在产品经理这个阶段我更多的是从建设者这个视角去看监控的。
使用者和建设者这两个视角去看待同一个事物监控告警这个产品,最大的差异点是什么呢?
-
使用者是点,建设者是面,使用者只关注能服务到自己的功能点,而建设者尽量要更全面的抽象多数使用者所具化的场景,在抽象的基础上在去构建功能,力争满足大部分的使用者场景,解决实际的问题。

“出了任何故障,其他环节都是可能有问题,唯独监控是一定有问题!”
—— 乔治·背黑锅
基于这两种不同的视角与在实际建设途中遇到的各种实际问题,我萌发了写一个监控专题系列的想法,哈哈,脸皮蛮厚的的。自己以前都是写单篇的文章,这次也算是一个挑战了。希望通过这个专题能与大家交流下关于一款企业级监控产品是怎么样规划、设计与落地的。
可能是当产品经理习惯了用户场景与角色的分析,如果把这个主题的文章当做一个产品来看,那么其中的角色与场景是什么呢?
梳理一下自己在建设织云监控告警产品线的一些经验和思考。
-
对于刚入行对监控告警这个产品还不太熟悉的新业务运维同学。
-
想自己建设监控告警的运维同学或者运营建设同学。
-
正在建设监控告警平台的运维同学或者产品经理。
-
对监控告警产品天天使用的业务运维同学。
本章主要介绍一些关于监控的通用方法论,我们先理清一些基本概念。
-
监控的定义是什么?
-
监控的方式是什么?
-
监控的类型有哪些?
-
监控的目标是什么?
-
监控的本质是什么?
-
监控的目的是层面?
-
监控的产品属性如何理解?
通过技术手段发现服务异常,持续优化业务可用性与用户体验。这句话的关键词是 发现持续优化可用性与体验。
监控的方式
主动:程序内部埋点,服务主动上报自身的运行情况,一般都是具化为业务的各个属性或者指标,这种方式准、快,灵活性好,指标丰富。但是在非标准框架下会有一定的代码改造成本。
被动:无需埋点,从外部探测或获取服务的运行情况,例如ping探测、日志采集分析等等。
旁路:与程序逻辑无关,对服务质量与口碑的监控,例如舆情分析。
那么这三类有优劣之分吗?其实没有,这里的方式都是针对于不同场景的,例如对域名的监控,就可以通过该域名的外部拨测来达到监控的目标,域名的访问耗时也可以通过不同的拨测点来监控。在我们腾讯内部QQ和Qzone两个海量业务对这三类监控都应用到了。

监控的类型
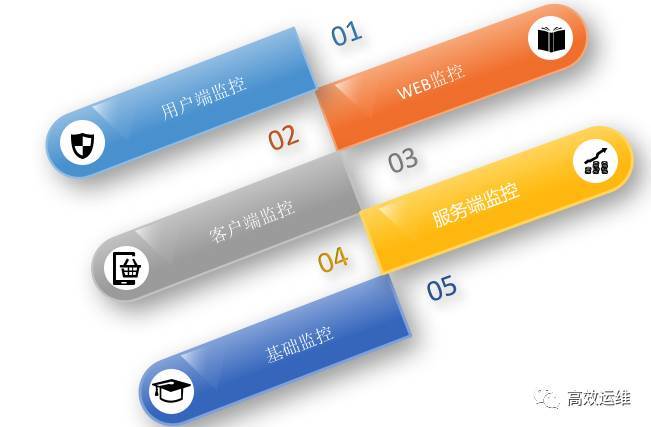
从大的对象范畴与层级关系来说,监控一般分为五种类型
-
基础监控:这里的基础监控囊括范围比较广主要指IAAS层(服务器、系统、网络等)
-
服务端监控:一般指后台服务,例如QQ的后台消息服务
-
客户端监控:一般指app,手Q的客户端与微信的客户端。
-
WEB监控:一般指网站,例如对网站域名的拨测。
-
用户端监控:一般指用户舆情监控,例如某个APP的口碑好坏
一个好的监控体系应该要达到以下三点目标
-
全:监控对象的广度,监控点的覆盖率,例如上文提到的5种对象类型是否都能覆盖到
-
快:监控的性能,数据流的处理能力
-
准:智能分析与收敛、监控对象收拢

