深入理解Java虚拟机(二)
四、虚拟机性能监控与故障处理工具
| 名称 | 主要作用 |
| jps | JVM Process Status Tool, 显示指定系统内所有的HotSpot虚拟机进程 |
| jstat | JVM Statics Monitoring Tool, 用于收集HotSpot虚拟机各方面的运行数据 |
| jinfo | Configuration Info for Java, 显示虚拟机配置信息 |
| jmap | Memory Map for Java, 生成虚拟机的内存快照 |
| jhat | JVM Heap Dump Browser, 用于分析heapdump文件 |
| jstack | Stack Trace for Java, 显示虚拟机的线程快照 |
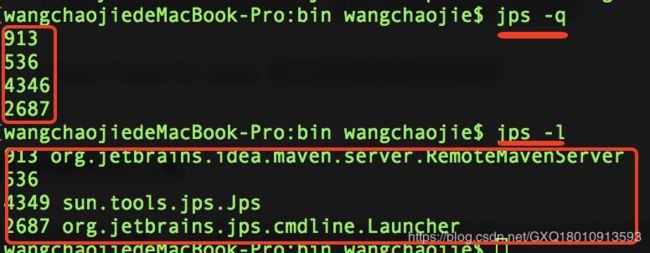
1、jps:虚拟机进程状况工具
jps 命令类似与 linux 的 ps 命令,但是它只列出系统中所有的 Java 应用程序。 通过 jps 命令可以方便地查看 Java 进程的启动类、传入参数和 Java 虚拟机参数等信息。
如果在 linux 中想查看 java 的进程,一般我们都需要 ps -ef | grep java 来获取进程 ID。
如果只想获取 Java 程序的进程,可以直接使用 jps 命令来直接查看。
-q:只输出进程 ID
-m:输出传入 main 方法的参数
-l:输出完全的包名,应用主类名,jar的完全路径名
-v:输出jvm参数
-V:输出通过flag文件传递到JVM中的参数
2、jstat:虚拟机统计信息监视工具
监视虚拟机各种运行状态信息,可以显示本地或远程虚拟机进程中的类装载、内存、垃圾收集、JIT编译等运行数据。
//后面两个参数可以不写,不写默认只查询一次
jstat 查询的区域(类装载、垃圾收集、运行期编译) 进程id 查询间隔时间(毫秒) 共查询几次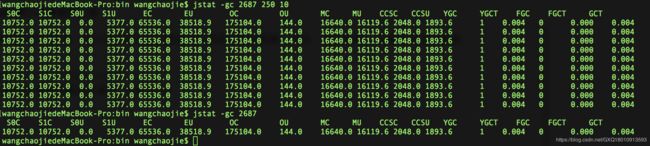
具体参数释义见:https://www.cnblogs.com/yjd_hycf_space/p/7755633.html
| 选项 | 作用 |
| -class | 监视类装载、卸载数量、总空间以及类装载所耗费的时间 |
| -gc | 监视Java堆状况,包括Eden区、两个survivor区、老年代、永久代等的容量、已用空间、GC时间合计等信息 |
| -gccapacity | 监视内容与-gc基本相同,但输出主要关注Java堆各个区域使用的最大、最小空间 |
| -gcutil | 监视内容与-gc基本相同,但输出主要关注已使用空间占总空间的百分比 |
| -gccause | 与-gcutil功能一样,但是会额外输出导致上一次GC产生的原因 |
| -gcnew | 监视新生代GC状况 |
| -gcnewcapacity | 监视内容与-gcnew基本相同,输出主要关注使用到的最大、最小空间 |
| -gcold | 监视老年代GC状况 |
| -gcoldcapacity |
监视内容与-gcold基本相同,输出主要关注使用到的最大、最小空间 |
| -gcpermcapacity | 输出永久代使用到的最大、最小空间 |
| -compiler | 输出JIT编译器编译过的方法、耗时等信息 |
| -printcompilation | 输出已经被JIT编译的方法 |
3、jinfo:Java配置信息工具
实时查看和调整虚拟机各项参数。jinfo [option] pid

4、jmap:Java内存映像工具:用于生成堆转储快照。
5、jhat:虚拟机堆转储快照分析工具
