10. Flink 状态管理与检查点机制

1. Flink 状态管理
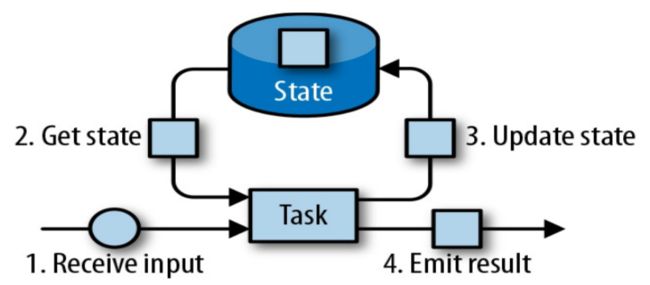
什么是有状态的计算?
- 首先输入数据源源不断输入到Task里面
- 当计算的时候通过Getstate 从State容器里读取历史的状态
- 经过一系列处理又更新到State容器里面
- 将处理后的结果发送到下游
1.1 状态分类
相对于其他流计算框架,Flink 一个比较重要的特性就是其支持有状态计算。即你可以将中间的计算结果进行保存,并提供给后续的计算使用:
state一般指一个具体的task/operator的状态,state数据默认保存在java堆内存中
Flink 又将状态 (State) 分为 Keyed State 与 Operator State:
1.2 算子状态
算子状态 (Operator State):顾名思义,状态是和算子进行绑定的,一个算子的状态不能被其他算子所访问到。官方文档上对 Operator State 的解释是:each operator state is bound to one parallel operator instance,所以更为确切的说一个算子状态是与一个并发的算子实例所绑定的,即假设算子的并行度是 2,那么其应有两个对应的算子状态:
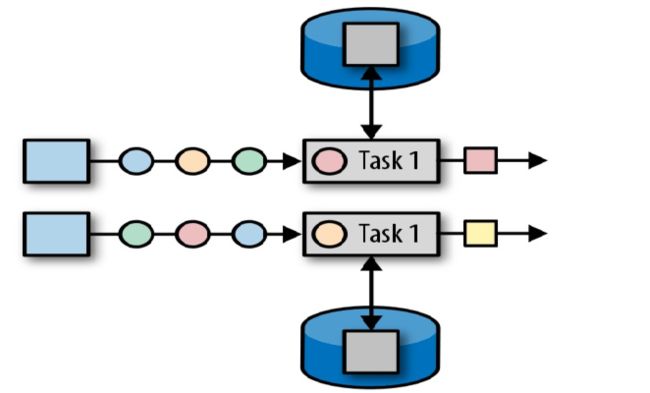
算子状态的作用范围限定为算子任务,由同一并行子任务所处理的所有数据都可以访问到相同的状态;
状态对于同一个任务而言是共享的(每一个并行的子任务共享一个状态);
算子状态不能由相同或不同算子的另一个任务访问(相同算子的不同任务之间也不能访问);
算子状态数据结构
- ListState:列表状态,将状态表示为一组数据的列表。
- UnionListState:联合列表状态,与 ListState 的区别在于:如果并行度发生变化,ListState 会将该算子的所有并发的状态实例进行汇总,然后均分给新的 Task;而 UnionListState 只是将所有并发的状态实例汇总起来,具体的划分行为则由用户进行定义。
- BroadcastState:广播算子状态,一个算子有多项任务,而它的每项任务状态又都相同,这种特殊情况适合应用广播状态。
1.3 键控状态
键控状态 (Keyed State) :是基于keyStream上的状态,对keyStream流上的每个key都对应一个state,即状态是根据输入数据流中定义的 key 值进行区分的,Flink 会为每类键值维护一个状态实例,并将具有相同键的所有数据都分区到同一个算子任务中,这个任务会维护和处理这个key对应的状态 如下图所示,每个颜色代表不同 key 值,对应四个不同的状态实例。需要注意的是键控状态只能在 KeyedStream 上进行使用,我们可以通过 stream.keyBy(…) 来得到 KeyedStream 。

键控状态的数据结构:
- ValueState:值状态,将状态表示为单个的值。可以使用 update(T) 进行更新,并通过 T value() 进行检索。
- ListState:列表状态,将状态表示为一组数据的列表。可以使用 add(T) 或 addAll(List) 添加元素;并通过 get() 获得整个列表。
- ReducingState:用于存储经过 ReduceFunction 计算后的结果,使用 add(T) 增加元素。
- AggregatingState:用于存储经过 AggregatingState 计算后的结果,使用 add(IN) 添加元素。
- MapState:映射状态,将状态表示为一组key-value对。
2、键控状态案例
2.1 介绍
2.1.1 技术说明
1.键控状态是针对无界流中的keyStream而设计的
2.将原来的DataStream通过keyBy算子指定的字段进行分组,将分组后结果进行有状态的处理,需要
使用富函数,通过富函数相应方法从父类中继承getRuntimeContext,据此注册一个状态
2.1.2 业务说明
高铁G66抵达了北京西站,旅客依次通过出口,在出口处安放有红外体温测量仪,针对于每个旅客的体温进行监测,xxx旅客的体温偏高,为了蒙蔽体温测量仪,采取措施人为降温,正常通过了红外测温仪的探测,过后该旅客上地铁,也要经过体温测量较之于上次体温升高了0.8度,被地铁的红外测温仪探测到了,发出了警告 ...
2.2 实操步骤
2.2.1 源码
package com.jd.unbounded.sample_state
import com.jd.unbounded.Raytek
import org.apache.flink.api.common.functions.RichFlatMapFunction
import org.apache.flink.api.common.state.{ValueState, ValueStateDescriptor}
