0481-如何从HDP2.6.5原地升级到CDH6.0.1
温馨提示:如果使用电脑查看图片不清晰,可以使用手机打开文章单击文中的图片放大查看高清原图。
Fayson的github:
https://github.com/fayson/cdhproject
提示:代码块部分可以左右滑动查看噢
1
文档编写目的
编写本文主要是因为Fayson在上篇文章《0480-如何从HDP2.6.5原地迁移到CDH5.16.1》迁移失败的补充,为什么迁移失败是因为HDP2.6.5的Hadoop版本2.7.5比C5的2.6要高导致的,HDFS只支持升级,而不支持降级。
- 内容概述
1.测试环境说明
2.保存相关元数据
3.停止HDP和Ambari服务
4.卸载Ambari和HDP
5.安装Cloudera Manager
6.安装CDH
7.其他问题
- 测试环境
1.HDP2.6.5
2.Ambari2.6.2.2
3.CDH6.0.1
4.Redhat7.4
5.集群未启用Kerberos
6.采用root用户操作
2
测试环境说明
1.测试环境具体见上篇文章《0480-如何从HDP2.6.5原地迁移到CDH5.16.1》,这里不再进行说明。
2.比较HDP2.6.5和CDH5.16.1的组件版本
| HDP2.6.5 | CDH6.0.1 |
|---|---|
| Hadoop2.7.3 | Hadoop3.0 |
| Hive1.2.1 | Hive2.1.1 |
| HBase1.1.2 | HBase2.0 |
3
卸载CDH5.16.1
因为上篇文章已经安装了CM/CDH5.16.1,要重新安装CDH6需要先卸载,卸载过程略,具体参考Fayson之前的文章《如何卸载CDH(附一键卸载github源码)》
4
安装Cloudera Manger
安装过程略,参考Fayson之前的文章《如何在Redhat7.4安装CDH6.0》。安装成功后直接登录Cloudera Manager。
5
安装CDH
该步骤略过。如何安装CDH依旧可以参考Fayson之前的文章《如何在Redhat7.4安装CDH6.0》。最关键需要注意2点:
1.选择各个组件的相关角色的节点时请务必注意:
NameNode/HMaster与原HDP集群时一致:ip-172-31-4-109.ap-southeast-1.compute.internal
DataNode/RegionServer与原HDP集群时一致:ip-172-31-12-114.ap-southeast-1.compute.internal,ip-172-31-13-13.ap-southeast-1.compute.internal,ip-172-31-1-163.ap-southeast-1.compute.internal
Secondary NameNode与原HDP集群时一致:ip-172-31-12-114.ap-southeast-1.compute.internal