与jmap搭配使用,来分析jmap生成的堆转储快照。但很少会这么做,一是分析工作时比较耗时且消耗硬件资源的过程;二是jhat的分析功能相对简陋,不如VisualVM
6、jstack:Java堆栈跟踪工具
用于生成虚拟机当前时刻的线程快照,也就是当前虚拟机内每一条线程正在执行的方法堆栈的集合。生成线程快照的主要目的是定位线程出现长时间停顿的原因,如线程死锁、死循环、请求外部资源导致的长时间等待等。
7、HSDIS:JIT生成代码反汇编
作用在于让HotSpot虚拟机的-XX:+PrintAssembly指令调用它来把动态生成的本地代码还原为汇编代码输出。
OQL查询语句
VisualVM:多合一故障处理工具
要想使用VisualVM达到更好的效果,需要给VisualVM安装相应插件,其默认插件只提供了基本的监视、线程面板的功能等
BTrace动态日志跟踪
/**
* @author wangchaojie
* @description BTrace跟踪演示
* @date 2019/9/25 13:50
*/
public class BTraceTest {
public int add(int a, int b) {
return a + b;
}
public static void main(String[] args) throws IOException {
BTraceTest test = new BTraceTest();
BufferedReader reader = new BufferedReader(new InputStreamReader(System.in));
for (int i = 0; i < 10; i++) {
reader.readLine();
int a = (int) Math.round(Math.random() * 1000);
int b = (int) Math.round(Math.random() * 1000);
System.out.println(a+"--"+b);
System.out.println(test.add(a, b));
}
}
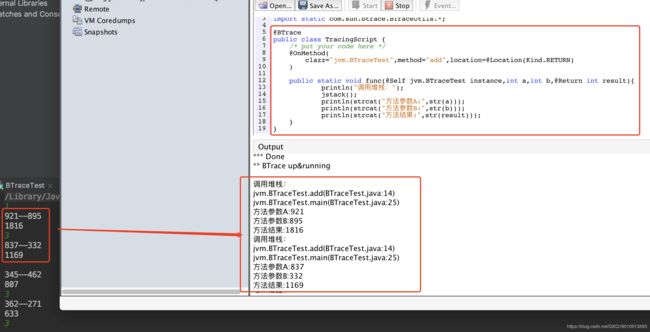
}当上述程序运行后,在Visual VM的对应程序进程监控中,编写TracingScript内容如下,然后点击“start”按钮,输出结果
@BTrace
public class TracingScript {
/* put your code here */
@OnMethod(
clazz="jvm.BTraceTest",method="add",location=@Location(Kind.RETURN)
)
public static void func(@Self jvm.BTraceTest instance,int a,int b,@Return int result){
println("调用堆栈:");
jstack();
println(strcat("方法参数A:",str(a)));
println(strcat("方法参数B:",str(b)));
println(strcat("方法结果:",str(result)));
}
}
五、调优案例分析与实战
1、高性能硬件上的程序部署策略
2、集群间同步导致的内存溢出
3、堆外内存导致的溢出错误
4、外部命令导致系统缓慢
5、服务器JVM进程崩溃
6、不恰当数据结构导致内存占用过大
7、由Window虚拟内存导致的长时间停顿
------------------------------------------------------------------------------------------------------------------------------------------------------------------------