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.api.scala._
import org.apache.flink.configuration.Configuration
import org.apache.flink.util.Collector
/**
* Description 键控状态演示
*
* @author lijun
* @create 2020-03-31
*/
object KeyedStateTest {
def main(args: Array[String]): Unit = {
//1.环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//2.获取两个无界流
env.socketTextStream("localhost",6666)
.filter(_.trim.nonEmpty)
.map(perTraveller=>{
val arr = perTraveller.split(",")
val id = arr(0).trim
val temperature = arr(1).trim.toDouble
val name = arr(2).trim
val timestamp = arr(3).trim.toLong
val location = arr(4).trim
Raytek(id, temperature, name, timestamp, location)
}).keyBy("name")
.flatMap(new MyRichFlatMapFunction(0.8))
.print("累加处理后结果是-->")
//4.启动
env.execute()
}
/**
* 自定义的富函数
* @param threshold 体温变化的阈值
*/
class MyRichFlatMapFunction(threshold:Double) extends RichFlatMapFunction[Raytek,(Raytek,String)]{
//通过valueState来存储当前旅客上一次的体温信息
var tempValueState:ValueState[Double] = _
//初始化
override def open(parameters: Configuration): Unit = {
//步骤
//1. ValueStateDescriptor,封装了ValueState中元素的类型信息
val desc:ValueStateDescriptor[Double] = new ValueStateDescriptor("temperature",classOf[Double])
//2.注册一个ValueState
tempValueState = getRuntimeContext.getState[Double](desc)
}
/**
* 每次处理 DataStream中实时产生的元素
* @param value
* @param out
*/
override def flatMap(value: Raytek, out: Collector[(Raytek, String)]): Unit = {
//获得状态中保存的旅客上一次的体温信息
val lastTemperature = tempValueState.value()
val nowTemperature = value.temperature
val normal = nowTemperature >= 36.3 && nowTemperature <= 37.2
if(normal){ //1.若体温正常的话,将旅客本次的体温和上次的体温进行比对 若体温差> 0.8, 此时直接发往目标DataStream,进行后续处理,体温差在正常范围内,不予干预
if(lastTemperature > 0){
val difTemperature = (nowTemperature - lastTemperature).abs
if(difTemperature > threshold){
out.collect((value,s"旅客${value.name},你好,你本次测得的体温是${value.temperature},上次测得的体温是${lastTemperature} 体温差为${difTemperature},不在临界值${threshold}之内,请接受处理"))
}
}
}else{//2.判断旅客的体温是否在正常范围内,若不正常直接发往目标DataStream,进行后续处理
out.collect((value,s"旅客${value.name},你好,你的体温是${value.temperature},不在正常范围之内36.3-37.2,请接受工作人员的处理..."))
