Fiddler2 抓包工具,让你的信息无处可藏

本文来自作者 极笔北客 在 GitChat 上分享 「Fiddler2 抓包工具,让你的信息无处可藏」,「阅读原文」查看交流实录。
「文末高能」
编辑 | 哈比
http 协议是互联网中应用最多的协议,几乎所有的 web 应用、移动应用都用的是 http 协议。
Fiddler2 作为一个基于 http 协议的免费抓包工具,功能十分强大,它能够捕获到通过 http 协议传输的数据包,让你的信息无处可藏。
本文将从 Fiddler2 下载安装、具体应用以及如何防止被抓包这几点来简单直白的进行讲解。
一、Fiddler2 名字后面为什么有个 2,而不叫做 Fiddler?

这虽然是个看似无聊的问题,但是确实让我纠结了好一阵子,可能有点强迫症吧。
最开始使用 Fiddler 的时候一直都是 Fiddler2 这样写着,也是这样叫着,结果有一天发现还有个 Fiddler4,瞬间就明白怎么回事了,原来数字 2 并不是 Fiddler 名字的一部分,而是一个大版本号。
但是在全网搜了半天,包括去官网,都没找到 Fiddler3,目前为止最新的还是 Fiddler4,全网使用的最多的也是 Fiddler2 和 Fiddler4,至于 Fiddler 和 Fiddler3 为什么没有,也懒得去找了。
二、Fiddler 的本质是服务器的代理

启动 Fiddler 后,Fiddler 会默认以 127.0.0.1:8888 的地址和端口代理当前电脑或者服务器,所以发送到当前电脑或者服务器的 http 请求,都会先经过 127.0.0.1:8888 这个代理地址,然后在转发到真实的访问地址。
Fiddler 就相当于在客户端与服务端中间安装了一个中转器,这个中转器负责转发。那么,Fiddler 拿到客户端与服务器之间交互数据后,通过数据整理分析,将结果从 Fiddler 客户端展示出来,甚至可以通过 Fiddler 来修改请求数据。
当关闭 Fiddler 的时候,Fiddler 会自动注销代理。这就是 Fiddler 实现抓包的基本原理。
三、Fiddler 的下载和安装
可以通过地址 https://www.telerik.com/download/fiddler 来下载 Fiddler 的客户端。

随便选择一个使用理由,输入邮箱地址,勾选 “I accept the Fiddler End User License Agreement” 选项,点击下载。

下载后的安装包:

一路下一步即可安装完成,目前最新版是 Fiddler4。
四、用 Fiddler 抓取基于 http 协议的 web 网站数据

打开 Fiddler,整个界面分为三个区块,区块 1 是当前电脑与外网交互的地址信息,有请求结果,请求协议,访问域名,url 地址,以及返回的字节数等登。
区块 2 是请求信息,包括 header 头部信息,请求地址,请求参数等等,区块 3 是服务器响应信息。根据返回结果形式的不同,可以分为返回网页和返回数据两种。
返回结果是 HTML 网页
我们以访问 gitchat.cn 热门 chat 为例进行分析。

从图中可以看到,host 列表示访问的域名,这里是 gitchat.cn,Protocol 列表显示的是协议,这里是 http,URL 列显示的是请求路径,这里是 /gitchat/hot,Body 列表示返回的结果字节数,Content-Type 列表示返回内容的类型,这里是 html,最后 Process 列意思是进程名。
一般情况下,我们只需要关注 Host、URL、Body 及 Content-Type 这几列,从 Body 列的字节大小,我们能快速判断出哪些请求有大量的数据返回,再根据 Content-Type 判断返回内容的类型。
上图标红的行中,我们可以看到热门列表页有大量的内容返回,并且返回类型是 html 网页。我们看下区块 3 的结果。

我们切到 “SyntaxView” 页签下,可以看到热门 chat 的 html 页面源码,说明请求 http://gitbook.cn/gitchat/hot 这个地址之后,服务器返回的是 html。
返回结果是数据

我在访问百度网页的时候,发现红框标注的请求,有大量数据返回,并且返回类型是 “application/javascript”,于是查看了下返回结果,我们切到 “SyntaxView” 页签下,可以看到一堆可识别的数据,如下:

我们选择以 “JSON” 的格式查看,如下:
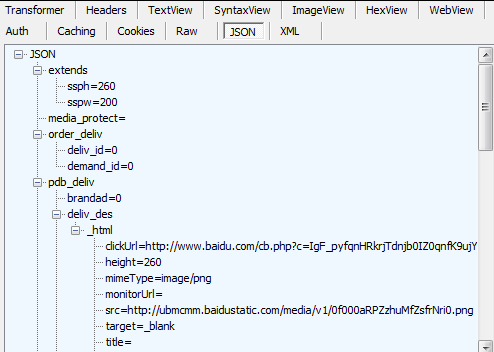
一般情况下,我们用 Fiddler 抓包是处在一种目标不是非常明确的情况下, 也就是说我们不知道这个网站的哪个地址会被抓到数据,也不知道会被抓到什么数据,只是在浏览这个网站的过程中,通过 Fiddler 的请求情况来分析,哪些数据可能有用。
这些数据往往是在网站或者 APP 上正常操作时看不到的数据,而通过 Fiddler 的抓取,就能捕获到这些隐藏的数据。
Fiddler 还常常被用作爬虫的辅助工具,先用 Fiddler 过滤一遍目标网站或者 APP,捕获到能够拿到目标数据的 URL 及参数,然后再通过爬虫程序访问这些 URL 及参数,就可以爬到目标数据。
一般通过接口返回数据的情况多见与 APP,比如这个链接 “http://shipper.huodada.com/freight/findByPage.shtml?startDistrict=&endDistrict=&rows=400&page=1&sidx=update_time&sord=desc” 就是通过爬取某 APP 拿到的数据接口,直接访问这个链接,可以看到 JSON 格式的数据源。

五、用 Fiddler 抓取基于 https 协议的新浪微博
Fiddler 除了可以抓取 http 协议的数据外,同时也可以抓取 https 协议的数据,只是需要做额外的配置,方法如下:
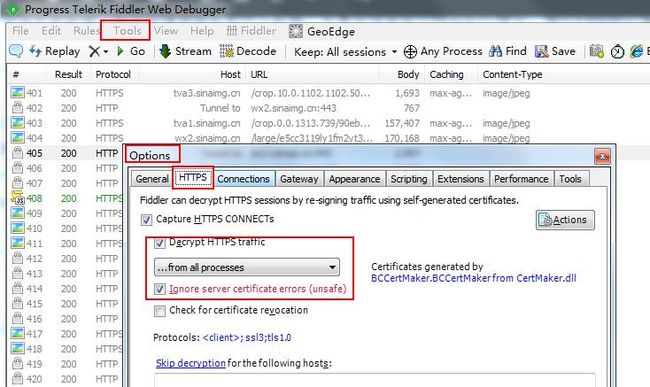
依次打开菜单栏的 Tools》Options》HTTPS 标签,勾选 “Decrypt HTTPS traffic” 选项和 “Ignore server certificate errors(unsafe)” 选项,重启 Fiddler。这个时候访问基于 https 协议的网站,就能抓取到该网站的信息,我们以新浪微博为例。

可以看到,抓到的大部分都是图片,其中有一条返回 2907 个字节的应该不是,我们看下返回结果。

从备注看,这应该是服务器的某些证书信息。我们再看下有哪些图片。
张一山?

极光之恋?

奇门遁甲?
当然,这些照片都是新浪微博首页的照片,想看的话直接去首页,不用费劲用 Fiddler 抓取,这里只是做说明举例而已,掌握了抓取 https 协议数据的方法,能看网页显示出来的数据,当然也就能看网页显示不出来的隐藏数据,这个就靠个人发挥了。
刀法已经交给你了,至于你是用来杀猪还是用来行侠仗义,你自己说了算。
六、用 Fiddler 抓取手机 APP 的通讯数据
抓取手机的通讯数据,需要在 Fiddler 和手机端同时进行配置,过程稍微复杂一些,下面我详细说明。
第一步,配置 Fiddler 允许远程连接,如图:

依次打开菜单栏的 Tools》Options》Connctions 标签,勾选 “Allow remote computers to connect” 选项,允许远程服务器连接,重启 Fiddler。
第二步,在手机端将安装 Fiddler 的电脑设置为手机的代理地址。
找到手机已经连接的 wifi 网络,点击后弹出修改,在高级代理中找到代理设置,将代理设置改为手动,这时会显示设置代理地址及端口的输入框(不同的手机操作过程稍微会有些差异,最终的目的都是设置手机的代理地址,可以根据不同品牌型号的手机在百度搜索相关设置方法)。