2.集群的关键参数配置,注意这里需要修改对应到之前HDP集群时的配置:
hbase.rootdir为/apps/hbase/data
dfs.datanode.data.dir为/hadoop/hdfs/data
dfs.namenode.name.dir为/hadoop/hdfs/namenode
dfs.namenode.checkpoint.dir为/hadoop/hdfs/namesecondary
具体参考《0480-如何从HDP2.6.5原地迁移到CDH5.16.1》
6
组件升级
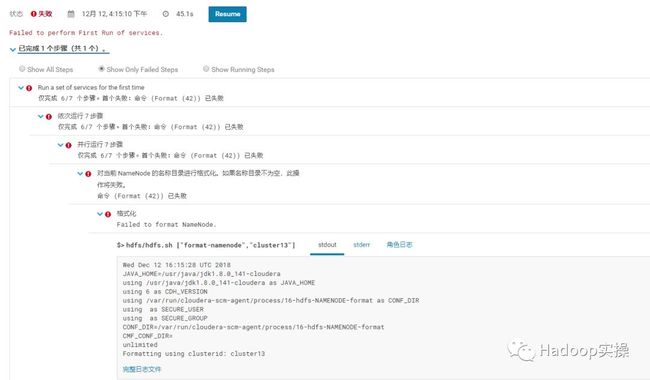
1.根据上线章节完成安装CDH后在启动各项服务时依旧会报错如下
2.不用管这个报错,直接点右上角Cloudera图标进入主页
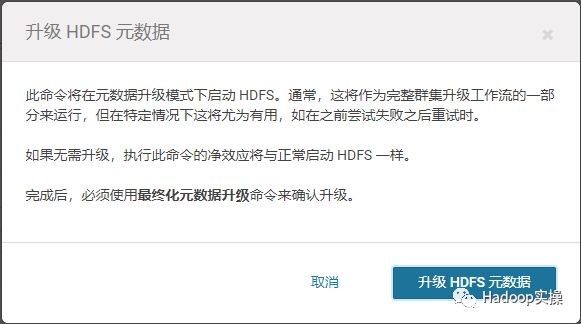
3.进入HDFS服务,点击配置,选择“升级HDFS元数据”

4.点击“升级HDFS元数据”
5.等待元数据升级成功,并且成功启动服务
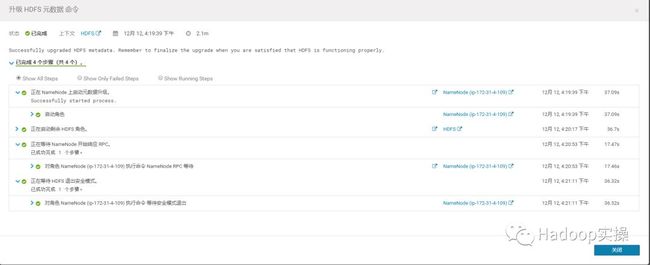
6.从HDFS服务进入NameNode页面
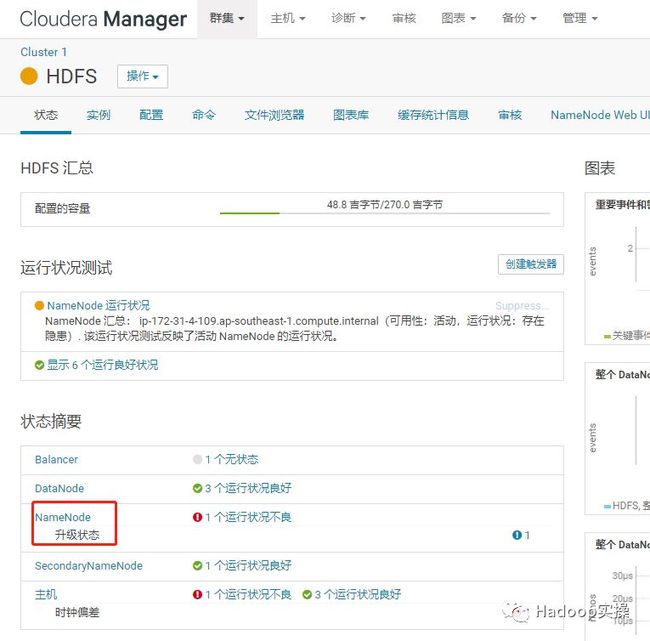
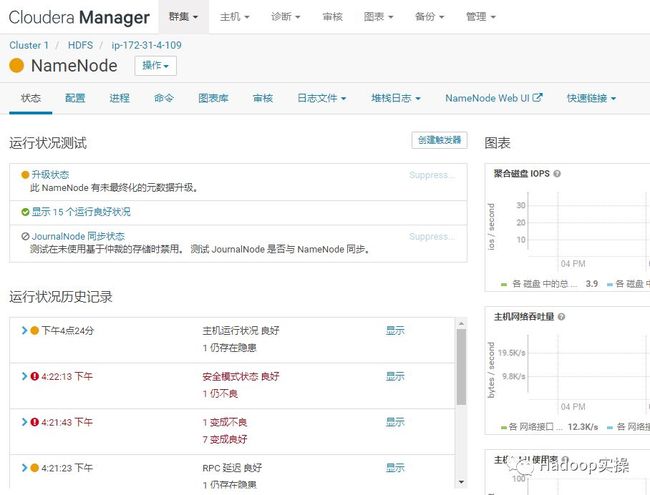
7.选择最终化元数据升级
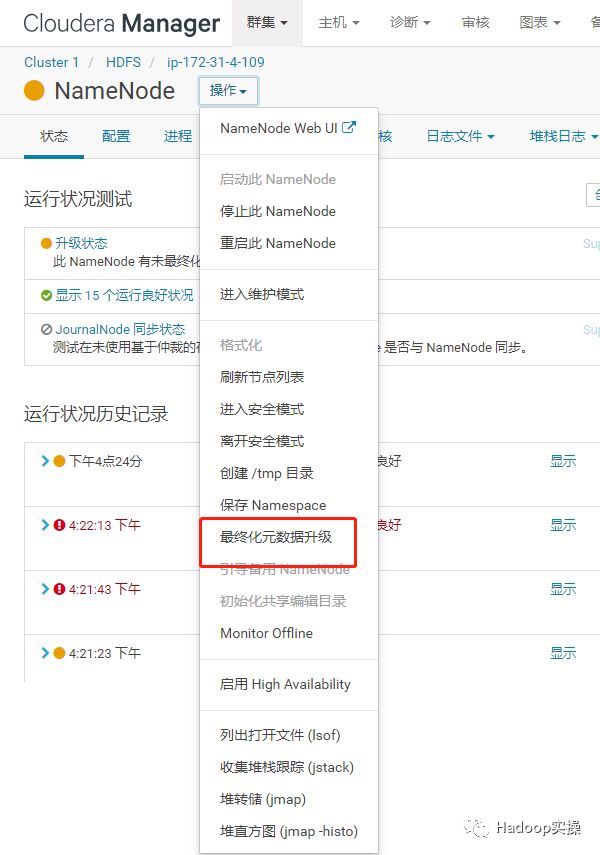
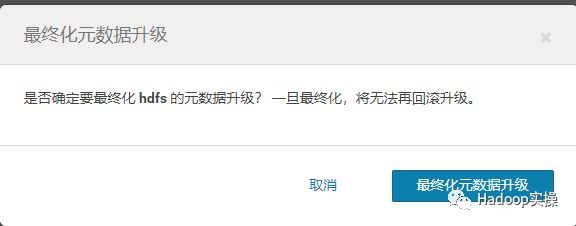
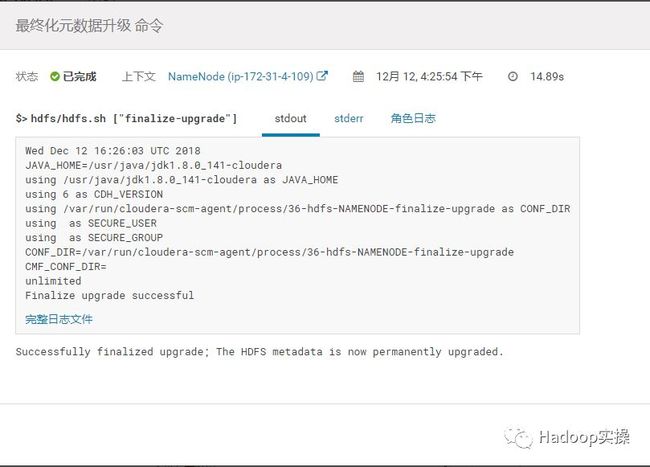
8.等待最终化元数据升级完成
7
HDFS校验
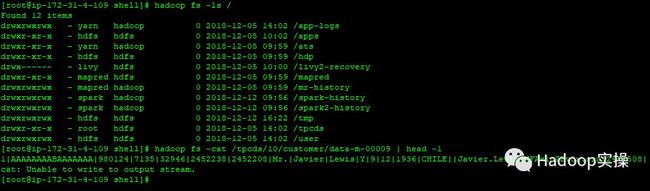
1.执行以下命令表明HDFS工作正常,并且旧的数据能够正常访问
[root@ip-172-31-4-109 shell]# hadoop fs -ls /
[root@ip-172-31-4-109 shell]# hadoop fs -cat /tpcds/10/customer/data-m-00009 | head -1
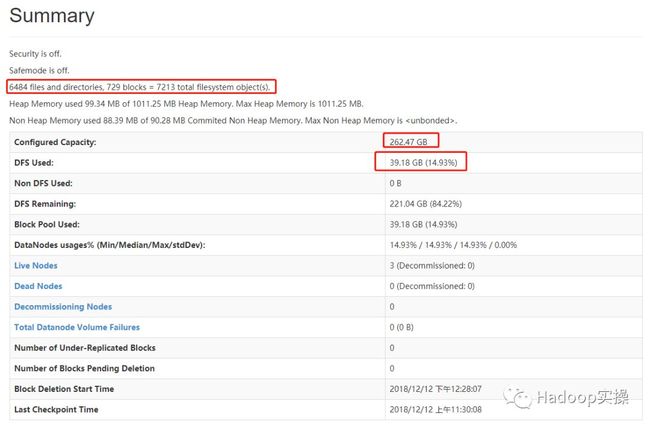
2.查看HDFS的50070页面如下
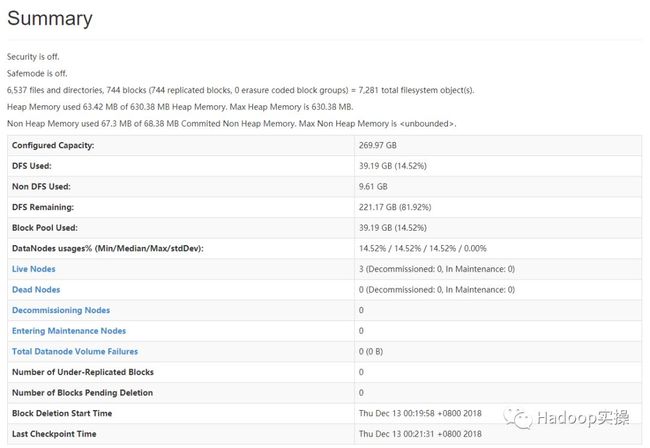
与升级前HDP的50070有些微差别,忽略不理。
8
Hive升级
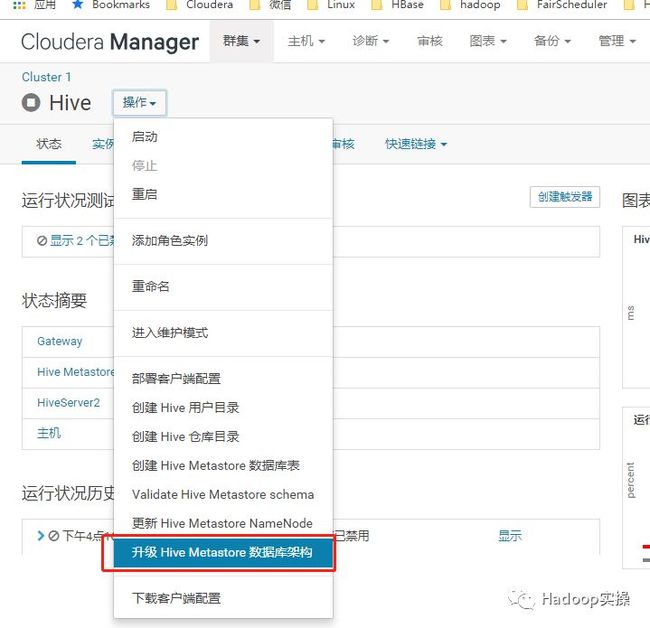
1.选择Hive服务,点击操作选择“升级Hive Metastore数据库架构”

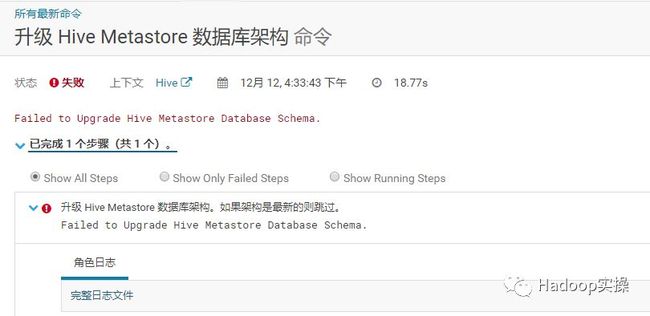
2.升级失败

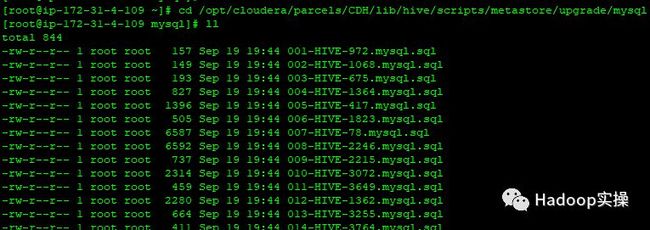
3.自动升级,我们进入Cloudera官方提供的Hive元数据升级目录
