Openstack Gnocchi 笔记
最近看了点Gnocchi方面的知识,这里拿出来和大家分享下,交流下,同时如果有不对的地方也请大家多多指正。
Ceilometer + Gnocchi:
Gnocchi在Openstack中作为Ceilometer的一个存储模块,它将Ceilometer发送过来的sample进行了分层,分类,聚合,储存。这里来张官方的构架图看看。
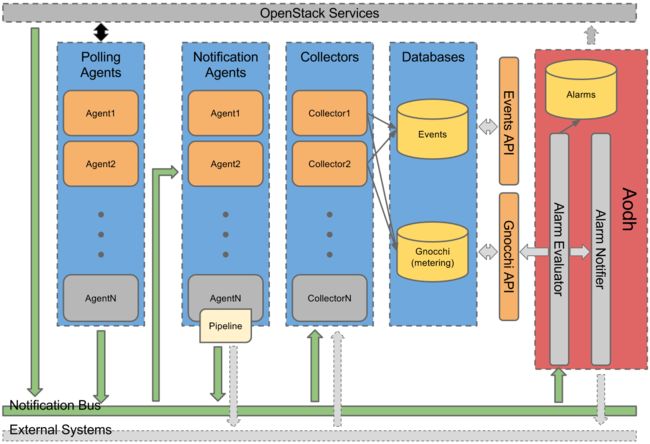
这里可以清楚的看到Ceilometer的Collector 将从数据总线上收集过来的event和metering数据进行了分别储存。Gnocchi则负责metering数据的存储。
Gnocchi 概念
为什么要有Gnocchi?
这里可以参考JD大神的博客
https://julien.danjou.info/blog/2014/openstack-ceilometer-the-gnocchi-experiment
Gnocchi 由什么组成,其功能是什么?
Gnocchi是由gnocchi api,gnocchi metric, gnocchi statsd三个组件组成。
gnocchi api: 如你所知,暴露出来接受外部Ceilometer或者命令行来调用。
gnocchi metric:这个比较有意思,它可以将gnocchi 暂存 在file中sample数据根据定义的规则进行聚合,并储存规划到其他file中(gnocchi默认用file backend来储存聚合的数据,当然swift和ceph也可以用)
gnocchi statsd: 这个是个网络进程来监听你上通过UDP,TCP协议传输过来的数据。也是暴露给外端进行使用的一个功能。
想要知道官方怎么说的,可以参照这个
http://docs.openstack.org/developer/gnocchi/architecture.html
Gnocchi数据存储的框架是什么样的呢?
(此文介绍默认的file存储方式)
Gnocchi 将sample数据也进行了分类储存,分别由index driver和storage driver负责。
- index driver: 主要负责 resource和其对应的metrics的存储。
- storage driver : 主要负责 metric和其对应data 值的存储。
resource: 指的是环境中创建出来的一些虚拟资源,比如一个instance,network interface,disk 等。
metric:指的是对一个虚拟资源的度量衡,一个虚拟资源一般会用多个度量衡来描述,比如一个instance可以有cpu个数,cpu利用率之类的度量衡,可以参考ceilometer pipeline的配置文档来了解各个度量衡的意思和用处,这里就不多说了。
data:每个度量衡的值,可以是一个值也可以是一批值。以timestamp:value形式存在。
再来张官方的图看看

这张图中可以出gnocchi rest api调用不同的driver将数据分类储存在了SQL DB和Swift中(这里可以配置成file或ceph后端)。
Gnocchi 是将data聚合后进行储存的,那么遵循的聚合规律是什么,该如何定义这些规律也就成了问题。
Gnocchi 的聚合方式是由archive policy定义的。现在看看archive policy长什么样吧。
HTTP/1.1 200 OK
Content-Length: 598
Content-Type: application/json; charset=UTF-8
{
"archive_policy": {
"aggregation_methods": [
"std",
"sum",
"mean",
"max",
"median",
"count",
"min",
"95pct"
],
"back_window": 0,
"definition": [
{
"granularity": "0:00:01",
"points": 3600,
"timespan": "1:00:00"
},
{
"granularity": "0:01:00",
"points": 10080,
"timespan": "7 days, 0:00:00"
},
{
"granularity": "1:00:00",
"points": 8760,
"timespan": "365 days, 0:00:00"
}
],
"name": "high"
},
"created_by_project_id": "46476b8c-04e8-4276-89bf-0e8d7f4c4758",
"created_by_user_id": "f0396120-5c47-4583-a45e-f5387a00425f",
"id": "399239ea-61e5-4eee-9343-ab5039c432b4",
"name": null,
"resource": null,
"unit": null
}在一个archive policy中主要包含三个部分name,definition,aggregation methods,back window。
name: 顾名思义,就是这个archive policy的名字,每个archive policy创建时可以定义不同的名字。
definition: 这里个部分比较重要。定义了gnocchi 做聚合的频率和此频率的生命周期。