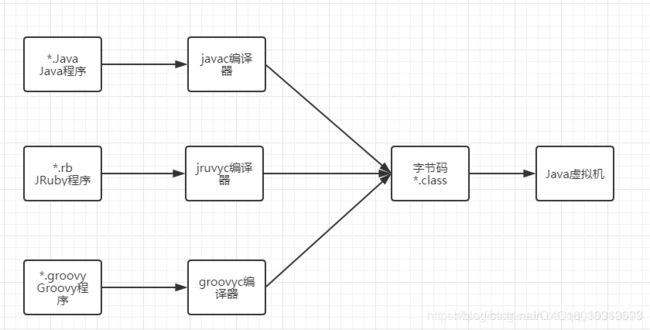
Java编译原理
Java为了实现跨平台的特性,Java代码编译出来后形成的Class文件中存储的是字节码,虚拟机通过解析方式执行字节码命令,比C/C++编译,速度要慢不少。为了解决此问题,JDK1.2以后,虚拟机内置了两个运行时编译器(在JDK1.2之前,也可以使用外挂编译器,但只能与解释器二选一,不可同时存在),如果当Java方法被调用次数达到一定程度时,就会判定为热代码交给JIT编译器即时编译为本地代码,提供运行速度。甚至可能在运行期动态编译比C/C++的编译器静态译编出来的代码更优秀。
所以Java程序只有代码没有问题,随着代码被编译得越来越彻底,运行速度应当是越来越快的。
//解读:代表当前内存为9216k,内存使用到5100K的时候发送了GC,花费了0.0009777秒把内存使用降到了0K。
5100K->0K(9216K), 0.0009777 secs六、类文件结构
无关性的基石
各种不同平台的虚拟机与所有平台都统一使用的程序存储格式--字节码是构成平台无关性的基石。虚拟机还拥有一种中立特性--语言无关性,能支持其他语言运行在JVM上。
实现语言无关性的基础仍然是虚拟机和字节码存储格式。Java虚拟机不和包括Java在内的任何语言绑定,它只与“Class文件”这种特定的二进制文件所关联,Class文件中包含了Java虚拟机指令集和符号表以及若干辅助性信息。
使用Java编译器可以把Java代码编译为存储字节码的Class文件,使用JRuby等语言的编译器一样可以将程序代码编译成Class文件,虚拟机并不关心Class的来源是何种语言。
Class类文件的结构
Class文件是一组8位字节为基础单位的二进制流,各个数据项目严格按照顺序紧凑地排列在Class文件之中,中间没有添加任何分隔符,这使得整个Class文件中存储的内容几乎全部都是程序运行的必要数据,没有空隙存在。当遇到需要占用8位字节以上空间的数据项时,则会按照高位在线的方式分割成若干个8位字节进行存储。
Class文件格式采用一种类似于C语言结构体的伪结构来存储数据,这种伪结构中只有两个数据类型:无符号数和表。
无符号数属于基本的数据类型,以u1、u2、u4、u8来分别代表1个字节、2个字节、4个字节、8个字节的无符号数,无符号数用于描述数字、索引引用、数值或安装UTF-8编码构成的字符串。
表是由多个无符号数或者其他表作为数据项构成的复合数据类型,所有表都习惯性地以“_info”结尾。表用于描述有层次关系的复合结构数据。整个Class文件本质上就是一张表,是由以下的数据项构成:
| 类型 | 名称 | 数量 |
|---|---|---|
| u4 | magic | 1 |
| u2 | minor_version | 1 |
| u2 | major_version | 1 |
| u2 | constant_pool_count | 1 |
| cp_info | constant_pool | constant_pool_count - 1 |
| u2 | access_flags | 1 |
| u2 | this_class | 1 |
| u2 | super_class | 1 |
| u2 | interfaces_count | 1 |
| u2 | interfaces | interfaces_count |
| u2 | fields_count | 1 |
| field_info | fields | fields_count |
| u2 | methods_count | 1 |