[root@ip-172-31-4-109 ~]# cd /opt/cloudera/parcels/CDH/lib/hive/scripts/metastore/upgrade/mysql

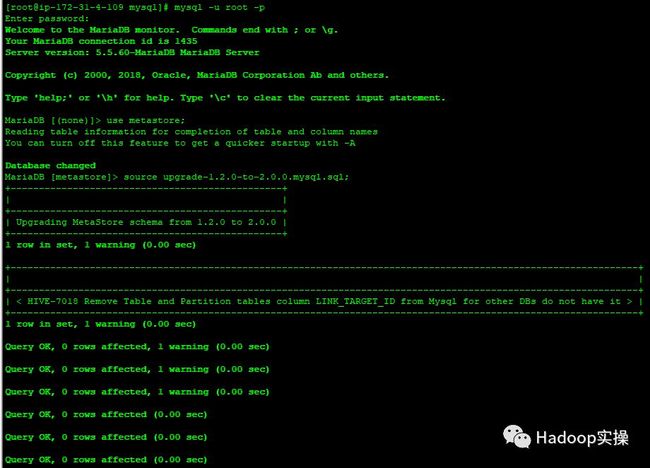
4.我们知道HDP2.6.5的Hive是1.2,所以我们使用以下命令来逐步进行升级
[root@ip-172-31-4-109 mysql]# mysql -u root -p
Enter password:
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MariaDB connection id is 1413
Server version: 5.5.60-MariaDB MariaDB Server
MariaDB [metastore]> source upgrade-1.2.0-to-2.0.0.mysql.sql;
MariaDB [metastore]> source upgrade-2.0.0-to-2.1.0.mysql.sql;

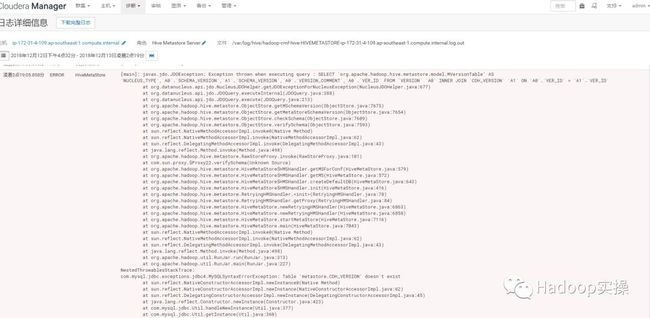
5.去界面上启动HMS以及HiveSever2后执行Hive命令会报错如下:

查看HMS的日志如下:
凌晨2点19:05.858分 ERROR HiveMetaStore
[main]: javax.jdo.JDOException: Exception thrown when executing query : SELECT 'org.apache.hadoop.hive.metastore.model.MVersionTable' AS `NUCLEUS_TYPE`,`A0`.`SCHEMA_VERSION`,`A1`.`SCHEMA_VERSION`,`A0`.`VERSION_COMMENT`,`A0`.`VER_ID` FROM `VERSION` `A0` INNER JOIN `CDH_VERSION` `A1` ON `A0`.`VER_ID` = `A1`.`VER_ID`
at org.datanucleus.api.jdo.NucleusJDOHelper.getJDOExceptionForNucleusException(NucleusJDOHelper.java:677)
at org.datanucleus.api.jdo.JDOQuery.executeInternal(JDOQuery.java:388)
at org.datanucleus.api.jdo.JDOQuery.execute(JDOQuery.java:213)
at org.apache.hadoop.hive.metastore.ObjectStore.getMSchemaVersion(ObjectStore.java:7675)
