Convex Optimization: Primal Problem to Dual problem clearly explained 详细
往期文章链接目录
文章目录
- 往期文章链接目录
- The Lagrange dual function
- Lower bound property
- Derive an analytical expression for the Lagrange dual function
- Practice problem 1: Least-squares solution of linear equations
- Practice problem 2: Standard form Linear Programming
- The Lagrange dual problem
- Weak/ Strong duality
- Slater’s condition
- Complementary slackness
- KKT optimality conditions
- KKT conditions for nonconvex problems
- KKT conditions for convex problems
- Solving the primal problem via the dual
- 往期文章链接目录
Consider an optimization problem in the standard form (we call this a primal problem):
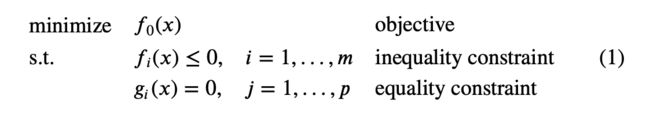
We denote the optimal value of this as p ⋆ p^\star p⋆. We don’t assume the problem is convex.
The Lagrange dual function
We define the Lagrangian L L L associated with the problem as
L ( x , λ , v ) = f 0 ( x ) + ∑ i = 1 m λ i f i ( x ) + ∑ i = 1 p v i h i ( x ) L(x,\lambda, v) = f_0(x) + \sum^m_{i=1}\lambda_if_i(x) + \sum^p_{i=1}v_ih_i(x) L(x,λ,v)=f0(x)+i=1∑mλifi(x)+i=1∑pvihi(x)
We call vectors λ \lambda λ and v v v the dual variables or Lagrange multiplier vectors associated with the problem (1).
We define the Lagrange dual function (or just dual function) g g g as the minimum value of the Lagrangian over x x x: for λ ∈ R m , v ∈ R p \lambda \in \mathbf{R}^m, v\in\mathbf{R}^p λ∈Rm,v∈Rp,
g ( λ , v ) = i n f x ∈ D L ( x , λ , v ) = i n f x ∈ D ( f 0 ( x ) + ∑ i = 1 m λ i f i ( x ) + ∑ i = 1 p v i h i ( x ) ) g(\lambda,v) = \mathop{\rm inf}\limits_{x\in \mathcal{D}} L(x, \lambda, v) = \mathop{\rm inf}\limits_{x\in \mathcal{D}} \left( f_0(x) + \sum^m_{i=1}\lambda_if_i(x) + \sum^p_{i=1}v_ih_i(x)\right) g(λ,v)=x∈DinfL(x,λ,v)=x∈Dinf(f0(x)+i=1∑mλifi(x)+i=1∑pvihi(x))
Note that once we choose an x x x, f i ( x ) f_i(x) fi(x) and h i ( x ) h_i(x) hi(x) are fixed and therefore the dual function is a family of affine functions of ( λ \lambda λ, v v v), which is concave even the problem (1) is not convex.
Lower bound property
The dual function yields lower bounds on the optimal value p ⋆ p^\star p⋆ of the problem (1): For any λ ⪰ 0 \lambda \succeq 0 λ⪰0 and any v v v we have
g ( λ , v ) ≤ p ⋆ g(\lambda,v) \leq p^\star g(λ,v)≤p⋆
Suppose x ~ \tilde{x} x~ is a feasible point for the problem (1), i.e., f i ( x ~ ) ≤ 0 f_i(\tilde{x}) \leq 0 fi(x~)≤0 and h i ( x ~ ) = 0 h_i(\tilde{x}) = 0 hi(x~)=0, and λ ⪰ 0 \lambda \succeq 0 λ⪰0. Then we have