}
//更新状态值为该旅客最新的体温信息
tempValueState.update(nowTemperature)
}
}
}
2.2.2 socker源输入

2.2.3 控制台输出
![]()
3、检查点机制
3.1 CheckPoints
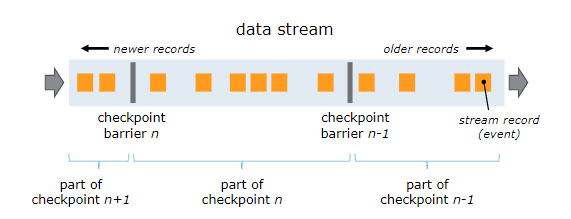
为了使 Flink 的状态具有良好的容错性,Flink 提供了检查点机制 (CheckPoints) 。通过检查点机制,Flink 定期在数据流上生成 checkpoint barrier ,当某个算子收到 barrier 时,即会基于当前状态生成一份快照,然后再将该 barrier 传递到下游算子,下游算子接收到该 barrier 后,也基于当前状态生成一份快照,依次传递直至到最后的 Sink 算子上。当出现异常后,Flink 就可以根据最近的一次的快照数据将所有算子恢复到先前的状态。
3.2 开启检查点
默认情况下,检查点机制是关闭的,需要在程序中进行开启:
checkpoint开启之后,默认的checkPointMode是Exactly-once
checkpoint的checkPointMode有两种,Exactly-once和At-least-once
// 开启检查点机制,并指定状态检查点之间的时间间隔
env.enableCheckpointing(1000);
// 其他可选配置如下:
// 设置语义
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
// 设置两个检查点之间的最小时间间隔
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);
// 设置执行Checkpoint操作时的超时时间
env.getCheckpointConfig().setCheckpointTimeout(60000);
// 设置最大并发执行的检查点的数量
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
// 将检查点持久化到外部存储
env.getCheckpointConfig().enableExternalizedCheckpoints(
ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
// 如果有更近的保存点时,是否将作业回退到该检查点
env.getCheckpointConfig().setPreferCheckpointForRecovery(true);
3.2.1 一致性检查点
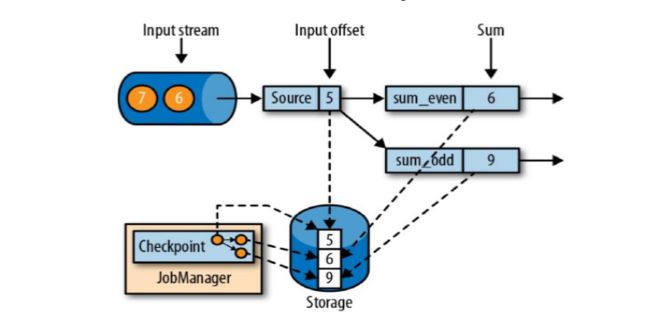
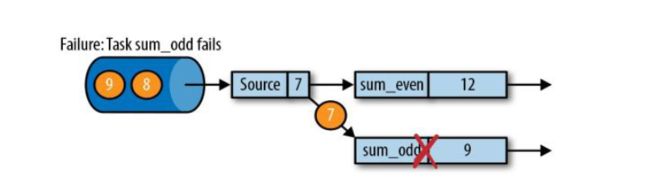
如上图sum_even (2+4),sum_odd(1 + 3 + 5),5这个数据之前的都处理完了,就出保存一个checkpoint;Source任务保存状态5,sum_event任务保存状态6,sum_odd保存状态是9;这三个保存到状态后端中就构成了CheckPoint;
Flink故障恢复机制的核心,就是应用状态的一致性检查点;
有状态流应用的一致性检查点(checkpoint),其实就是所有任务的状态,在某个时间点的一份拷贝(一份快照);这个时间点,应该是所有任务都恰好处理完一个相同的输入数据的时候 。(这个同一时间点并不是物理上的在同一时刻)