at org.apache.hadoop.hive.metastore.ObjectStore.getMetaStoreSchemaVersion(ObjectStore.java:7654)
at org.apache.hadoop.hive.metastore.ObjectStore.checkSchema(ObjectStore.java:7609)
at org.apache.hadoop.hive.metastore.ObjectStore.verifySchema(ObjectStore.java:7593)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.hive.metastore.RawStoreProxy.invoke(RawStoreProxy.java:101)
at com.sun.proxy.$Proxy22.verifySchema(Unknown Source)
at org.apache.hadoop.hive.metastore.HiveMetaStore$HMSHandler.getMSForConf(HiveMetaStore.java:579)
at org.apache.hadoop.hive.metastore.HiveMetaStore$HMSHandler.getMS(HiveMetaStore.java:572)
at org.apache.hadoop.hive.metastore.HiveMetaStore$HMSHandler.createDefaultDB(HiveMetaStore.java:643)
at org.apache.hadoop.hive.metastore.HiveMetaStore$HMSHandler.init(HiveMetaStore.java:416)
at org.apache.hadoop.hive.metastore.RetryingHMSHandler.<init>(RetryingHMSHandler.java:78)
at org.apache.hadoop.hive.metastore.RetryingHMSHandler.getProxy(RetryingHMSHandler.java:84)
at org.apache.hadoop.hive.metastore.HiveMetaStore.newRetryingHMSHandler(HiveMetaStore.java:6863)
at org.apache.hadoop.hive.metastore.HiveMetaStore.newRetryingHMSHandler(HiveMetaStore.java:6858)
at org.apache.hadoop.hive.metastore.HiveMetaStore.startMetaStore(HiveMetaStore.java:7116)
