SeqGAN
AAAI 2017 《SeqGAN: Sequence Generative Adversarial Nets with Policy Gradient》
github: python2 python3

GAN已经在视觉领域取得了斐然的成就,它可以以一种直观而又精妙的方式生成高质量的图像,逐渐遮住了Auto-encoder、VAE等生成模型的风光,并且在近几年的顶会上相关的论文层出不穷。在视觉领域,我们可以使用GAN完成图像生成、图像修复、风格迁移、Image-to-Image、Text-to-Image等不同的任务,在我前面的博文中主要也是集中在这几个子领域进行介绍。但并没有在自然语言处理(NLP)任务上取得较好的成果,主要的原因可以归结为以下的几个方面:
- GAN主要应用实数空间(连续型数据)上,在生成离散数据(texts)这个问题上并不work。Ian Goodfellow曾提出:“GANs 目前并没有应用到NLP中,最初的 GANs 仅仅定义在实数领域,GANs 通过训练出的生成器来产生合成数据,然后在合成数据上运行判别器,判别器的输出梯度将会告诉你,如何通过略微改变合成数据而使其更加现实。一般来说只有在数据连续的情况下,你才可以略微改变合成的数据,而如果数据是离散的,则不能简单的通过改变合成数据。例如,如果你输出了一张图片,其像素值是1.0,那么接下来你可以将这个值改为1.0001。如果输出了一个单词“penguin”,那么接下来就不能将其改变为“penguin + .001”,因为没有“penguin +.001”这个单词。 因为所有的自然语言处理(NLP)的基础都是离散值,如“单词”、“字母”或者“音节”, NLP 中应用 GANs是非常困难的
- 在生成文本时,判别器只能对整个文本序列进行建模打分,对于部分生成的序列,十分难判断其在之后生成完整序列时的情况
- 另一个问题涉及RNN的性质,假设我们试图从latent codes生成文本,生成过程中出现的错误就会随着句子的长度成指数级的累积。最开始的几个词可能是相对合理的,但是句子质量会随着句子长度的增加而不断变差。另外句子的长度是从随机的latent representation生成的,所以句子长度也是难以控制
首先我们先需要理解清楚离散数据和连续数据的区别:
- 离散变量是指其数值只能用自然数或整数单位计算的则为离散变量.例如,企业个数,职工人数,设备台数等,只能按计量单位数计数,这种变量的数值一般用计数方法取得.
- 连续变量是指能在一定区间内可以任意取值的变量其数值是连续不断的,相邻两个数值可作无限分割,即可取无限个数值.例如,生产零件的规格尺寸,人体测量的身高,体重,胸围等为连续变量,其数值只能用测量或计量的方法取得
那么从上面关于GAN难以直接用于处理离散数据的分析中,我们可以简要的将问题概括为两点:
- 在处理离散数据时,判别器难以使用SGD直接将梯度信息传递给生成器,从而G和D都无法进行更新
- 判别器只能针对于完整的序列数据给出判别结果
如果可以想办法解决上面的两个问题,我们就可以尝试将GAN用于NLP中。SeqGAN就提供了一种很巧妙的思路来解决这两个问题:
- 无法直接使用常规的随机梯度下降进行参数的更新,那就使用强化学习中的策略梯度(policy gradient)
- 判别器无法直接处理部分生成的序列,那就使用蒙特卡洛搜索(Monte Carlo Search)来将已生成的序列补成完整的序列再给出得分
关于策略梯度和蒙特卡罗方法的介绍可见:
Deep Reinforcement learning - Policy Gradient+PPO+TRPO
蒙特卡罗方法初识
SeqGAN
生成模型为 G θ ( y t ∣ Y 1 : t − 1 ) G_{\theta}(y_{t}|Y_{1:t-1}) Gθ(yt∣Y1:t−1),生成序列为 Y 1 : T = ( y 1 , … , y t , … , y T ) , y t ∈ Y Y_{1 : T}=\left(y_{1}, \ldots, y_{t}, \ldots, y_{T}\right), y_{t} \in \mathcal{Y} Y1:T=(y1,…,yt,…,yT),yt∈Y,其中 Y \mathcal{Y} Y为候选项的词汇表。下面我们将文本生成任务看作一个基于强化学习的问题,看策略梯度和蒙特卡洛搜索是如何来解决这个问题的。假设在 t t t时刻模型的状态为 s s s,已经生成的部分序列为 ( y 1 , … , y t − 1 ) \left(y_{1}, \dots, y_{t-1}\right) (y1,…,yt−1),如果下一时刻选择动作 a a a,那么生成的项为 y t y_{t} yt。这里需要注意的一点是:当动作 a a a选定后,状态的转换就是固定的了。例如由状态转移概率为 δ s , s ′ a = 1 \delta_{s, s^{\prime}}^{a}=1 δs,s′a=1和 δ s , s ′ ′ a = 0 \delta_{s, s^{\prime \prime}}^{a}=0 δs,s′′a=0,那么当前状态 s = Y 1 : t − 1 s=Y_{1:t-1} s=Y1:t−1,执行动作 a = y t a=y_{t} a=yt之后,状态必然会转移到 s ′ = Y 1 : t s'=Y_{1:t} s′=Y1:t。
判别模型为 D ϕ ( Y 1 : T ) D_{\phi}(Y_{1:T}) Dϕ(Y1:T),它只接受完整的序列 Y 1 : T Y_{1:T} Y1:T作为输入,判别输入的序列数据是来自真实数据集还是 G θ G_{\theta} Gθ生成的,当 D D D给出反馈后 G θ G_{\theta} Gθ使用策略梯度进行参数的更新。为了和强化学习中的表述一致,这里将判别器的反馈看作奖励,那么 G θ G_{\theta} Gθ的目标是从初始状态 s 0 s_{0} s0出发,希望最大化累计奖励的期望。