L ( x ~ , λ , v ) = f 0 ( x ~ ) + ∑ i = 1 m λ i f i ( x ~ ) + ∑ i = 1 p v i h i ( x ~ ) ≤ f 0 ( x ~ ) L(\tilde{x}, \lambda, v) = f_0(\tilde{x}) + \sum^m_{i=1}\lambda_if_i(\tilde{x}) + \sum^p_{i=1}v_ih_i(\tilde{x}) \leq f_0(\tilde{x}) L(x~,λ,v)=f0(x~)+i=1∑mλifi(x~)+i=1∑pvihi(x~)≤f0(x~)
Hence
g ( λ , v ) = i n f x ∈ D L ( x , λ , v ) ≤ L ( x ~ , λ , v ) ≤ f 0 ( x ~ ) g(\lambda,v) = \mathop{\rm inf}\limits_{x\in \mathcal{D}} L(x, \lambda, v) \leq L(\tilde{x}, \lambda, v) \leq f_0(\tilde{x}) g(λ,v)=x∈DinfL(x,λ,v)≤L(x~,λ,v)≤f0(x~)
Since g ( λ , v ) ≤ f 0 ( x ~ ) g(\lambda,v) \leq f_0(\tilde{x}) g(λ,v)≤f0(x~) holds for every feasible point x ~ \tilde{x} x~, the inequality g ( λ , v ) ≤ p g(\lambda,v) \leq p g(λ,v)≤p follows. The inequality holds, but is vacuous, when g ( λ , v ) = − ∞ g(\lambda,v) = -\infty g(λ,v)=−∞. The dual function gives a nontrivial lower bound on p ⋆ p^\star p⋆ only when λ ⪰ 0 \lambda \succeq 0 λ⪰0 and ( λ , v ) ∈ dom g (\lambda,v) \in \textbf{dom}\,g (λ,v)∈domg, i.e., g ( λ , v ) > − ∞ g(\lambda,v) > - \infty g(λ,v)>−∞. We refer to a pair ( λ , v ) (\lambda,v) (λ,v) with λ ⪰ 0 \lambda \succeq 0 λ⪰0 and ( λ , v ) ∈ dom g (\lambda,v) \in \textbf{dom}\,g (λ,v)∈domg as dual feasible.
Derive an analytical expression for the Lagrange dual function
Practice problem 1: Least-squares solution of linear equations
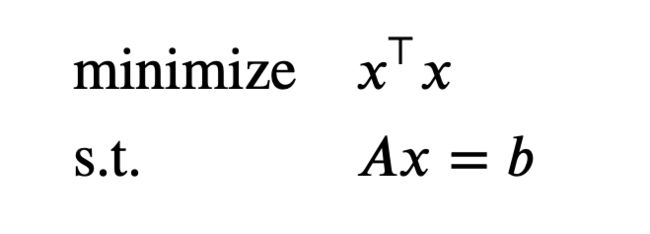
The Lagrangian is L ( x , v ) = x ⊤ x + v ⊤ ( A x − b ) L(x,v) = x^\top x + v^\top(Ax-b) L(x,v)=x⊤x+v⊤(Ax−b). The dual function is given by g ( v ) = inf x L ( x , v ) g(v) = \text{inf}_x L(x,v) g(v)=infxL(x,v). Since L ( x , v ) L(x,v) L(x,v) is a convex quadratic function of x x x, we can find the minimizing x x x from the optimality condition
∇ x L ( x , v ) = 2 x + A ⊤ v = 0 \nabla_x L(x,v) = 2x + A^\top v = 0 ∇xL(x,v)=2x+A⊤v=0
which yields x = − ( 1 / 2 ) A ⊤ v x = -(1/2)A^\top v x=−(1/2)A⊤v. Therefore the dual function is
g ( v ) = L ( − ( 1 / 2 ) A ⊤ v , v ) = − ( 1 / 4 ) v ⊤ A A ⊤ v − b ⊤ v g(v) = L(-(1/2)A^\top v, v) = -(1/4)v^\top AA^\top v - b^\top v g(v)=L(−(1/2)A⊤v,v)=−(1/4)v⊤AA⊤v−b⊤v
Therefore, p ⋆ ≥ − ( 1 / 4 ) v ⊤ A A ⊤ v − b ⊤ v p^\star \geq -(1/4)v^\top AA^\top v - b^\top v p⋆≥−(1/4)v⊤AA⊤v−b⊤v. The next step is to maximize − ( 1 / 4 ) v ⊤ A A ⊤ v − b ⊤ v -(1/4)v^\top AA^\top v - b^\top v −(1/4)v⊤AA⊤v−b⊤v.
