读论文:Feedback Network for Image Super-Resolution
源码:https://github.com/Paper99/SRFBN_CVPR19
1 介绍
(1)基于深度学习的方法的优势主要来自其两个关键因素:深度和跳跃链接
第一,保留更多的上下文信息。
第二,防止堆叠导致的梯度消失/爆炸。
(2)减少网络参数,使用反复的结构,例如:DRCN和DRRN。RNN结构可以以前馈的方式共享信息,但是,即使采用了跳过连接,前馈方式也使得前一层无法从后一层访问有用的信息。
(3)本文主要贡献有以下三点:
●采用反馈机制,通过反馈连接在自上而下的反馈流中提供了高层信息 。同时,这种具有反馈连接的递归结构提供了强大的早期重建能力,并且仅需要很少的参数。
●提出了一个反馈块(FB),它不仅可以有效地处理反馈信息流,而且还可以通过上,下采样层以及密集的跳过连接来丰富高层表示。
●提出一种基于课程学习的策略,使网络能够逐步学习复杂的降级模型,而仅采用单步预测就无法用相同的策略来解决这些方法。
2 SRFBN
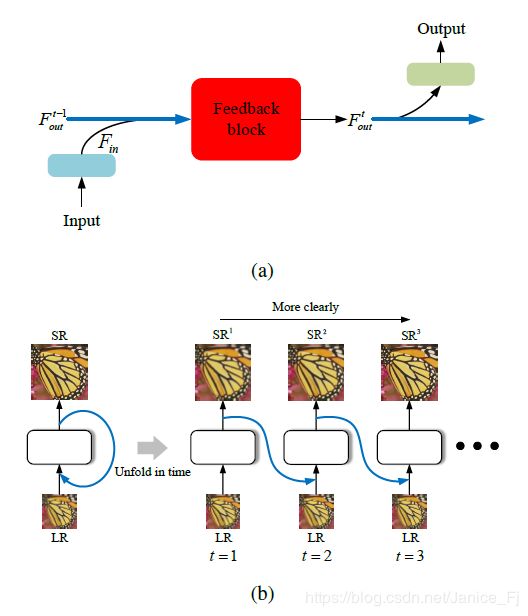
(a)反馈通过一次隐藏状态下的迭代,反馈块(FB)接受输入 F i n F_{in} Fin和来自上一层迭代隐藏状态的 F o u t n − 1 F^{n-1}_{out} Foutn−1,然后将其隐藏状态的 F o u t n F^{n}_{out} Foutn传递到下一个迭代并输出。
(b)本文反馈方案的原理。
2.1 网络结构
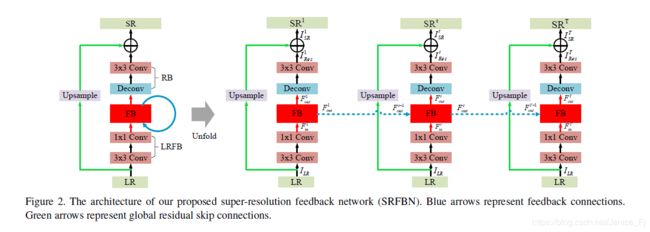
F i n t = f L R F B ( I L R ) F^t_{in}=f_{LRFB}(I_{LR}) Fint=fLRFB(ILR)
f L R F B f_{LRFB} fLRFB表示LR的特征提取块, F i n t F^t_{in} Fint被用作FB块的输入, F i n 1 F^1_{in} Fin1被视为初始隐藏状态的输出 F o u t 0 F^0_{out} Fout0。