at org.apache.hadoop.hive.metastore.HiveMetaStore.main(HiveMetaStore.java:7043)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.util.RunJar.run(RunJar.java:313)
at org.apache.hadoop.util.RunJar.main(RunJar.java:227)
NestedThrowablesStackTrace:
com.mysql.jdbc.exceptions.jdbc4.MySQLSyntaxErrorException: Table 'metastore.CDH_VERSION' doesn't exist
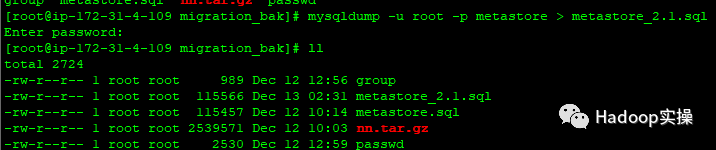
6.换个思路,我们先从mysql里导出已经升级到2.1的metastore数据,然后新建一个空的metastore的database,然后使用CM的Hive服务的“创建Hive Metastore数据库表”功能
导出新的metastore数据库数据:
[root@ip-172-31-4-109 migration_bak]# mysqldump -u root -p metastore > metastore_2.1.sql
Enter password:
去mysql里drop掉metastore数据库并新建

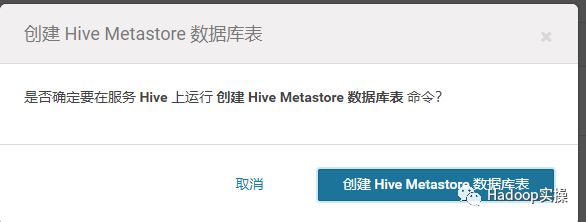
从Cloudera Manager里“创建HiveMetastore数据库表”,注意需要先停止Hive服务。
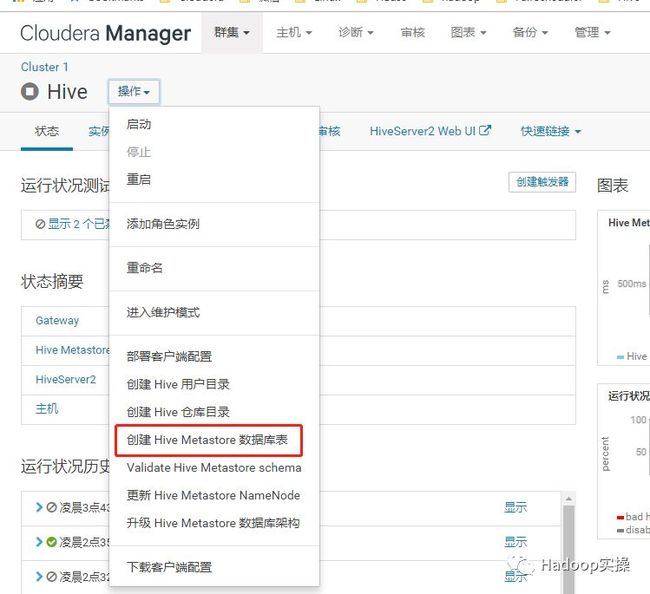
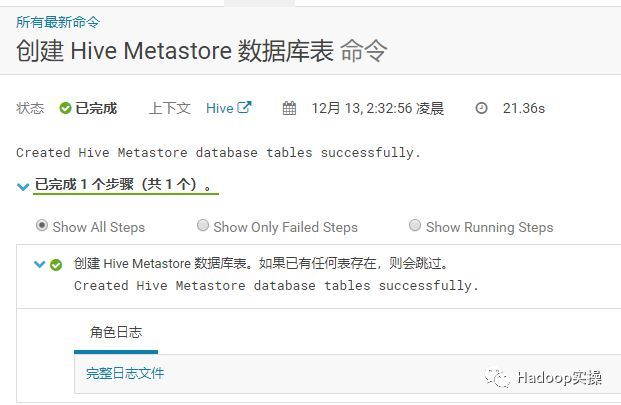
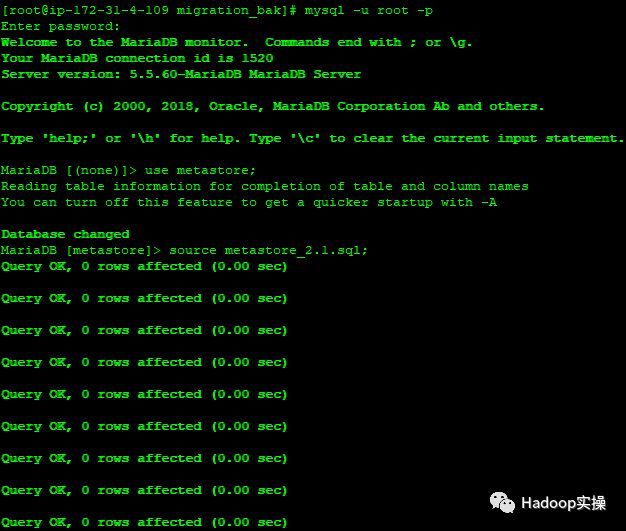
再次导入之前导出来的metastore数据文件到这个由Cloudera Manager自己创建的Hive元数据库中。
MariaDB [metastore]> source metastore_2.1.sql;
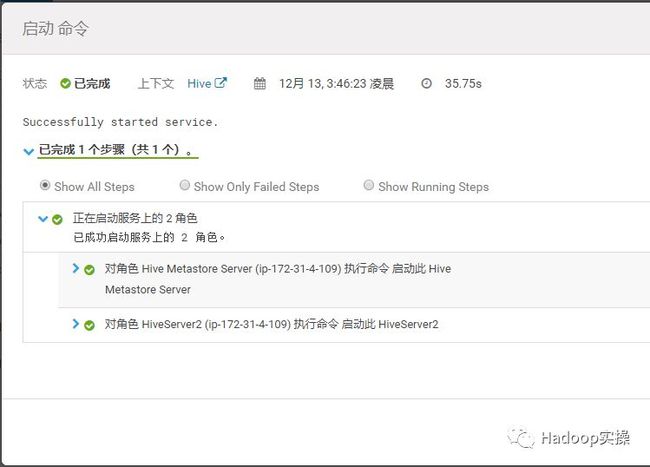
7.启动Hive服务,并且使用Hive命令查看相关的数据库和表
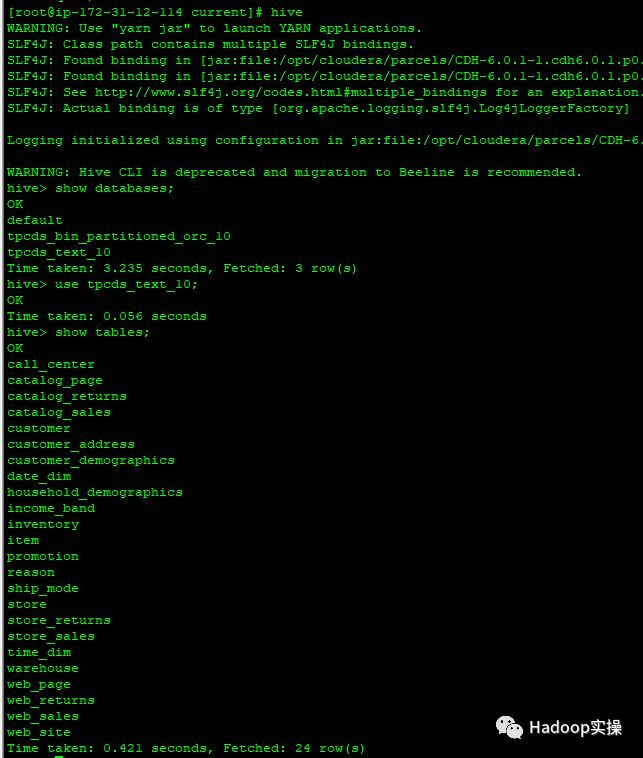
8.进行hive查询,MapReduce任务报错
18/12/13 03:49:24 INFO client.RMProxy: Connecting to ResourceManager at ip-172-31-4-109.ap-southeast-1.compute.internal/172.31.4.109:8032