Practice problem 2: Standard form Linear Programming
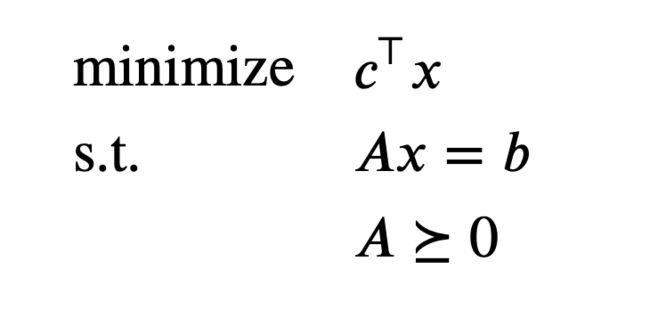
The Lagrangian is
L ( x , λ , v ) = c ⊤ x − ∑ i = 1 n λ i x i + v ⊤ ( A x − b ) = − b ⊤ v + ( c + A ⊤ v − λ ) ⊤ x L(x, \lambda, v) = c^\top x - \sum^n_{i=1}\lambda_ix_i + v^\top(Ax-b) = -b^\top v + (c + A^\top v - \lambda)^\top x L(x,λ,v)=c⊤x−i=1∑nλixi+v⊤(Ax−b)=−b⊤v+(c+A⊤v−λ)⊤x
The dual function is
g ( λ , v ) = i n f x L ( x , λ , v ) = − b ⊤ v + i n f x ( c + A ⊤ v − λ ) ⊤ x g(\lambda, v) = \mathop{\rm inf}\limits_{x} L(x, \lambda, v) = -b^\top v + \mathop{\rm inf}\limits_{x}\, (c + A^\top v - \lambda)^\top x g(λ,v)=xinfL(x,λ,v)=−b⊤v+xinf(c+A⊤v−λ)⊤x
We see that g ( λ , v ) g(\lambda,v) g(λ,v) is a linear function. Since a linear function is bounded below only when it is zero. Thus, g ( λ , v ) = − ∞ g(\lambda,v) = -\infty g(λ,v)=−∞ except when c + A ⊤ v − λ = 0 c + A^\top v - \lambda = 0 c+A⊤v−λ=0. Therefore,

The lower bound property is nontrivial only when λ \lambda λ and v v v satisfy λ ⪰ 0 \lambda \succeq 0 λ⪰0 and c + A ⊤ v − λ c + A^\top v - \lambda c+A⊤v−λ. When this occurs, − b ⊤ v -b^\top v −b⊤v is a lower bound on the optimal value of the LP. We can form an equivalent dual problem by making these equality constraints explicit:
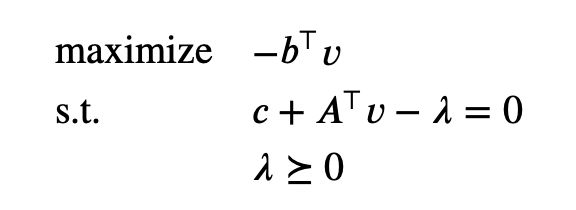
This problem, in turn, can be expressed as
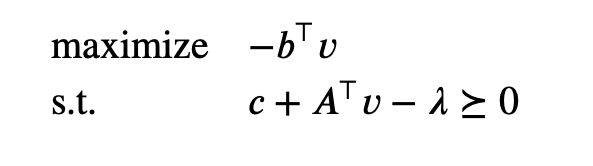
The Lagrange dual problem
For each pair ( λ , v ) (\lambda,v) (λ,v) with λ ⪰ 0 \lambda \succeq 0 λ⪰0, the Lagrange dual function gives us a lower bound on the optimal value p ⋆ p^\star p⋆ of the optimization problem (1). Thus we have a lower bound that depends on some parameters λ , v \lambda, v λ,v.
This leads to the optimization problem
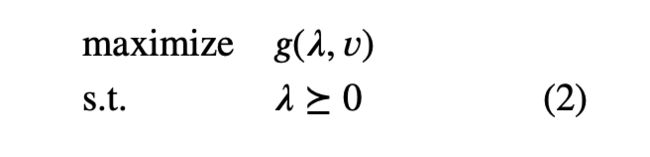
This problem is called the Lagrange dual problem associated with the problem (1). In this context the original problem (1) is sometimes called the primal problem. We refer to ( λ ⋆ , v ⋆ ) (\lambda^\star, v^\star) (λ⋆,v⋆) as dual optimal or optimal Lagrange multipliers if they are optimal for the problem (2). The Lagrange dual problem (2) is a convex optimization problem, since the objective to be maximized is concave and the constraint is convex. This is the case whether or not the primal problem (5.1) is convex.
Note: the dual problem is always convex.