- granularity: 即聚合时间粒度,多少时间聚合一次。 - timespan:即此聚合粒度的生命周期,一个生命周期后此聚合将删除,更新一次。 - point:gnocchi将一个生命周期内的聚合次数以points采样点表示,即timespan/granularity = points。(当ceilometer post过来多个samples时,gnocchi会以最接近采样点时间的sample作为gnocchi的采样sample。这里是我跟人理解,如有误,一定要告诉我,谢谢:D)back_window: 是用来处理滞后sample的。默认为0,即不对滞后的sample进行处理。
aggregation_methods: 这里定义了聚合的方法。调用Python Panda模块实现。
Gnocchi 有三个默认的archive policy可以参考这里。
http://docs.openstack.org/developer/gnocchi/architecture.html#how-to-set-the-archive-policy-and-granularity
如何配置这些gnocchi 存储功能呢?由于每个人需求不同,配置也有所差异,咱们就去看看这些官方参考。
ceilometer端
http://docs.openstack.org/developer/ceilometer/install/custom.html
http://docs.openstack.org/mitaka/config-reference/telemetry/telemetry_service_config_opts.html
gnocchi端
http://docs.openstack.org/developer/gnocchi/configuration.html
Gnocchi 提供了哪些API?
官方答案:
http://docs.openstack.org/cli-reference/gnocchi.html
Gnocchi 是如何实现对大量的sample数据进行,分层,分类,聚合,储存的?
既然Gnocchi的主要任务是储存那这些储存功能是如何实现的呢。
这里以Ceilometer向Gnocchi发送数据的过程为例子。
Data Sample 的存储:
在Ceilometer中有这个GnocchiDispatcher类,此类继承了MeterDispatcherBase。
观察MeterDispatcherBase这个类,我们不难发现其中主要的方法是record_metering_data。
@six.add_metaclass(abc.ABCMeta)
class MeterDispatcherBase(Base):
@abc.abstractmethod
def record_metering_data(self, data):
"""Recording metering data interface."""GnocchiDispatcher实现了此方法,向Gnocchi端发送数据。在发送数据前Ceilometer 对数据进行了分层。
...
#以 resource_id 将sample进行分组
resource_grouped_samples = itertools.groupby(
data, key=operator.itemgetter('resource_id'))
...
...
#以 counter_name(即是metric_name)将samples进行分组,sample以list新式发送
metric_grouped_samples = itertools.groupby(
list(samples_of_resource),
key=operator.itemgetter('counter_name'))
...
#这里去call gnocchi 端, 发送一批measure值。那么什么时间发送呢?这和ceilometer pipeline中的定义的时间有关系。
#这里调用gnocchi client
#这里可以参考REST API guide
#http://docs.openstack.org/developer/gnocchi/rest.html
#measure中保存的是{metric_id:[{metric_name:samples}],...}将每一个metrics
try:
self._gnocchi.metric.batch_resources_metrics_measures(measures)
...
#如何gnocchi发现missing_metrics。这里会作处理,应该是create此metric
except gnocchi_exc.BadRequest as e:
...
try:
#这里用到oslo_cache模块(不好意思,还不了解呢)。
self._if_not_cached("create", resource_type, resource,
self._create_resource)
except gnocchi_exc.ResourceAlreadyExists:
metric = {'resource_id': resource['id'],
'name': metric_name}
metric.update(resource["metrics"][metric_name])
try:
self._gnocchi.metric.create(metric)当数据到达Gnocchi端,Gnocchi是如何处理的呢?