3.2.2 从检查点恢复状态
sum_even(2 + 4 + 6);sum_odd(1 + 3 + 5);
在执行应用程序期间,Flink会定期保存状态的一致性检查点;
如果发生故障,Flink将会使用最近的检查点来一致恢复应用程序的状态,并重新启动处理流程;
遇到故障之后,第一步就是重启应用;
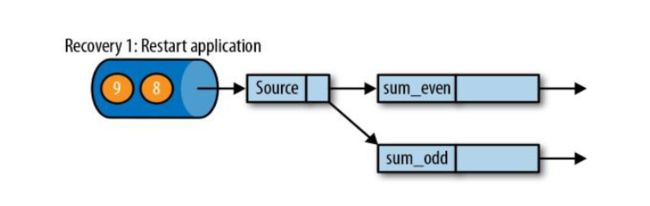
第二步是从checkpoint中读取状态,将状态重置;
从检查点重新启动应用程序后,其内部状态与检查点完成时的状态完全相同;

第三步 :开始消费并处理检查点到发生故障之间的所有数据;
这种检查点的保存和恢复机制可以为应用程序状态提供“精确一次”(exactly-once)的一致性,因为所有算子都会保存检查点并恢复其所有状态,这样一来所有的输入流就都会被重置到检查点完成时的位置。

3.3 检查点的实现算法
简单:暂停应用,保存状态到检查点,再重新恢复应用;
Flink的改进:基于Chandy-Lamport算法的分布式快照;将检查点的保存和数据处理分离开,不暂停整个应用;
检查点分界线(CheckPoint Barrier)
Flink的检查点算法用到了一种称为分界线(barrier)的特殊数据形式,用来把一条流上数据按照不同的检查点分开;
分界线之前到来的数据导致的状态更改,都会被包含在当前分界线所属的检查点中;而基于分界线之后的数据导致的所有更改,就会被包含在之后的检查点中;
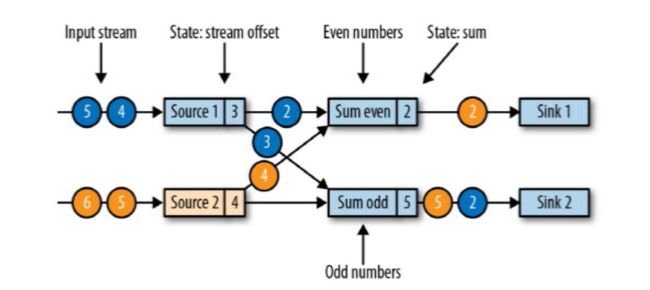
现在是一个有两个输入流的应用程序,用并行的两个Source任务来读取:
两个并行输入源按奇偶数来做sum,类似keyBy重分区map为二元组再做奇偶keyBy,Sum odd(1 + 1 + 3),Sum even(2)
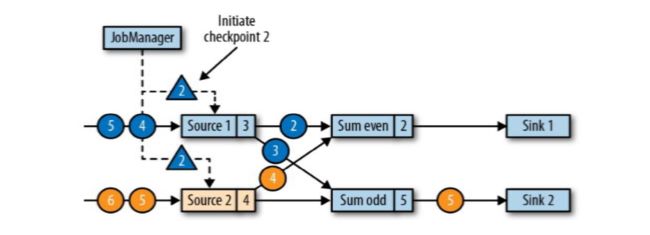
JobManager会向每个source任务发送一条带有新检查点ID的消息,通过这种方式来启动检查点;

数据源将它们的状态写入检查点,并发出一个检查点barrier;
状态后端在状态存入检查点之后,会返回通知给source任务,source任务就会向JobManager确认检查点完成。
source1和source2收到检查点ID = 2时,分别存入自己的偏移量蓝3和黄4,存完之后返回一个ID2通知JobManager快照已保存好;(在保存快照时它会暂停发送和处理数据,同事它也会向下游发送带有检查点ID的barrier,发送的方式直接广播;这个过程中Sum和sink任务也没闲着都在处理数据)

分界线对齐(barrier对齐):barrier向下游传递,sum任务会等待所有输入分区的的barrier到达;
对于barrier已经到达的分区,继续到达的数据会被缓存;
而barrier尚未到达的分区,数据会被正常处理;
(比如蓝2通知给了Sum even,它会等黄2的barrier到达,这时处理的数据4来了,会先被缓存因为它数据下一个checkpoint的数据; 黄2的checkpoint还没来这时它如果来数据还会正常处理更改状态,如上图的在黄2的barrier还没来之前,source2的数据来了条4,它会正常处理Sum event(2 + 2 + 4))
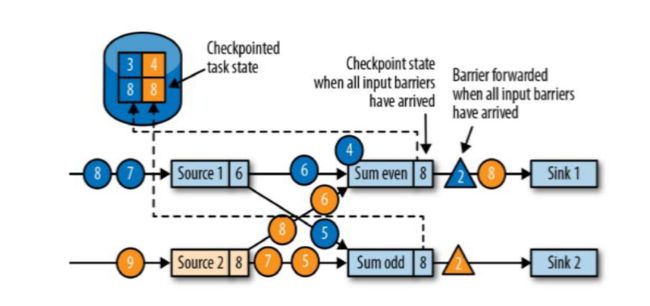
当收到所有输入分区的barrier时,任务就将其状态保存到状态后端的检查点中,然后将barrier继续向下游转发。