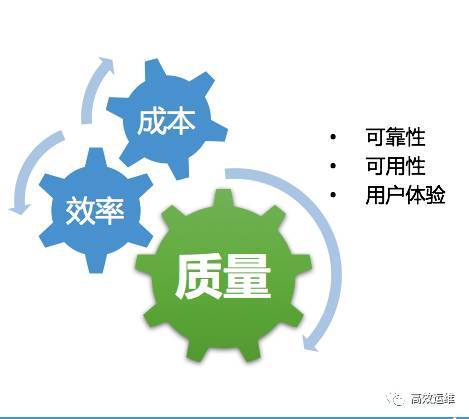
在DevOps中,运维、开发、测试这三个角色应该视角统一,这里为什么说要视角统一,就是大家在监控这个层面关注的点应该是一致的,而不是你关注你的点,我关注我的点。例如所有的业务监控都可以抽象出三个核心指标:请求量、成功率、耗时。这三个关键指标来判断我们服务的可靠性,通过可靠性可以推算出可用性,并且可以间接反映用户使用我们产品的的体验。例如如果服务的可靠性不好,那么用户的产品体验肯定不会好。

监控的目的
通过对上文的一些概念介绍,其实我们已经可以推导出应用监控告警的目的,就是持续优化业务服务质量,并建设质量体系。同样织云监控也是为了打造质量体系的闭环路径。
监控告警的产品属性
监控告警是一款数据类属性的产品,既然是数据类产品,那么在产品设计的时候一定要注意这样的路径闭环 数据生产→数据增值→数据消费,围绕着这样的路径我们就可以勾勒出很多的用户故事,用户故事就是针对具体的角色,会有什么具体的活动,这个活动所产生的价值。

这里举个简单的例子,来说明数据生产与数据消费。随着后面详细的讲述产品建设过程中会更加详细的阐述这个闭环的路径。
数据生产:例如一台服务器上报的各种基本的 OS 指标数据,如 CPU 使用率,内存使用量等。这就产生了若干待消费的原始数据,那么我们能用这些数据干什么呢?
数据消费:对这些上报的原始数据整理可以用作视图展示,例如图形化展示该服务在最近一个小时的 CPU 使用率。 又或者对这些原始数据设定阈值,当超过某个阈值的时候,就产生告警通知。这些都是最直接的消费的场景。
我们再延伸一步对于这些消费场景产生的告警数据,是否可以再进一步消费呢?答案是可以的,例如对若干承载 CPU 计算型业务的服务器所产生的cup使用率告警(生产)时间进行分析统计(消费),是不是可以基本推导出该业务的服务高峰期是大概在那个时间范围呢?
这里想说明的是多数原子数据并无单一的消费或者生产的属性,而是要取决于在具体的场景与所处的数据链条中的角色。
并且监控告警的数据加上特定的流程(ITSM)也可以驱动监控告警+自动化的大的业务逻辑交互闭环,这个场景容我先卖个关子,后面的叙述会再次提及到这部分。
监控体系
体系,泛指一定范围内或同类的事物按照一定的秩序和内部联系组合而成的整体,是不同系统组成的系统。其实这个描述是有些抽象的,咱们用大白话套用监控体系来解读下。
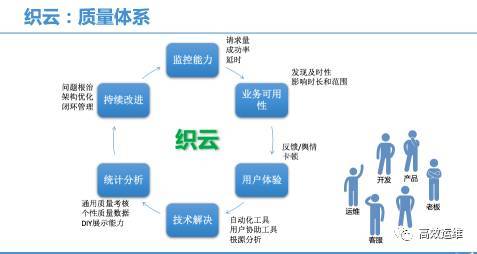
对于一个有一定体量的公司,需要一些不同的监控系统,通过系统与系统间的内部交互来组成一个大的整体,从而完成对不同场景下的监控需求即监控体系。用我们内部来举例说,我们内部在现网上跑的监控系统也有快10套了,同样在构建体系时关键的部分也是要用动态的视角去看待这些系统所产生的数据,而不是每个系统都是一个孤立的数据孤岛。下图是织云整体的监控体系。

在织云监控告警产品建设过程中,我们融入了很多关于海量运维的监控思考与经验沉淀。

这里的监控体系是和公司体量大小有直接关系的,但是一般来说在这个体系中,应该有三类监控系统是必备的。

总结
通过上文的简单介绍,相信大家对监控告警会有个初步的宏观认识,随着后续文章的铺开,大家会逐步了解到一个企业级的监控产品是怎样从0到1演化而来的。同时下篇文文章就会进入到实战阶段。建设监控告警是一条持续且漫长的路也是蛮复杂的,坑也很多,但还是有一些基本的方法论和规律可以遵循的。