Pytorch(笔记8)--手写自己设计的神经网络
在训练过程中经常做的一件事儿,就是拿已有网络模型ResNet,DenseNet等迁移到自己的数据集进行finetune,之后调整各个层级的输入输出等,我们先拿经典的lenet来说如何用Pytorch实现一个网络模型。(本人推荐使用Jupyter,方便调试,也可以保存成脚本)
- 添加依赖库
import torch
import torch.nn as nn
import torchvision as tv
import torch.nn.functional as F自定义的网络模版如下,继承抽象类nn.Module,并实现自己的方法
class Lenet5(nn.Module):
def __init__(self):
super(Lenet5,self).__init__()
...
def forward(self,x):
...一般先完成构造函数部分,我们分析网络模型,i
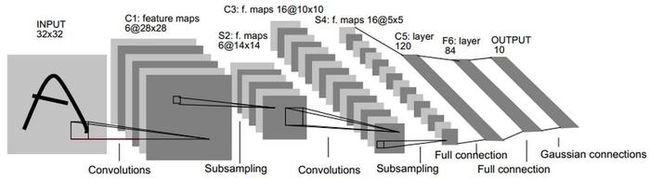
第1层,input是32*32这个大小不是固定的,可以根据自己的需求进行调整,对于mini数据集来说输入的是1dim的灰度图像[n,1,32,32],n代表batchsize,我们可以看到经过第一个Convolutions操作,变成了6个featureMap,size 变成了28*28,对于Conv2d(input_channel,out_channel,kernel_size,stride,padding)可以判断出out_channel 是6,stride = 1,尺寸的变化和kernel以及padding组合有关,这里我们假定padding=0 则:
self.conv1 = nn.Conv2d(in_channels=1,out_channels=6,kernel_size=5,stride=1,padding=0)
如果卷积运算不是很清楚,可以参考:Pytorch(笔记2)--Conv2d卷积运算
第2层,是一个Subsampling(下采样)操作,在Lenet(1994年)还没有Pooling操作,可能采用随机采样,或者top采样等方法,这里用Maxpooling操作做讲解,


tensor的尺寸从28到14,我们知道Pooling操作的kernel是2,stride 也是2 ,达到数量减半的效果
self.pool1 = nn.MaxPool2d(kernel_size=2,stride=2)
第5层,是一个拉平操作将16个5*5的feature拉平后进行全联接output是120
self.fc1 = nn.Linear(16*5*5,120)
分类器是一个简单的nn.Linear()结构,输入输出都是维度为一的值,x = x.view(x.size(0), -1) 这句话的出现就是为了将前面多维度的tensor展平成一维。
x = x.view(x.shape()[0] ,-1)
out = F.relu(self.fc1(x)) 其中nn.ReLU作为一个层结构,必须添加到nn.Module容器中才能使用,而F.ReLU则作为一个函数调用,看上去作为一个函数调用更方便更简洁。具体使用哪种方式,取决于编程风格。在PyTorch中,nn.X都有对应的函数版本F.X,但是并不是所有的F.X均可以用于forward或其它代码段中,因为当网络模型训练完毕时,在存储model时,在forward中的F.X函数中的参数是无法保存的。也就是说,在forward中,使用的F.X函数一般均没有状态参数,比如F.ReLU,F.avg_pool2d等,均没有参数,它们可以用在任何代码片段中。
至于ReLU的应用场景,只能用于隐藏层,位置没有明确规定,根据经验一般是Conv,ReLU,Maxpool2d,batch norm 进行组合使用,我们可以写出最终网络代码如下
class Lenet5(nn.Module):
def __init__(self):
super(Lenet5,self).__init__()
self.conv1 = nn.Conv2d(in_channels=1,out_channels=6,kernel_size=5,stride=1,padding=0)
self.pool1 = nn.MaxPool2d(kernel_size=2,stride=2)
#self.conv2 = nn.Conv2d(in_channels=6,out_channels=18,kernel_size=5,stride=1,padding=0) 等价于
self.conv2 = nn.Conv2d(6,16,5)
self.pool2 = nn.MaxPool2d(2,2)
self.fc1 = nn.Linear(16*5*5,120)
self.fc2 = nn.Linear(120,84)
self.fc3 = nn.Linear(84,10)
def forward(self,x):
x = self.pool1(F.relu(self.conv1(x)))
print x.shape
x = self.pool2(F.relu(self.conv2(x)))
print x.shape
x = x.view(x.size()[0],-1)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x) #输出结果一般不使用relu激活
return x
net = Lenet5()
print net网络如下:通常顺序是 conv-activation-pooling, 激活一定要在conv后面,卷积操作相当于wx+b,一般都是wx+b之后就进行激活运算,也就是σ(wx+b),所以卷积之后紧跟着激活。但是Pooling和activation的顺序没有明确的说法,大家可以评经验来设定,也可以多参考下别人的做法。
Lenet5(
(conv1): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1))
(pool1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))
(pool2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(fc1): Linear(in_features=400, out_features=120, bias=True)
(fc2): Linear(in_features=120, out_features=84, bias=True)
(fc3): Linear(in_features=84, out_features=10, bias=True)
)数据测试:
x = torch.rand(1,1,32,32)
net = Lenet5()
out = net(x)
print out
torch.Size([1, 6, 14, 14])
torch.Size([1, 16, 5, 5])
tensor([[-0.1065, -0.0217, 0.0291, -0.0461, 0.0503, -0.0272, 0.1086, -0.1100,
0.1168, 0.0145]], grad_fn=) 坚持一件事或许很难,但坚持下来一定很酷!^_^