| method_info | methods | methods_count |
| u2 | attribute_count | 1 |
| attribute_info | attributes | attributes_count |
Class的结构不像XML等描述语言,由于它没有任何分割符号,所以在上图中的数据项,顺序、数量、数据存储的字节序都是被严格限定的。
1、魔数与Class文件的版本
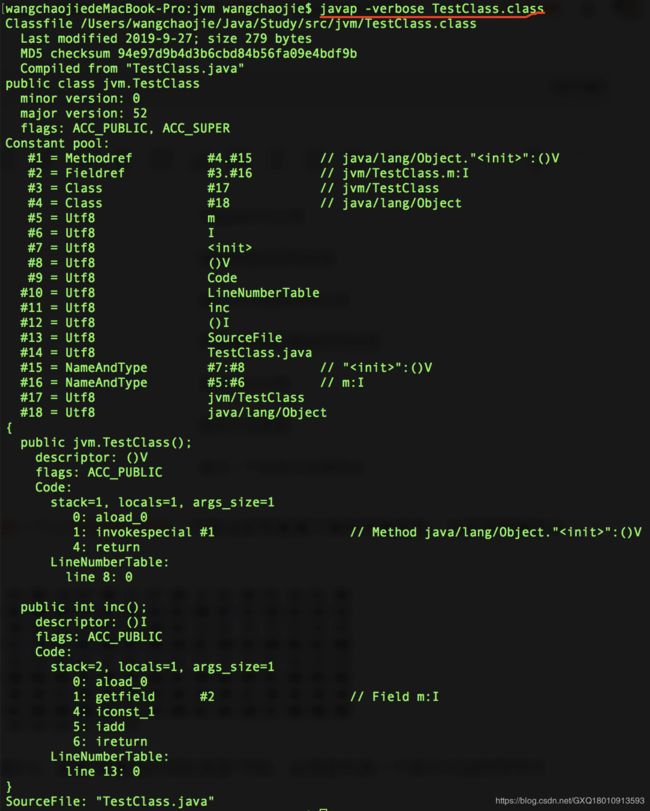
魔数:每个Class文件的头4个字节。其作用是确定这个文件是否能被虚拟机接受的Class文件。使用魔数而不是扩展名进行识别,主要是基于安全考虑,因为文件扩展名可以随意地改动。文件格式制定者可以自由选择魔数值,只要不混淆就行,比如Class文件的魔数值为:0xCAFEBABE。
紧接着魔数的4个字节存储的是Class文件的版本号(图中的magic),第5和第6个字节是次版本号(图中的minor_version),第7和第8个字节是主版本号(图中的major_version)。Java的版本号从45开始,JDK1.1之后的每个JDK大版本发布主版本号向上加1(JDK1.0~1.1使用了45.0~45.3的版本号),高版本的JDK能向下兼容以前版本的Class文件,但不能运行之后版本的。JDK1.7可生成的主版本号最大值为51.0
public class TestClass {
private int m;
public int inc() {
return m + 1;
}
}
上图是Class文件打开的结果,一个偏移地址代表一个字节,所以第一部分代表的是开头四个偏移地址代表四个字节,0xCAFEBABE代表是个Class文件,第二部分代表的是次版本号,0x0000,第三部分代表的是主版本号,0x0034,也就是十进制的52,该Class文件版本号说明需要被虚拟机1.8以上的版本执行。
2、常量池
紧接着主次版本号之后的就是常量池入口,常量池是Class文件之后的资源仓库,是Class文件结构中与其他项目关联最多的数据类型,也是占用Class文件空间最大的数据项目之一,同时还是Class文件中第一个出现的表类型数据项目。
由于常量池中常量的数量是不固定的,所以在常量池的入口放置一项u2类型的数据,代表常量池容量计数值(constant_pool_count)。该值是从1开始的

如图所示,框中的代表常量池入口,常量池计数值为2个字节,所以容量就是0x0013,也就是十进制的19,代表常量池中有18项常量,索引值范围1~18。Class文件结构中只有常量池的容器计数是从1开始的,对于其他集合类型,包括接口索引集合、字段表集合、方法表集合等都是从0开始的。
常量池中主要存放两大类常量:字面量和符号引用。
- 字面量:类似于Java的常量概念,如文本字符串、声明为final的常量值等
- 符号引用:属于编译原理的概念,包括三类常量:类和接口的全限定名、字段的名称和描述符、方法的名称和描述符
常量池中的每个常量都是一个表,在JDK1.7以前有11种,JDK1.7为了更好支持动态语言调用,额外增加了最后三种,如图所示
| 类型 | 标志 | 描述 |
| CONSTANT_Utf8_info | 1 | UTF-8编码的字符串 |
| CONSTANT_Integer_info | 3 | 整型字面量 |
| CONSTANT_Float_info | 4 | 浮点型字面量 |
| CONSTANT_Long_info | 5 | 长整型字面量 |
| CONSTANT_Double_info | 6 | 双精度浮点型字面量 |
| CONSTANT_Class_info | 7 | 类或接口的符号引用 |
| CONSTANT_String_info | 8 | 字符串类型字面量 |