假设完整序列的累计奖励记为 R T R_{T} RT,那么 G θ G_{\theta} Gθ的目标函数为

当 G θ G_{\theta} Gθ在生成完整序列后可以得到最大的累计奖励,那么认为它生成的序列足以骗过 D ϕ D_{\phi} Dϕ。其中 Q D ϕ G θ ( s , a ) Q_{D_{\phi}}^{G_{\theta}}(s, a) QDϕGθ(s,a)可写为 Q D ϕ G θ ( a = y T , s = Y 1 : T − 1 ) = D ϕ ( Y 1 : T ) Q_{D_{\phi}}^{G_{\theta}}\left(a=y_{T}, s=Y_{1 : T-1}\right)=D_{\phi}\left(Y_{1 : T}\right) QDϕGθ(a=yT,s=Y1:T−1)=Dϕ(Y1:T),它表示将 D ϕ D_{\phi} Dϕ估计输入的完整序列为真的概率看做是一种奖励。
对于第一个问题已经知道如何使用策略梯度进行解决,那么如何知道在某个中间时刻生成的部分序列的好坏呢?这就需要蒙特卡洛搜索的roll-out策略 G β G_{\beta} Gβ来随机采样 T − t T-t T−t个缺失的项,然后得到"完整的生成序列"。