java.io.FileNotFoundException: File does not exist: hdfs://ip-172-31-4-109.ap-southeast-1.compute.internal:8020/user/yarn/mapreduce/mr-framework/3.0.0-cdh6.0.1-mr-framework.tar.gz
at org.apache.hadoop.fs.Hdfs.getFileStatus(Hdfs.java:145)
at org.apache.hadoop.fs.AbstractFileSystem.resolvePath(AbstractFileSystem.java:488)
at org.apache.hadoop.fs.FileContext$25.next(FileContext.java:2225)
at org.apache.hadoop.fs.FileContext$25.next(FileContext.java:2221)
at org.apache.hadoop.fs.FSLinkResolver.resolve(FSLinkResolver.java:90)

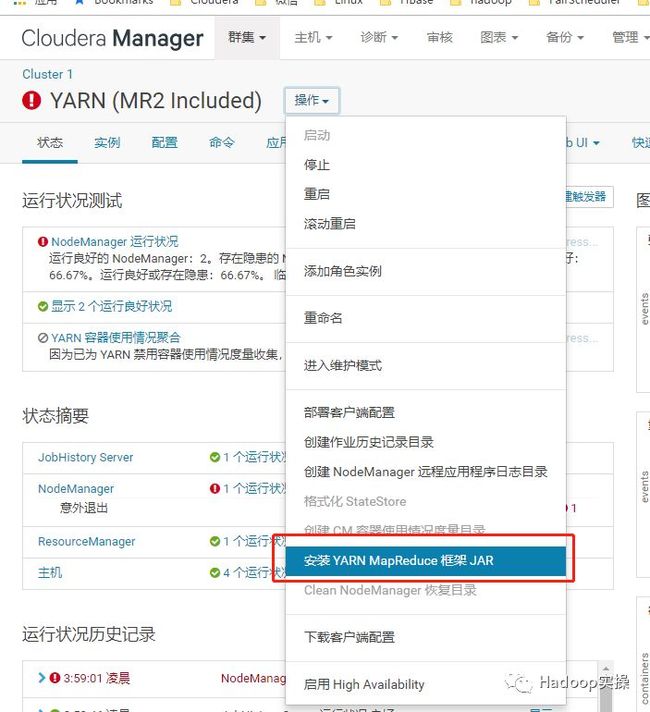
9.从Cloudera Manager页面启动YARN服务,步骤略。

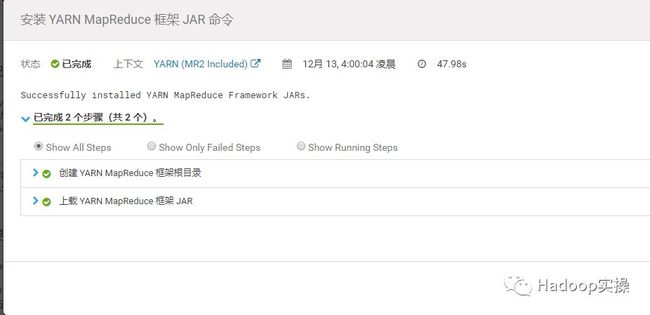
10.进入YARN服务,点击“安装YARN MapReduce框架jar”

11.再次运行Hive的MapReduce任务,这回执行成功
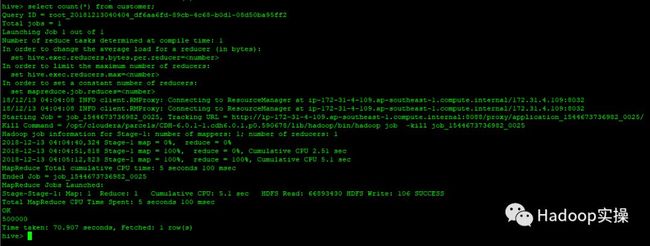
注意:这里Fayson其实也是跟HDP之前的Hive数据进行了一次随机校验,在上篇文章《0480-如何从HDP2.6.5原地迁移到CDH5.16.1》中的“2.测试环境说明”章节有统计同一张表的条数,对于真实的迁移或者升级,你可能需要校验更多的项目,比如再次比较数据库或数据表的数量,多抽查几张表进行校验才能确保升级成功。这里时间关系,Fayson略过。
9
HBase升级
1.首先我们将HBase原始来自HDP的数据在HDFS备份一下:
[root@ip-172-31-4-109 ~]# hadoop fs -mkdir /hbase_bak
[root@ip-172-31-4-109 ~]# sudo -u hdfs hadoop fs -cp /apps/hbase /hbase_bak
![]()
2.从Cloudera Manager界面上启动HBase服务
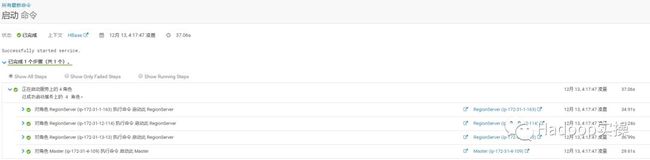
3.查询HBase的数据
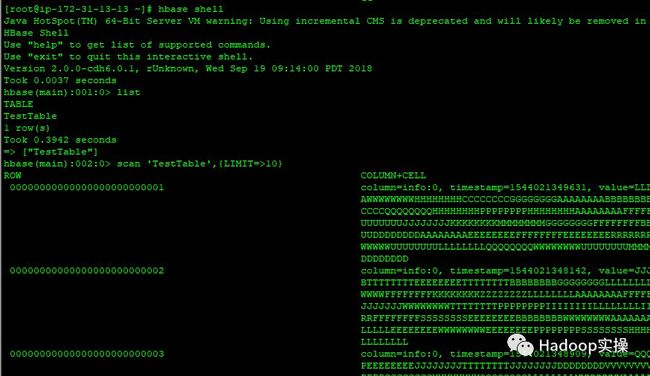
可以正常使用
4.查看HBase Master页面
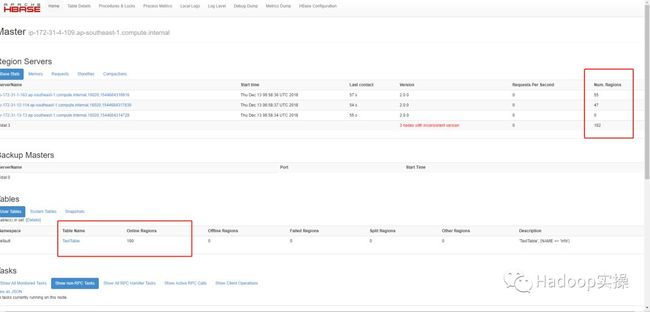
总region数量与原HDP平台的HBase一致。
10
总结
