大数据-Spark实例
Spark实例
tomcat日志110.52.250.126 - - [30/May/2018:17:38:20 +0800] "GET /source/plugin/wsh_wx/img/wsh_zk.css HTTP/1.1" 200 1482
27.19.74.143 - - [30/May/2018:17:38:20 +0800] "GET /static/image/common/faq.gif HTTP/1.1" 200 1127
27.19.74.143 - - [30/May/2018:17:38:20 +0800] "GET /static/image/common/hot_1.gif HTTP/1.1" 200 680
27.19.74.143 - - [30/May/2018:17:38:20 +0800] "GET /static/image/common/hot_1.gif HTTP/1.1" 200 682
27.19.74.143 - - [30/May/2018:17:38:20 +0800] "GET /static/image/filetype/common.gif HTTP/1.1" 200 90
110.52.250.126 - - [30/May/2018:17:38:20 +0800] "GET /source/plugin/wsh_wx/img/wx_jqr.gif HTTP/1.1" 200 1770
27.19.74.143 - - [30/May/2018:17:38:20 +0800] "GET /static/image/common/recommend_1.gif HTTP/1.1" 200 1030
110.52.250.126 - - [30/May/2018:17:38:20 +0800] "GET /static/image/common/wsh_zk.css HTTP/1.1" 200 4542
27.19.74.143 - - [30/May/2018:17:38:20 +0800] "GET /data/attachment/common/c8/common_2_verify_icon.png HTTP/1.1" 200 582
27.19.74.143 - - [30/May/2018:17:38:20 +0800] "GET /static/image/common/pn.png HTTP/1.1" 200 592
27.19.74.143 - - [30/May/2018:17:38:20 +0800] "GET /static/image/editor/editor.gif HTTP/1.1" 200 13648
8.35.201.165 - - [30/May/2018:17:38:21 +0800] "GET /uc_server/data/avatar/000/05/94/42_avatar_middle.jpg HTTP/1.1" 200 6153
8.35.201.164 - - [30/May/2018:17:38:21 +0800] "GET /uc_server/data/avatar/000/03/13/42_avatar_middle.jpg HTTP/1.1" 200 5087
8.35.201.163 - - [30/May/2018:17:38:21 +0800] "GET /uc_server/data/avatar/000/04/87/42_avatar_middle.jpg HTTP/1.1" 200 5117
8.35.201.165 - - [30/May/2018:17:38:21 +0800] "GET /uc_server/data/avatar/000/01/01/42_avatar_middle.jpg HTTP/1.1" 200 5844
8.35.201.160 - - [30/May/2018:17:38:21 +0800] "GET /uc_server/data/avatar/000/04/12/42_avatar_middle.jpg HTTP/1.1" 200 3174
8.35.201.163 - - [30/May/2018:17:38:21 +0800] "GET /static/image/common/arw_r.gif HTTP/1.1" 200 65
8.35.201.166 - - [30/May/2018:17:38:21 +0800] "GET /static/image/common/search.png HTTP/1.1" 200 210
8.35.201.144 - - [30/May/2018:17:38:21 +0800] "GET /static/image/common/pmto.gif HTTP/1.1" 200 152
8.35.201.161 - - [30/May/2018:17:38:21 +0800] "GET /static/image/common/search.png HTTP/1.1" 200 3047
8.35.201.164 - - [30/May/2018:17:38:21 +0800] "GET /uc_server/data/avatar/000/05/83/35_avatar_middle.jpg HTTP/1.1" 200 7171
8.35.201.160 - - [30/May/2018:17:38:21 +0800] "GET /uc_server/data/avatar/000/01/54/35_avatar_middle.jpg HTTP/1.1" 200 5396
实例一:求图片的访问量
scala代码package Spark
import org.apache.spark.{SparkConf, SparkContext}
import scala.util.matching.Regex
/*
* 解析tomcat日志
*
* @author Jabin
* @version 0.0.1
* @data 2019/07/16
* */
object LogCount {
def main(args: Array[String]): Unit = {
//创建Spark配置
val conf = new SparkConf().setAppName("Log.Count").setMaster("local")
//加载Spark配置
val sc = new SparkContext(conf)