barrier对齐之后(Sum even和Sum odd都接收到了两个source发来的barrier),将它们各自的8状态存入checkpoint中;接下来继续向下游Sink广播barrier;
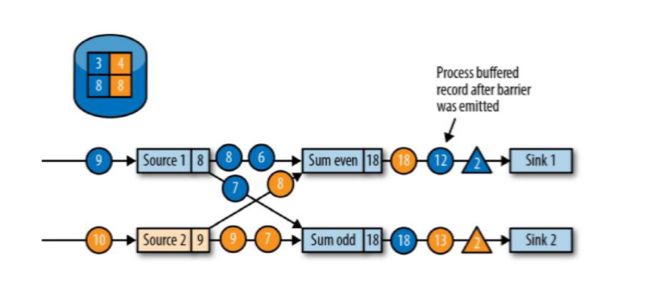
向下游转发检查点的barrier后,任务继续正常的数据处理;
先处理缓存的数据,蓝4加载进来Sum event 12,黄6进来Sum event 18。
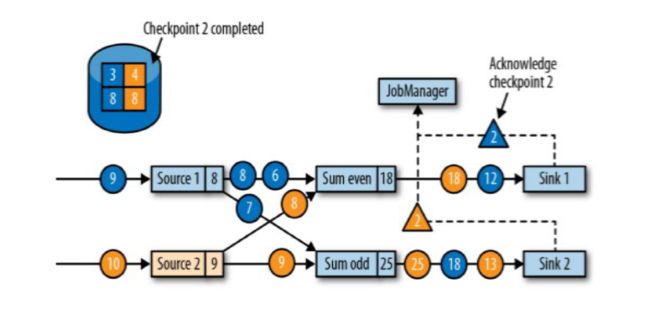
Sink任务向JobManager确认状态保存到checkpoint完毕;(Sink接收到barrier后先保存状态到checkpoint,然后向JobManager汇报)
当所有任务都确认已成功将状态保存到检查点时,检查点就真正完成了。
检查点算法总结
使用到的核心技术是: ABS(Asynchronous Barrier snapshot)异步分割线快照
barrier
1.直译为"分割线"
2.是一个DataStream中的数据标识
3.在pipleLine中流动着的,但是不参与计算的,与其维护的待计算的数据一起在pipleline中流动
4.每次计算的数据是barrier之前的数据
5.source中同一个时点产生的待计算的源数据会划分到一个barrier中
JobManager与Barrier的关系
根据source汇报的情况,自动在相应的待处理的数据之前添加barrier
barrier与checkpoint的关系
sink之前的barrier的状态信息存储在Memory,RocksDB中的barrier抵达了sink之后,sink确认后,将迄今为止计算的最新的结果落地到checkpoint目的地(JobManager的内存, HDFS等)
3.4 保存点机制
Flink还提供了可以自定义的镜像保存功能,就是保存点(savepoints);
原则上,创建保存点使用的算法与检查点完全相同,因此保存点可以认为就是具有一些额外元数据的检查点;
Flink不会自动创建保存点,因此用户(或者外部调度程序)必须明确地触发创建操作;
保存点是一个强大的功能,除了故障恢复外,保存点可以用于:有计划的手动备份,更新应用程序,版本迁移,暂停或重启应用,等等
checkpoint vs savepoint的区别?
checkpoint 应用定时触发,用于保存状态,会过期,内部应用失败重启的时候使用
savepoint 用户手动执行,是指向checkpoint的指针,不会过期,在升级的情况下使用
触发savepoint
bin/flink savepoint jobId [targetDirectory] [-yid yarnAppId](针对on yarn模式需要指定 -yid参数)
3.5 State状态恢复
- 状态恢复
如果Flink程序异常失败,或者最近一段时间内数据处理错误,可将程序从某一个checkpoint点进行恢复
程序正常运行后,还会按照checkpoint配置进行运行,继续生成checkpoint数据 - 恢复命令
bin/flink run -s hdfs://node01:9000/flink/state/fs/733d4f71f675f6174079196b1d5ef49c/chk-14/_metadata flink-job.jar
4、状态后端
4.1 状态管理器分类