首先强调一下本次迁移只关注HDFS数据,Hive数据,HBase数据,对于以下内容并没办法保证从HDP到CDH的直接迁移,您需要新建或者进行更严格的测试:
1.用户认证如OpenLDAP,Kerberos,AD等,你需要在CDH中再次进行配置。
2.权限相关比如HDP中的Ranger授权策略,你只能在CDH中安装Sentry后再次进行配置,并没有方案指导你直接进行迁移。
3.本次迁移并不包括HDP中的Solr到CDH中的Solr迁移。
4.所有组件的配置项包括如HDFS,HBase,Hive,Spark等你需要在CDH中重新进行配置,最好在卸载HDP前能记录好一些关键配置。
5.从HDP迁移后,以前的Hive on Tez将不存在考虑使用Hive on MapReduce或者Impala来实现。
6.迁移成功后,你可能需要对以前的一些应用进行改造,包括Hive作业,HBase查询,Spark作业等。
查看以下内容前强烈建议你已经仔细阅读过Fayson之前的文章《0480-如何从HDP2.6.5原地迁移到CDH5.16.1》。
1.建议在做平台迁移之前,首先需要禁用掉HDFS的HA,主要是为了移除HDFS服务对Zookeeper的依赖,这样你在迁移到新平台后,Zookeeper可以重新安装而且不用额外配置。
2.如果旧的集群已经启用了Kerberos,最好也先禁用掉。等待迁移成功后,在新的平台再次启用Kerberos即可。
3.卸载旧的集群前,务必保证正常停止Hadoop集群服务。停止服务前确认Hive表,HBase,HDFS已经没有写入,然后让HDFS进入安全模式,保存检查点。
4.卸载旧的集群前务必备份好关键数据,包括NameNode的元数据,Hive的元数据库等。同时记录HDFS的空间使用情况,包括文件夹个数,文件大小,同时记录Hive的数据库,表的数量,可以可以抽样几个表的包括schema以及部分数据和总条数等方便后期做数据一致性比对。HBase的表同Hive表。
5.卸载旧的集群前务必记录几个关键的本地目录,包括NameNode元数据本地目录,DataNode本地目录,HBase在HDFS中的root目录。这3个目录在后期搭新的平台时都是保持不变与之前一致才能真正保证原地迁移成功。
6.请一定保证Ambari和HDP都已经完全卸载,否则可能会导致CDH无法正常安装。
7.安装新的CDH集群时务必保证关键角色所在节点跟以前HDP时一致,如NameNode,Secondary NameNode,DataNode和RegionServer。
8.首次运行新的集群的服务启动时,因为NameNode已有元数据,无法正常格式化,会启动失败,这是正常情况。
9.HDFS的升级分2个关键步骤,首先是在HDFS服务中“升级HDFS元数据”,然后到NameNode中点击“最终化元数据升级”,一旦元数据完成最终升级,将不能再次回滚,请务必注意操作风险,以及备份好了关键数据。