Weak/ Strong duality
The optimal value of the Lagrange dual problem, which we denote d ⋆ d^\star d⋆, is, by definition, the best lower bound on p ⋆ p^\star p⋆ that can be obtained from the Lagrange dual function. The inequality
d ⋆ ≤ p ⋆ d^\star \leq p^\star d⋆≤p⋆
which holds even if the original problem is not convex. This property is called weak duality.
We refer to the difference p ⋆ − d ⋆ p^\star - d^\star p⋆−d⋆ as the optimal duality gap of the original problem. Note that th optimal duality gap is always nonnegative.
We say that strong duality holds if
d ⋆ = p ⋆ d^\star = p^\star d⋆=p⋆
Note that strong duality does not hold in general. But if the primal problem (11) is convex with f 1 , . . . , f k f_1, ..., f_k f1,...,fk convex, we usually (but not always) have strong duality.
Slater’s condition
Slater’s condition: There exists an x ∈ r e l i n t D x \in \mathbf{relint}\, D x∈relintD such that f i ( x ) < 0 , i = 1 , . . . , m , A x = b f_i(x) < 0, \quad i = 1,...,m, \quad Ax = b fi(x)<0,i=1,...,m,Ax=b
Such a point is called strictly feasible.
Slater’s theorem: If Slater’s condition holds for a convex problem, then the strong duality holds.
Complementary slackness
Suppose the strong duality holds. Let x ⋆ x^\star x⋆ be a primal optimal and ( λ ⋆ , v ⋆ ) (\lambda^\star, v^\star) (λ⋆,v⋆) be a dual optimal point. This means that
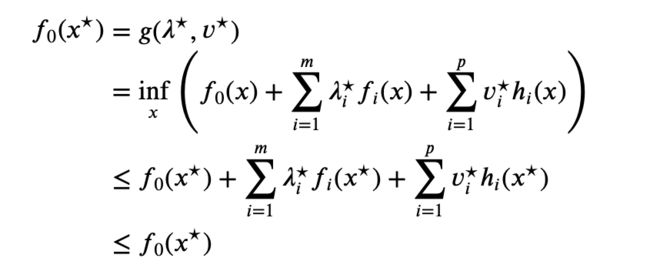
We conclude that the two inequalities in this chain hold with equality. Since the inequality in the third line is an equality, we conclude that x ⋆ x^\star x⋆ minimizes L ( x , λ ⋆ , v ⋆ ) L(x, \lambda^\star, v^\star) L(x,λ⋆,v⋆) over x x x.
Another important conclusion is
λ i ⋆ f i ( x ⋆ ) = 0 , i = 1 , . . . , m \lambda_i^\star f_i(x^\star) = 0, \quad i = 1,...,m λi⋆fi(x⋆)=0,i=1,...,m
KKT optimality conditions
We now assume that the functions f 0 , . . . , f m , h 1 , . . . , h p f_0, ..., f_m, h_1, ...,h_p f0,...,fm,h1,...,hp are differentiable, but we make no assumptions yet about convexity.
KKT conditions for nonconvex problems
Suppose the strong duality holds. Let x ⋆ x^\star x⋆ be a primal optimal and ( λ ⋆ , v ⋆ ) (\lambda^\star, v^\star) (λ⋆,v⋆) be a dual optimal point. Since x ⋆ x^\star x⋆ minimizes L ( x , λ ⋆ , v ⋆ ) L(x, \lambda^\star, v^\star) L(x,λ⋆,v⋆) over x x x, it follows that its gradient must vanish at x ⋆ x^\star x⋆, i.e.,
∇ f 0 ( x ⋆ ) + ∑ i = 1 m λ i ⋆ ∇ f i ( x ⋆ ) + ∑ i = 1 p v i ⋆ ∇ h i ( x ⋆ ) = 0 \nabla f_0(x^\star) + \sum^m_{i=1}\lambda_i^\star \nabla f_i(x^\star) + \sum^p_{i=1}v_i^\star \nabla h_i(x^\star) = 0 ∇f0(x⋆)+i=1∑mλi⋆∇fi(x⋆)+i=1∑pvi⋆∇hi(x⋆)=0
The KKT conditions are the following:
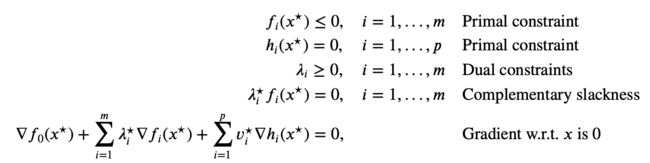
For any optimization problem with differentiable objective and constraint functions for which strong duality obtains, any pair of primal and dual optimal points must satisfy the KKT conditions.