默认情况下,所有的状态都存储在 JVM 的堆内存中,在状态数据过多的情况下,这种方式很有可能导致内存溢出,因此 Flink 该提供了其它方式来存储状态数据,这些存储方式统一称为状态后端 (或状态管理器)
状态后端主要负责两件事:
- 本地状态管理
- 将检查点状态写入远程存储

状态后端主要有以下三种:
1.MemoryStateBackend
- 内存级的状态后端
- 将键控状态作为内存中的对象进行管理,将它们存储在TaskManager的JVM堆上
- 执行checkpoint的时候,会把state的快照数据保存到jobmanager的内存中
- 特点: 高效、低延迟、但不稳定;在生产环境下不建议使用
2.FsStateBackend
基于文件系统进行存储,可以是本地文件系统,也可以是 HDFS 等分布式文件系统。 需要注意而是虽然选择使用了 FsStateBackend ,但正在进行的state数据仍是存储在 TaskManager 的内存中的,只有在 checkpoint 时,才会将state的快照数据写入到指定文件系统(hdfs)上。
特点:同时拥有内存级的访问速度和更好的容错保证可使用hdfs等分布式文件系统
3.RocksDBStateBackend
RocksDBStateBackend 在本地文件系统中维护状态,state会直接写入本地rocksdb中。同时RocksDB需要配置一个远端的filesystem。
uri(一般是HDFS),在做checkpoint的时候,会把本地的数据直接复制到filesystem中。fail over的时候从filesystem中恢复到本地。
RocksDB克服了state受内存限制的缺点,同时又能够持久化到远端文件系统中,比较适合在生产中使用
4.2 一些概念说明:
状态(state):包含算子状态、监控状态,就是task在执行时产生的一些结果数据需要存储起来 (以状态这种形式存储)
检查点(checkpoint): 存储的是应用迄今为止计算后的结果
State Backend(状态的后端存储):
- 默认情况下,state会保存在taskmanager的内存中,checkpoint会存储在JobManager的内存中。
- state的store和checkpoint的位置取决于State Backend的配置(env.setStateBackend(…)
Restart Strategies(重启策略)
- Flink支持不同的重启策略,以便在故障发生时控制作业如何重启
- 集群在启动时会伴随一个默认的重启策略,在没有定义具体重启策略时会使用该默认策略
- 如果在工作提交时指定了一个重启策略,该策略会覆盖集群的默认策略
- 默认的重启策略可通过Flink的配置文件flink-conf.yaml指定(配置参数restart-strategy)
常用的重启策略
- 固定间隔(Fixed delay)
- 失败率(Failure rate)
- 无重启(No restart)
4.3 配置方式
Flink 支持使用两种方式来配置后端管理器:
第一种方式:基于代码方式进行配置,只对当前作业生效:
// 配置 FsStateBackend
env.setStateBackend(new FsStateBackend("hdfs://namenode:40010/flink/checkpoints"));
// 配置 RocksDBStateBackend
env.setStateBackend(new RocksDBStateBackend("hdfs://namenode:port/flink/checkpoints"));