Gnocchi 提供了多个Controller 处理REST请求
...
class V1Controller(object):
def __init__(self):
self.sub_controllers = {
"search": SearchController(),
"archive_policy": ArchivePoliciesController(),
"archive_policy_rule": ArchivePolicyRulesController(),
"metric": MetricsController(),
"batch": BatchController(),
"resource": ResourcesByTypeController(),
"resource_type": ResourceTypesController(),
"aggregation": AggregationController(),
"capabilities": CapabilityController(),
"status": StatusController(),
}
...这里BatchContriller这个类下声明的class MetricsMeasuresBatchController(rest.RestController):将被调用。
...
class MetricsMeasuresBatchController(rest.RestController):
# NOTE(sileht): we don't allow to mix both formats
# to not have to deal with id collision that can
# occurs between a metric_id and a resource_id.
# Because while json allow duplicate keys in dict payload
# only the last key will be retain by json python module to
# build the python dict.
MeasuresBatchSchema = voluptuous.Schema(
{utils.UUID: [MeasureSchema]}
)
@pecan.expose()
def post(self):
body = deserialize_and_validate(self.MeasuresBatchSchema)
#这里调用indexer从数据库中索引每一个metrics (gnocchi启动时应该会去加载gnocchi_resource...文件下定义的metrics)
metrics = pecan.request.indexer.list_metrics(ids=body.keys())
#比较数据库中用metric_id查出来的metrics和现实发送过来的metrics是否一致。
if len(metrics) != len(body):
missing_metrics = sorted(set(body) - set(m.id for m in metrics))
abort(400, "Unknown metrics: %s" % ", ".join(
six.moves.map(str, missing_metrics)))
#验证policy.yaml
for metric in metrics:
enforce("post measures", metric)
#这里对metric进行储存
for metric in metrics:
pecan.request.storage.add_measures(metric, body[metric.id])
pecan.response.status = 202这里用默认的file进行储存,存储的实现即在Gnocchi的file.py这个文件中了。
def _store_new_measures(self, metric, data):
#gnocchi 会作一个暂存,将data暂存在一个名为tmp的file的文件夹下。
tmpfile = self._get_tempfile()
tmpfile.write(data)
tmpfile.close()
#此处将没有聚合的数据储存在 measure//_文件中
path = self._build_measure_path(metric.id, True)
while True:
try:
os.rename(tmpfile.name, path)
break到这里是我理解的一个储存临时sample data (注意这里的data还没有聚合过)的过程。其中有几个类和模块值得多看看。
Data Sample 的聚合:
Gnocchi对数据的聚合是通过Gnocchi metric + Python Panda 模块进行异步处理的。
class MetricdServiceManager(cotyledon.ServiceManager):
def __init__(self, conf):
super(MetricdServiceManager, self).__init__()
self.conf = conf
self.queues = [multiprocessing.Queue()
for i in range(conf.metricd.workers)]
# 聚合,储存
self.add(self.create_processor, workers=conf.metricd.workers)
# 报告功能
self.add(MetricReporting, args=(self.conf, self.queues))
# 清理功能
self.add(MetricJanitor, args=(self.conf,))
def create_processor(self, worker_id):
queue = self.queues[worker_id - 1]
return MetricProcessor(worker_id, self.conf, queue)聚合,储存功能是由class MetricProcessor(MetricProcessBase)这个类中的self.store.process_background_tasks(self.index, self.block_size)方法实现的。
def process_background_tasks(self, index, block_size=128, sync=False):
"""Process background tasks for this storage.
正如这里所解释
This calls :func:`process_new_measures` to process new measures
:param index: An indexer to be used for querying metrics
默认一次性处理128个metrics
:param block_size: number of metrics to process
:param sync: If True, then process everything synchronously and raise
on error
:type sync: bool
"""
LOG.debug("Processing new measures")
try:
self.process_new_measures(index, block_size, sync)
except Exception:
if sync:
raise
LOG.error("Unexpected error during measures processing",
exc_info=True)来看看self.process_new_measures(index, block_size, sync)这个方法做了什么。
def process_new_measures(self, indexer, block_size, sync=False):
# 找出在measure文件夹下要处理的metrics(<=128)
metrics_to_process = self._list_metric_with_measures_to_process(
block_size, full=sync)
# 找出在数据库中所有效的metrics
metrics = indexer.list_metrics(ids=metrics_to_process)
# 删除measures文件下取到的无效metrics
# This build the list of deleted metrics, i.e. the metrics we have
# measures to process for but that are not in the indexer anymore.
deleted_metrics_id = (set(map(uuid.UUID, metrics_to_process))
- set(m.id for m in metrics))
...
self._delete_unprocessed_measures_for_metric_id(metric_id)
...