KKT conditions for convex problems
When the primal problem is convex, the KKT conditions are also sufficient for the points to be primal and dual optimal. That is, if f i f_i fi are convex and h i h_i hi are affine, and x ~ , λ ~ , v ~ \tilde{x}, \tilde{\lambda}, \tilde{v} x~,λ~,v~ are any points that satisfy the KKT conditions
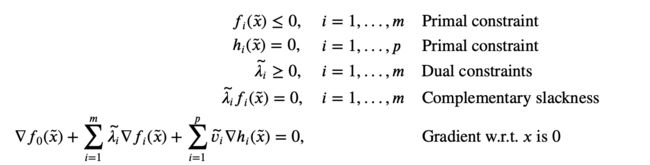
then x ~ \tilde{x} x~ and ( λ i ~ , v i ~ ) (\tilde{\lambda_i}, \tilde{v_i}) (λi~,vi~) are primal and dual optimal, with zero duality gap. To see this, note that the first two conditions state that x ~ \tilde{x} x~ is primal feasible. Since λ i ~ \tilde{\lambda_i} λi~ ≥ 0, L ( x , λ ~ , v ~ ) L(x,\tilde{\lambda},\tilde{v}) L(x,λ~,v~) is convex in x x x; the last KKT condition states that its gradient with respect to x x x vanishes at x = x ~ x = \tilde{x} x=x~, so it follows that x ~ \tilde{x} x~ minimizes L ( x , λ ~ , v ~ ) L(x,\tilde{\lambda},\tilde{v}) L(x,λ~,v~) over x x x. From this we conclude that
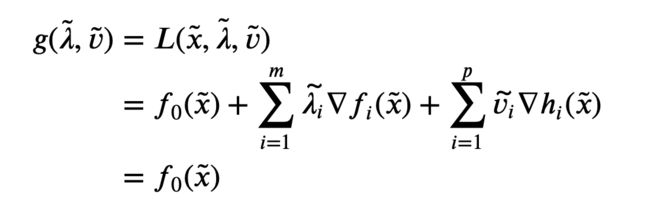
This shows that x ~ \tilde{x} x~ and ( λ ~ , v ~ ) (\tilde{\lambda},\tilde{v}) (λ~,v~) have zero duality gap, and therefore are primal and dual optimal.
We conclude the following:
- For any convex optimization problem with differentiable objective and constraint functions, any points that satisfy the KKT conditions are primal and dual optimal, and have zero duality gap.
- If a convex optimization problem with differentiable objective and constraint functions satisfies Slater’s condition, then the KKT conditions provide necessary and sufficient conditions for optimality: Slater’s condition implies that the optimal duality gap is zero and the dual optimum is attained, so x x x is optimal iff there are ( λ , v ) (\lambda, v) (λ,v) that, together with x x x, satisfy the KKT conditions.
Solving the primal problem via the dual
Note that if strong duality holds and a dual optimal solution ( λ ⋆ , v ⋆ ) (\lambda^\star, v^\star) (λ⋆,v⋆) exists, then any primal optimal point is also a minimizer of L ( x , λ ⋆ , v ⋆ ) L(x, \lambda^\star, v^\star) L(x,λ⋆,v⋆). This fact sometimes allows us to compute a primal optimal solution from a dual optimal solution.
More precisely, suppose we have strong duality and an optimal ( λ ⋆ , v ⋆ ) (\lambda^\star, v^\star) (λ⋆,v⋆) is known. Suppose that the minimizer of L ( x , λ ⋆ , v ⋆ ) L(x, \lambda^\star, v^\star) L(x,λ⋆,v⋆), i.e., the solution of
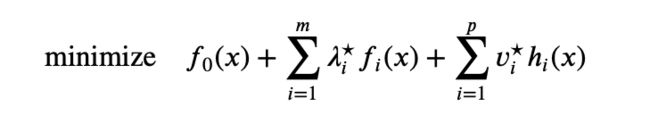
is unique (For a convex problem this occurs). Then if the solution is primal feasible, it must be primal optimal; if it is not primal feasible, then no primal optimal point can exist, i.e., we can conclude that the primal optimum is not attained.
Reference: Convex Optimization by Stephen Boyd and Lieven Vandenberghe.