设置代理地址。

代理地址是你打开 Fiddler 的这台电脑的内网 IP 地址,window 系统可以在 cmd 命令模式下输入 ipconfig,查看当前电脑的内网 IP 地址。我的电脑 IP 地址是 192.168.1.34。
代理端口填写 8888,点击保存,如下图:

第三步,访问代理地址,下载并安装证书,完成配置。

下载并安装证书:

至此,所有的配置完成。现在,通过手机与外网通讯的数据,都可以被 Fiddler 捕获了。例如,我们通过微信打开 gitchat 的微信公众号,在 Fiddler 中就可以看到 gitchat 公众号的头条文章的图片数据,如图。
这是在 Fiddler 中捕获到的数据:
GitChat 微信公众号中的图文图片:

同样的,在网页中能够捕获到的数据,在 APP 上都能捕获到,甚至在 APP 上捕获到的隐藏数据会更多,因为大部分 APP 都是以接口的形式与服务器进行通讯的,接口中会包含大量数据,直接捕获到接口地址及参数,就可以直接调用接口获取数据。
本文主要讲解 Fiddler 的使用方法和场景,所以在举例中尽量避开敏感内容,Fiddler 是一把双刃剑,可以用来抓取合法的数据,同时也能用来抓取隐私数据,在使用中请大家一定要遵守规则。
七、用 Fiddler 设置断点修改 Response
Fiddler 不但可以用来捕获通讯数据,同时也可以用来修改请求内容以及服务器响应结果。此功能一般用到的较少,而且一般都是做前段开发共能调试时用到,所以这里就简单说明下。
在菜单栏中,点击 rules->automatic Breakpoints-> 选择断点方式,方式有两种,一种是请求之前进入断点,i 中是服务器响应之后设置断点,其实就是对请求内容和服务器返回结果的两种情况设置断点。
比如我们选择了请求之前进入断点,这时我们一旦用浏览器访问某个页面,在请求发送出去后,会在 Fiddler 停留下来,这时可以更改请求中的数据,然后执行后续操作,这样服务器接收到的请求就是修改过的。
同理,在服务器响应之后修改数据,就是直接修改了服务器的返回结果。
这块技巧在实际中用的比较少,如果有人对这块感兴趣,可以在评论中提出,我会在后面的交流中详细讲解这块内容。
八、关于反 Fiddler 抓取的几点思考
由于 Fiddler 的功能非常强大,所以我们在做产品开发时,要尽量的规避 Fiddler 的抓取,尤其是 APP 与服务器通讯时,更要注意接口的严谨性和安全性。可以考虑从以下几点入手:
在做 APP 接口时,与接口通讯的数据尽量进行加密后再传输,不要采用明文,这样会从很大程度上避免被抓取数据;
接口返回的数据尽量少,也就是 APP 需要哪些数据就只返回哪些数据,不要因为偷懒将所有数据返回,这样一旦数据被抓取,就会泄露不止当前接口业务的数据;
参数一定要做严格验证,避免有人恶意猜测构造参数,非法访问服务器。
本次关于 Fiddler 数据抓取的话题就到这里,有疑问的同学可以留言提问,也可以在读着圈提问,我看到后会尽量在第一时间回复大家。感谢大家的参与。
九、注意事项
用 Fiddler 抓取网页传输数据的时候,经常有人遇到无法抓取的问题,尤其是 https 协议的网站,在 Fiddler 上数据根本就不显示。
经过反复地尝试,我发现问题出在浏览器上,有些浏览器可能对代理做了屏蔽,通过这些浏览器访问的网页,不会在 Fiddler 上显示数据,感觉像是代理失效了一样。
目前测试发现,360 浏览器百分百的屏蔽 Fiddler,谷歌浏览器会屏蔽一部分,具体的屏蔽规则是什么还没做深入研究。另外,IE 浏览器全面支持 Fiddler,几乎没做任何屏蔽,上面示例中的数据抓取,我都是通过 IE 浏览器做的演示。
所以在实际使用中,建议优先使用 IE 浏览器来抓取数据。
近期热文
《敏捷教练 V 形六步法实战:从布朗运动到深度协作》
《从零开始,搭建 AI 音箱 Alexa 语音服务》
《修改订单金额!?0.01 元购买 iPhoneX?| Web谈逻辑漏洞》
《让你一场 Chat 学会 Git》
《接口测试工具 Postman 使用实践》
《如何基于 Redis 构建应用程序组件》
《深度学习在摄影技术中的应用与发展》

「阅读原文」看交流实录,你想知道的都在这里