# 对不同的metrics进行处理
for metric in metrics:
...
# 读取measure目录下,当前metric_id对应的所有measures
with self._process_measure_for_metric(metric) as measures:
...
# 对measures进行排序
measures = sorted(measures, key=operator.itemgetter(0))
...
# metric_id对应的none file中数据进行收集
raw_measures = (self._get_unaggregated_timeserie(metric))
...
# Build a time series from a dict
ts = carbonara.BoundTimeSerie.unserialize(
raw_measures)
...
# ts 是空则创建一个新的time series。
# 这个 time series的block_size是由最大时间粒度决定(granularity)
if ts is None:
# This is the first time we treat measures for this
# metric, or data are corrupted, create a new one
mbs = metric.archive_policy.max_block_size
ts = carbonara.BoundTimeSerie(
block_size=mbs,
back_window=metric.archive_policy.back_window)
....
with timeutils.StopWatch() as sw:
# 此方法将新none中的值和measures中的值进行融合,计算。
# 将measures中时间戳大于等于none中最大时间戳的数据添加到time series对象中。
# 即现在ts中包含了none和measure值。
# bound_timeserie is entire set of
# unaggregated measures matching largest
# granularity.
ts.set_values(
measures,
before_truncate_callback=_map_add_measures,
ignore_too_old_timestamps=True)
...在gnocchi用最大时间粒度整合了所有none和measures中的数据后。gnocchi要开始针对不同时间粒度来计算聚合数据了。这里是由下面方法实现
...
def _map_add_measures(bound_timeserie):
# NOTE (gordc): bound_timeserie is entire set of
# unaggregated measures matching largest
# granularity. the following takes only the points
# affected by new measures for specific granularity
tstamp = max(bound_timeserie.first, measures[0][0])
# 需要计算的数据长度。
computed_points['number'] = len(bound_timeserie)
# 针对不同时间粒度和聚合方法对不同的metric进行计算
self._map_in_thread(
self._add_measures,
((aggregation, d, metric,
carbonara.TimeSerie(bound_timeserie.ts[
carbonara.TimeSerie.round_timestamp(
tstamp, d.granularity * 10e8):]))
for aggregation in agg_methods
for d in metric.archive_policy.definition))
...
# *** 这里是gnocchi聚合数据的方法
# *** 但是这个方法我不是很清楚,其实对于granularity如何使用,都还保持疑问。。。
# *** 如果大家指导求指导。
def _add_measures(self, aggregation, archive_policy_def,
metric, timeserie):
# 对应但前的时间粒度,和聚合方法取得已经聚合过的值以对象(AggregatedTimeSerie)。
# /opt/stack/data/gnocchi/0f4bc5fd-48c5-48d8-88ec-
# 1ffc2525e5aa/agg_std/1468800000.0_300.0
ts = self._get_measures_timeserie(metric, aggregation,
archive_policy_def.granularity,
timeserie.first, timeserie.last)
# 用新值来更新老值,老聚合值+新measures值计算出聚合?
ts.update(timeserie)
# 储存聚合后的数据
for key, split in ts.split():
self._store_metric_measures(metric, key, aggregation,
archive_policy_def.granularity,
split.serialize())
# 对于超过timespan的数据删除。
if ts.last and archive_policy_def.timespan:
oldest_point_to_keep = ts.last - datetime.timedelta(
seconds=archive_policy_def.timespan)
self._delete_metric_measures_before(
metric, aggregation, archive_policy_def.granularity,
oldest_point_to_keep)
...最后gnocchi 还对没有聚合完的数据进行了储存
self._store_unaggregated_timeserie(metric,
ts.serialize())到这里,是我现在对Gnocchi局限的理解,并没由多深入。希望能对大家有帮助吧 :D.