val rdd = sc.textFile("C:\\Users\\Administrator\\Desktop\\日志\\tomcat.log")
.map(
line => {
/*
* 27.19.74.143 - - [30/May/2018:17:38:20 +0800] "GET /static/image/common/faq.gif HTTP/1.1" 200 1127
* 通过正则表达式匹配
* */
val pattern = "(/(\\w)+)+\\.[a-z]{3}".r
//得到/static/image/common/faq.gif
val photoDir = pattern.findAllIn(line).mkString(",")
val regex = new Regex("\\w+\\.[a-z]{3}")
//得到faq.gif
val photoName = regex.findAllIn(photoDir).mkString(",")
(photoName, 1)
}
)
val rdd1 = rdd.reduceByKey(_+_)
rdd1.foreach(println)
val rdd2 = rdd1.sortBy(_._2,false)
rdd2.foreach(println)
rdd2.take(2).foreach(println)
//关闭
sc.stop()
}
}
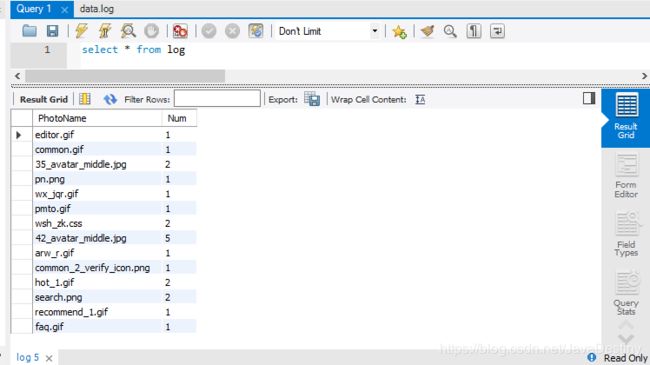
结果
//reduceByKey结果
(editor.gif,1)
(common.gif,1)
(35_avatar_middle.jpg,2)
(pn.png,1)
(wx_jqr.gif,1)
(pmto.gif,1)
(wsh_zk.css,2)
(42_avatar_middle.jpg,5)
(arw_r.gif,1)
(common_2_verify_icon.png,1)
(hot_1.gif,2)
(search.png,2)
(recommend_1.gif,1)
(faq.gif,1)
//sortBy结果
(42_avatar_middle.jpg,5)
(35_avatar_middle.jpg,2)
(wsh_zk.css,2)
(hot_1.gif,2)
(search.png,2)
(editor.gif,1)
(common.gif,1)
(pn.png,1)
(wx_jqr.gif,1)
(pmto.gif,1)
(arw_r.gif,1)
(common_2_verify_icon.png,1)
(recommend_1.gif,1)
(faq.gif,1)
//最终结果
(42_avatar_middle.jpg,5)
(35_avatar_middle.jpg,2)
实例二:创建自定义分区
scala代码
package Spark
import org.apache.spark.{Partitioner, SparkConf, SparkContext}
import scala.collection.mutable
import scala.util.matching.Regex
/*
* 解析tomcat日志,自定义分区
*
* @author Jabin
* @version 0.0.1
* @data 2019/07/16
* */
object PartitionCount {
def main(args: Array[String]): Unit = {
//创建Spark配置
val conf = new SparkConf().setAppName("Partition.Count").setMaster("local")
//加载Spark配置
val sc = new SparkContext(conf)
val rdd = sc.textFile("C:\\Users\\Administrator\\Desktop\\作业\\tomcat.log")
.map(
line => {
/*
* 27.19.74.143 - - [30/May/2018:17:38:20 +0800] "GET /static/image/common/faq.gif HTTP/1.1" 200 1127
* 通过正则表达式匹配
* */
val pattern = "(/(\\w)+)+\\.[a-z]{3}".r
//得到/static/image/common/faq.gif
val photoDir = pattern.findAllIn(line).mkString(",")
val regex = new Regex("\\w+\\.[a-z]{3}")
//得到faq.gif
val photoName = regex.findAllIn(photoDir).mkString(",")
(photoName, line)
}
)
//获取不重复的photoName
val rdd1 = rdd.map(_._1).distinct().collect
//创建分区规则
val partition = new PartitionCount(rdd1)
val rdd2 = rdd.partitionBy(partition)
rdd2.saveAsTextFile("C:\\Users\\Administrator\\Desktop\\日志\\partition")
//关闭
sc.stop()
}
}
class PartitionCount(array: Array[String]) extends Partitioner{
//创建map存储photoName
val map = new mutable.HashMap[String, Int]()
//初始化分区
var id = 0
for (arr <- array){
map.put(arr,id)
id += 1
}
//返回分区的数目
override def numPartitions: Int = map.size
//根据photoName,返回对应的分区
override def getPartition(key: Any): Int = map.getOrElse(key.toString,0)
}
结果
实例三:访问数据库(查询)
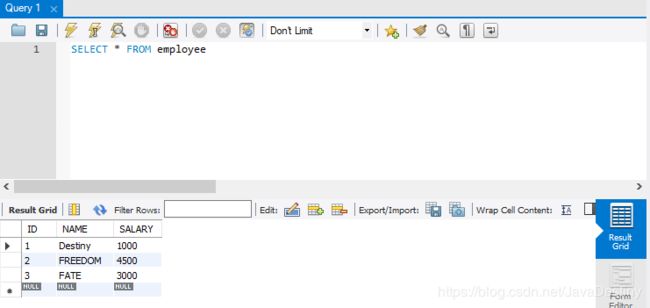
SQL代码CREATE database IF NOT EXISTS DATA;
USE DATA;