为了减小偏差以及更准确的评估已生成的序列,这里需要使用 G β G_{\beta} Gβ采样 N N N次得到 N N N个序列进行评估,最后将平均奖励作为 D ϕ D_{\phi} Dϕ给出的奖励值。具体的表达式如下所示: Q D ϕ G θ ( α = y t , s = Y 1 : T − 1 ) = { 1 N ∑ n = 1 N D ϕ ( Y 1 : T n ) , Y 1 : T n ∈ M C G β ( Y 1 : t ; N ) for t < T D ϕ ( Y 1 : t ) for t = T Q_{D_{\phi}}^{G_{\theta}}\left(\alpha=y_{t}, s=Y_{1 : T-1}\right)=\left\{\begin{array}{cc}{\frac{1}{N} \sum_{n=1}^{N} D_{\phi}\left(Y_{1 : T}^{n}\right), Y_{1 : T}^{n} \in M C^{G_{\beta}}\left(Y_{1 : t} ; N\right)} & {\text { for } t<T} \\ {D_{\phi}\left(Y_{1 : t}\right)} & {\text { for } t=T}\end{array}\right. QDϕGθ(α=yt,s=Y1:T−1)={N1∑n=1NDϕ(Y1:Tn),Y1:Tn∈MCGβ(Y1:t;N)Dϕ(Y1:t) for t<T for t=T
当固定判别器后更新的生成器可以产生更加逼真的序列后,再使用 min ϕ − E Y ∼ p data [ log D ϕ ( Y ) ] − E Y ∼ G θ [ log ( 1 − D ϕ ( Y ) ) ] \min _{\phi}-\mathbb{E}_{Y \sim p_{\text { data }}}\left[\log D_{\phi}(Y)\right]-\mathbb{E}_{Y \sim G_{\theta}}\left[\log \left(1-D_{\phi}(Y)\right)\right] minϕ−EY∼p data [logDϕ(Y)]−EY∼Gθ[log(1−Dϕ(Y))]进行判别器的更新,这里的方式和传统的GAN中的方式是一致的。这样 G θ G_{\theta} Gθ和 D ϕ D_{\phi} Dϕ不断的交替更新,直到 D ϕ D_{\phi} Dϕ再无法判别输入序列的来源。
现在模型的整个过程已经很清楚了,下面看一下 G θ G_{\theta} Gθ如何进行参数的更新, G θ G_{\theta} Gθ目标函数的梯度为 ∇ θ J ( θ ) = ∑ t = 1 T E Y 1 : t − 1 ∼ G θ [ ∑ y t ∈ Y ∇ θ G θ ( y t ∣ Y 1 : t − 1 ) ⋅ Q D ϕ G θ ( Y 1 : t − 1 , y t ) ] \nabla_{\theta} J(\theta)=\sum_{t=1}^{T} \mathbb{E}_{Y_{1 : t-1} \sim G_{\theta}}\left[\sum_{y_{t} \in \mathcal{Y}} \nabla_{\theta} G_{\theta}\left(y_{t} | Y_{1 : t-1}\right) \cdot Q_{D_{\phi}}^{G_{\theta}}\left(Y_{1 : t-1}, y_{t}\right)\right] ∇θJ(θ)=∑t=1TEY1:t−1∼Gθ[∑yt∈Y∇θGθ(yt∣Y1:t−1)⋅QDϕGθ(Y1:t−1,yt)],然后使用likelihood ratio trick ∇ f ( x ) = f ( x ) ∇ log f ( x ) \nabla f(x)=f(x) \nabla \log f(x) ∇f(x)=f(x)∇logf(x)构造无偏估计,就有以下公式的推导: ∇ θ J ( θ ) ≃ ∑ t = 1 T ∑ y t ∈ Y ∇ θ G θ ( y t ∣ Y 1 : t − 1 ) ⋅ Q D ϕ G θ ( Y 1 : t − 1 , y t ) = ∑ t = 1 T ∑ y t ∈ Y G θ ( y t ∣ Y 1 : t − 1 ) ∇ θ log G θ ( y t ∣ Y 1 : t − 1 ) ⋅ Q D ϕ G θ ( Y 1 : t − 1 , y t ) = ∑ t = 1 T E y t ∼ G θ ( y t ∣ Y 1 : t − 1 ) [ ∇ θ log G θ ( y t ∣ Y 1 : t − 1 ) ⋅ Q D ϕ G θ ( Y 1 : t − 1 , y t ) ] \begin{array}{l}{\nabla_{\theta} J(\theta) \simeq \sum_{t=1}^{T} \sum_{y_{t} \in \mathcal{Y}} \nabla_{\theta} G_{\theta}\left(y_{t} | Y_{1 : t-1}\right) \cdot Q_{D_{\phi}}^{G_{\theta}}\left(Y_{1 : t-1}, y_{t}\right)} \\ {=\sum_{t=1}^{T} \sum_{y_{t} \in \mathcal{Y}} G_{\theta}\left(y_{t} | Y_{1 : t-1}\right) \nabla_{\theta} \log G_{\theta}\left(y_{t} | Y_{1 : t-1}\right) \cdot Q_{D_{\phi}}^{G_{\theta}}\left(Y_{1 : t-1}, y_{t}\right)} \\ {=\sum_{t=1}^{T} \mathbb{E}_{y_{t} \sim G_{\theta}\left(y_{t} | Y_{1 : t-1}\right)}\left[\nabla_{\theta} \log G_{\theta}\left(y_{t} | Y_{1 : t-1}\right) \cdot Q_{D_{\phi}}^{G_{\theta}}\left(Y_{1 : t-1}, y_{t}\right)\right]}\end{array} ∇θJ(θ)≃∑t=1T∑yt∈Y∇θGθ(yt∣Y1:t−1)⋅QDϕGθ(Y1:t−1,yt)=∑t=1T∑yt∈YGθ(yt∣Y1:t−1)∇θlogGθ(yt∣Y1:t−1)⋅QDϕGθ(Y1:t−1,yt)=∑t=1TEyt∼Gθ(yt∣Y1:t−1)[∇θlogGθ(yt∣Y1:t−1)⋅QDϕGθ(Y1:t−1,yt)]
关于likelihood ratio trick的介绍可见Machine Learning Trick of the Day (5): Log Derivative Trick和论文:
Likelihood ratio gradient estimation for stochastic systems
最后使用 θ ← θ + α h ∇ θ J ( θ ) \theta \leftarrow \theta+\alpha_{h} \nabla_{\theta} J(\theta) θ←θ+αh∇θJ(θ)进行更新即可,整个算法流程为:

训练过程中的Tricks:
- 先使用MLE在数据集 S S S预训练 G θ G_{\theta} Gθ
- 为了减少偏差,输入到 D ϕ D_{\phi} Dϕ中的正例和负例的数目要一致
- G θ G_{\theta} Gθ使用的是LSTM,当然也可以使用GRU或软注意力机制

- 判别器使用的是CNN

实验
实验部分主要分为合成数据实验和现实数据实验
- 合成数据实验: 随机初始一个LSTM生成器A,随机生成一部分训练数据,来训练各种生成模型。评判标准为:负对数似然(交叉熵) NLL. 详细实验设置可以参看原论文。
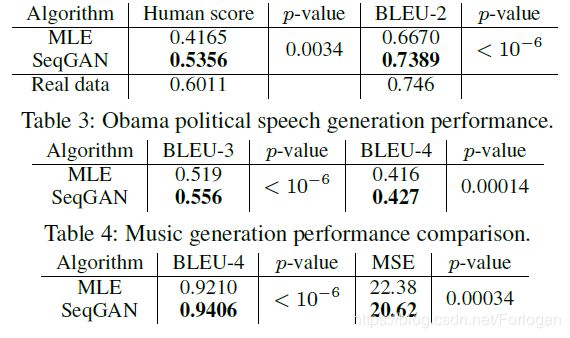
- 现实数据实验:主要展示中文诗句生成,奥巴马演讲生成,音乐生成的结果。实验数据分别为中文诗歌数据集 (16,394首绝句)、奥巴马演讲数据集 (11,092 段落)、Nottingham音乐数据集 (695首歌)。评测方法为BLEU score, 实验结果如下:
中文诗歌生成效果

奥巴马演讲生成效果

总结
SeqGAN本身的想法并不能理解,但是它创新性的将GAN和NLP结合到了一起,为后续的相关研究开了一个好头~
后续还将给出IRGAN: A Minimax Game for Unifying Generative and Discriminative Information Retrieval Models和Adversarial Learning for Neural Dialogue Generation这两篇关于GAN+NLP文章的总结。
参考
干货|GAN for NLP (论文笔记及解读)
对抗思想与强化学习的碰撞-SeqGAN模型原理和代码解析
论文分享-- >SeqGAN: Sequence Generative Adversarial Nets with Policy Gradient
Role of RL in Text Generation by GAN(强化学习在生成对抗网络文本生成中扮演的角色)
SeqGAN —— GAN + RL +NLP