| CONSTANT_Fieldref_info | 9 | 字段的符号引用 |
| CONSTANT_Methodref_info | 10 | 类中方法的符号引用 |
| CONSTANT_InterfaceMethodref_info | 11 | 接口中方法的符号引用 |
| CONSTANT_NameAndType_info | 12 | 字段或方法的部分符号引用 |
| CONSTANT_MethodHandle_info | 15 | 表示方法句柄 |
| CONSTANT_MethodType_info | 16 | 表示方法类型 |
| CONSTANT_InvokeDynamic_info | 18 | 表示一个动态方法调用点 |
这14种表都有一个共同的特点,就是表开始的第一位是一个u1类型的标志位,代表当前常量属于哪种常量类型,也就是常量池计数器后面紧跟的1个字节,如图所示:

上图中的常量池的第一项常量标志位为0x0A,即十进制10,查看“常量池的项目类型”可知,此类型代表一个类中方法的符号引用。当我们使用字节码分析工具javap来进行查看时,发现的确是主版本是52,然后第一个常量池类型就是MethodRef,然后再根据CONSTANT_Methodref_info类型进行逐步分析,详解参照:https://www.jianshu.com/p/d8492e748c57
3、访问标志
在常量池结束之后,紧接着两个字节代表访问标志,该标志用于识别一些类或者接口层次的访问信息,包括该类是类还是接口;是否定义为public类型;是否定义为abstract类型;如果是类,是否被声明为final类。
| 标志名 |
标志值 |
标志含义 |
针对的对像 |
| ACC_PUBLIC |
0x0001 |
是否为public类型 |
所有类型 |
| ACC_FINAL |
0x0010 |
是否为final类型 |
类 |
| ACC_SUPER |
0x0020 |
是否使用新的invokespecial语义,JDK1.0.2之后编译的都为真 |
类和接口 |
| ACC_INTERFACE |
0x0200 |
标识为接口类型 |
接口 |
| ACC_ABSTRACT |
0x0400 |
标识为抽象类型 |
类和接口 |
| ACC_SYNTHETIC |
0x1000 |
标识为该类不由用户代码生成 |
所有类型 |
| ACC_ANNOTATION |
0x2000 |
标识为注解类型 |
注解 |
| ACC_ENUM |
0x4000 |
标识为枚举类型 |
枚举 |
以TestClass为例,TestClass是一个普通的类,不是接口、枚举或者注解,被public关键字修饰但没有被声明为final和abstract,因此ACC_PUBLIC和ACC_SUPER为真,所以access_flags的值为:0x0001|0x0020=0x0021。
4、类索引、父类索引与接口索引集合
类索引和父类索引都是一个u2类型数据,而接口索引则是一组u2类型数据的集合。Class文件中就由这三项数据来确定这个类的继承关系。
类索引用于确定这个类的全限定名,父类索引用于确定这个类的父类的全限定名,由于Java的单继承,父类索引只有一个,除了Object类外,所有的Java类都有父类,所有的Java的父类索引都不为0。接口索引用于描述该类实现了哪些接口,这个被实现的接口将按implement语句后的接口顺序从左至右排列在接口索引集合中。
类索引、父类索引与接口索引都按顺序排列在访问标志之后,类索引和父类索引用两个u2类型的索引值表示,各自指向一个类型为CONSTANT_Class_info的类描述常量。
5、字段表集合
6、方法表集合
7、属性表集合