第t个迭代的FB块
第t次迭代的FB通过反馈连接和浅层特征 F i n t F^t_{in} Fint接收前一层隐藏状态的迭代 F o u t n − 1 F^{n-1}_{out} Foutn−1, F o u t n F^{n}_{out} Foutn表示FB块的输出,FB块的算术公式如下:
F o u t n = f F B ( F o u t n − 1 , F i n t ) F^{n}_{out}=f_{FB}(F^{n-1}_{out},F^t_{in}) Foutn=fFB(Foutn−1,Fint)
f F B f_{FB} fFB表示FB块的操作,实际上是(b)图所示操作。
重建模块使用Deconv(k,m)将LR特征图 F o u t n F^{n}_{out} Foutn升频HR特征图,并使用Conv(3, c o u t c_{out} cout)去生成一个残差图像 I R e s t I^{t}_{Res} IRest,重建块的算术公式如下:
I R e s t = f R e s ( F o u t n ) I^{t}_{Res}=f_{Res}(F^{n}_{out}) IRest=fRes(Foutn)
f R e s f_{Res} fRes表示重建块的操作。

2.2 Feedback block
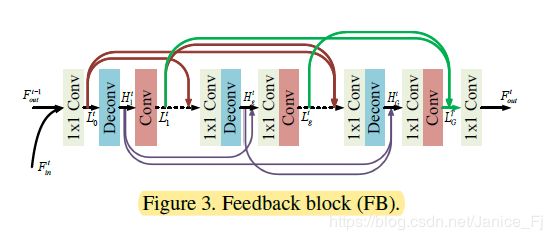
FB依次包含G个投影组,其中有密集的跳过连接。 每个可以将HR功能投影到LR功能的投影组,主要包括上采样操作和下采样操作。
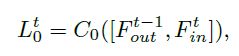
![]()
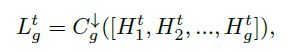
为了利用每个投影组的有用信息并在下一次迭代中映射输入LR特征 F i n t + 1 F^{t+1}_{in} Fint+1的大小,我们对投影组生成的LR特征进行特征融合(图3中的绿色箭头),以生成 FB的输出:
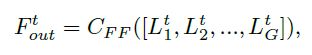
C F F C_{FF} CFF表示Conv(1,m)操作。
2.3 课程学习策略
放置T个目标HR图像 ( I H R 1 , I H R 2 , . . . , I H R T ) (I^1_{HR},I^2_{HR},...,I^T_{HR}) (IHR1,IHR2,...,IHRT)以适合我们提出的网络中的多个输出。
( I H R 1 , I H R 2 , . . . , I H R T ) (I^1_{HR},I^2_{HR},...,I^T_{HR}) (IHR1,IHR2,...,IHRT)对于单降解模型是相同的, 对于复杂的降级模型, ( I H R 1 , I H R 2 , . . . , I H R T ) (I^1_{HR},I^2_{HR},...,I^T_{HR}) (IHR1,IHR2,...,IHRT)根据T迭代执行课程的任务难度排序。 网络中的损失函数可以表示为:
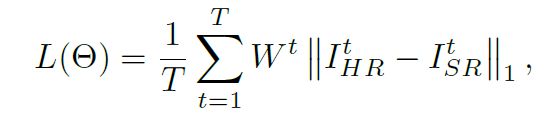
W t W_t Wt是一个常数因子,它表明了第t次迭代的输出价值。
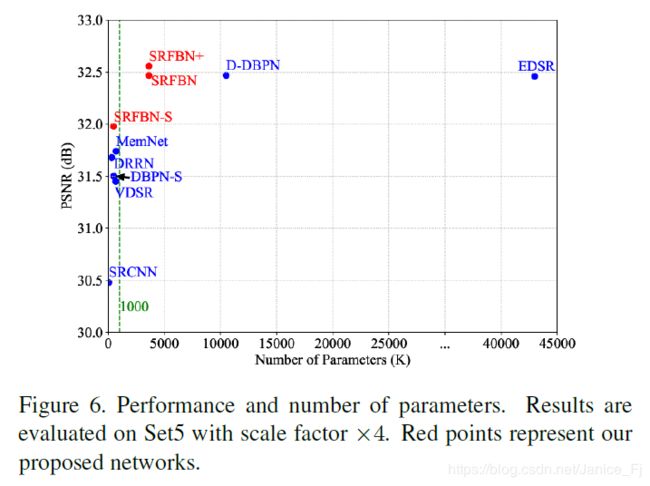
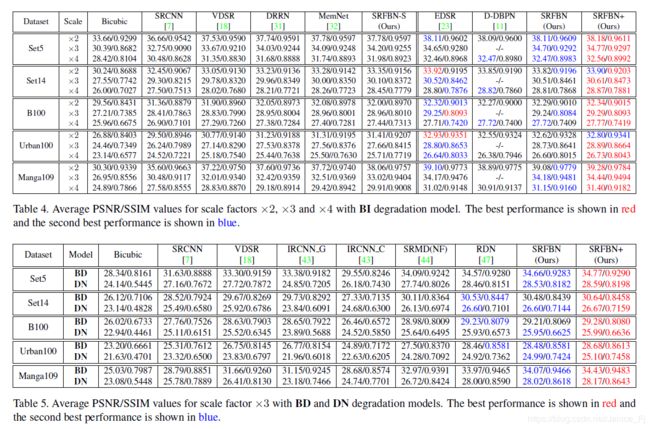
3 实验结果
(1)Study of T and G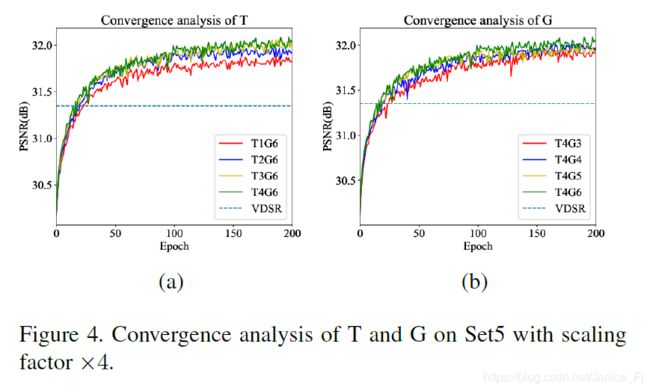
T表示迭代次数,G表示反馈块中的投影组数。最优(T=4, G=6)
(2)Feedback vs. feedforward
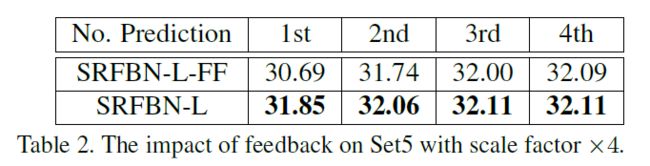
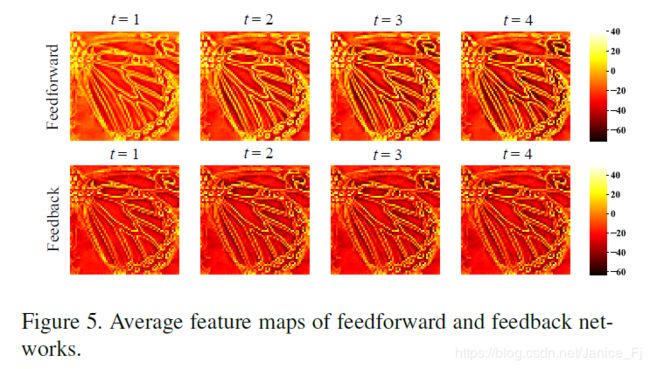
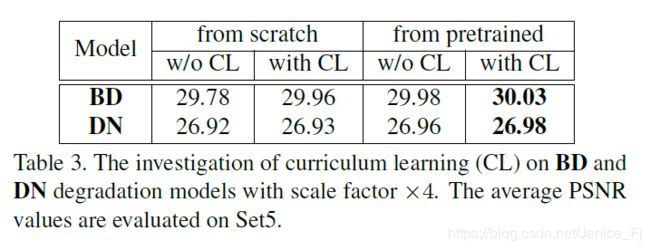
(3)Study of curriculum learning
(4)Comparison with the stateofthearts