CREATE TABLE EMPLOYEE(ID INT NOT NULL AUTO_INCREMENT,NAME VARCHAR(20),SALARY INT,PRIMARY KEY(ID));
INSERT INTO EMPLOYEE(NAME,SALARY) VALUES('Destiny',1000);
INSERT INTO EMPLOYEE(NAME,SALARY) VALUES('Freedom',4500);
INSERT INTO EMPLOYEE(NAME,SALARY) VALUES('Fate',3000);
SELECT * FROM EMPLOYEE;
scala代码
package Spark
import java.sql.DriverManager
import org.apache.spark.rdd.JdbcRDD
import org.apache.spark.{SparkConf, SparkContext}
/*
* 解析tomcat日志,自定义分区
*
* @author Jabin
* @version 0.0.1
* @data 2019/07/17
* */
object JDBC {
//创建连接
private val connection = () => {
Class.forName("com.mysql.cj.jdbc.Driver").newInstance()
DriverManager.getConnection("jdbc:mysql://localhost:3306/data?serverTimezone=GMT%2B8","root","root")
}
def main(args: Array[String]): Unit = {
//创建Spark配置
val conf = new SparkConf().setAppName("JDBC.Count").setMaster("local")
//加载Spark配置
val sc = new SparkContext(conf)
val rdd = new JdbcRDD(sc,connection,"SELECT * FROM EMPLOYEE WHERE SALARY >= ? AND SALARY < ?",3000,6000,2,r => {
val name = r.getString(2)
val salary = r.getInt(3)
(name,salary)
})
val result = rdd.collect()
println(result.toBuffer)
// result.foreach(println)
//关闭
sc.stop()
}
}
结果
ArrayBuffer((FATE,3000), (FREEDOM,4500))
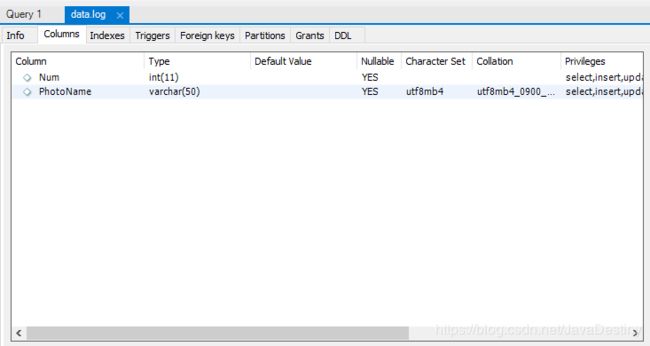
实例三:访问数据库(插入)
SQL代码CREATE database IF NOT EXISTS DATA;
USE DATA;
CREATE TABLE LOG(PhotoName VARCHAR(50),Num INT)
scala代码
package Spark
import java.sql.{Connection, DriverManager, PreparedStatement}
import org.apache.spark.{SparkConf, SparkContext}
import scala.util.matching.Regex
/*
* 将数据导入到MySQL
*
* @author Jabin
* @version 0.0.1
* @data 2019/07/18
* */
object MyMySQL {
var connection : Connection = _
var pst : PreparedStatement = _
def main(args: Array[String]): Unit = {
//创建Spark配置
val conf = new SparkConf().setAppName("MySQL.Count").setMaster("local")
//加载Spark配置
val sc = new SparkContext(conf)
val rdd = sc.textFile("C:\\Users\\Administrator\\Desktop\\作业\\tomcat.log")
.map(
line => {
/*
* 27.19.74.143 - - [30/May/2018:17:38:20 +0800] "GET /static/image/common/faq.gif HTTP/1.1" 200 1127
* 通过正则表达式匹配
* */
val pattern = "(/(\\w)+)+\\.[a-z]{3}".r
//得到/static/image/common/faq.gif
val photoDir = pattern.findAllIn(line).mkString(",")
val regex = new Regex("\\w+\\.[a-z]{3}")
//得到faq.gif
val photoName = regex.findAllIn(photoDir).mkString(",")
(photoName, 1)
}
)
val rdd1 = rdd.reduceByKey(_+_)
rdd1.foreachPartition(insertData)
sc.stop()
}
def insertData(iter: Iterator[(String, Int)]) = {
try{
connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/data?serverTimezone=GMT%2B8","root","root")
pst = connection.prepareStatement("INSERT INTO LOG VALUES(?,?)")
iter.foreach(f =>{
pst.setString(1,f._1)
pst.setInt(2,f._2)
pst.executeUpdate()
})
}catch{
case t: Throwable => t.printStackTrace()
}finally {
if (connection != null) connection.close()
if (pst != null) pst.close()
}
}
}
结果