10.本次迁移升级到CDH6.0.1,Hive版本从HDP的1.2升级到2.1,直接在Cloudera Manager使用Hive的“升级元数据架构”失败,后来通过CDH提供的手动升级MySQL的数据库脚本先从Hive1.2升级到Hive2.0,再从Hive2.0升级到Hive2.1,启动HMS服务时依旧报错。替代解决方案是先从MySQL中升级了元数据到Hive2.1,导出metastore的数据,然后drop掉metastore数据库,然后新建metastore数据库,通过Cloudera Manager生成正确的metastore的schema,然后把前面导出的metastore数据重新导入到最新的metastore数据库中。
11.对于第10步的过程,时间关系,Fayson没来得及全部验证所有表是否可用,依旧存在部分表比如字段类型问题不能用的情况可能需要重新创建Hive表的。主要是因为HDP的Hive的元数据的schema跟CDH的schema不能完全兼容导致的,如果都是CDH,升级Hive元数据会简单很多。
12.我们知道HDP中建议使用的Hive表的文件是ORC,而在CDH中使用的是Parquet,这里存在以前的ORC的表在CDH中不能正常使用的情况,比如Impala不能运行,所以最终你可能需要将ORC表转化为Parquet格式。
13.从HDP的HBase1.1迁移到CDH的HBase2.0,并没有做额外的操作,HBase的表就可以直接使用了,这里还没来得及做更严格的验证。
最后再次强调上篇文章从HDP2.6.5迁移到CDH5.16.1的问题:
如果你的目标HDFS的layoutVersion低于已有的集群的版本号,将不能迁移成功,即你只能做HDFS的升级,而没办法做降级。
“Note also that downgrade and rollback are possible only after a rolling upgrade is started and before the upgrade is terminated. An upgrade can be terminated by either finalize, downgrade or rollback. Therefore, it may not be possible to perform rollback after finalize or downgrade, or to perform downgrade after finalize.
注意降级或者回滚只能发生在升级完成之前,降级或回滚HDFS版本一旦在最终化元数据升级成功后就不能执行”
参考:
https://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-hdfs/HdfsRollingUpgrade.html
提示:代码块部分可以左右滑动查看噢
为天地立心,为生民立命,为往圣继绝学,为万世开太平。
温馨提示:如果使用电脑查看图片不清晰,可以使用手机打开文章单击文中的图片放大查看高清原图。
推荐关注Hadoop实操,第一时间,分享更多Hadoop干货,欢迎转发和分享。