第二种方式:基于 flink-conf.yaml
配置文件的方式进行配置,对所有部署在该集群上的作业都生效:
state.backend: filesystem
state.checkpoints.dir: hdfs://namenode:port/flink/checkpoints
#检查点中保存的数据是否采用增量的方式
state.backend.incremental: false
#flink应用失败后的重启策略
jobmanager.execution.failover-strategy: region
4.4 状态后端效果验证
4.4.1 状态后端之FsStateBackend
特点:
FsStateBackend 状态存储在TaskManager的内存,checkpoint存储在HDFS
4.4.1.1 源码
package com.jd.unbounded.sample_statebackend.a_fs
import java.util.concurrent.TimeUnit
import org.apache.flink.api.common.restartstrategy.RestartStrategies
import org.apache.flink.api.common.time.Time
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.api.scala._
import org.apache.flink.runtime.state.filesystem.FsStateBackend
/**
* Description 状态后端之FsBackendState验证
*
* @author lijun
* @create 2020-03-31
*/
object FsStateBackendTest {
def main(args: Array[String]): Unit = {
//执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//设置状态后端(下述提示api过时的原因,官方推荐配置文件的方式,不建议使用硬编码的方式)
env.setStateBackend(new FsStateBackend("hdfs://node01:9000/flink/state/fs"))
//启用checkpoint
env.enableCheckpointing(10000)
//计算
env.socketTextStream("node01",8888)
.flatMap(_.split("\\s+"))
.filter(_.nonEmpty).map((_,1))
.keyBy(0)
.sum(1)
.print("状态后端之FsBackend")
// 启动
env.execute(this.getClass.getSimpleName)
//设置应用的重启策略(一般在配置文件设定)
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(60,Time.of(10,TimeUnit.SECONDS)))
}
}
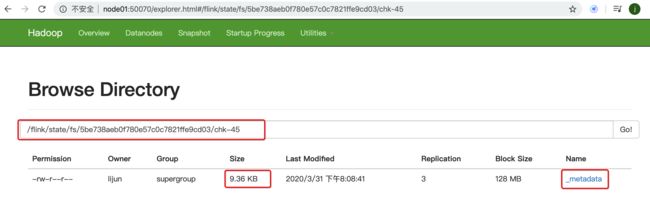
4.4.1.2 效果
存储在hdfs上的情形
4.4.2 状态后端之RocksDBBackend
RocksDBStateBackend状态存储在RocksDB中,checkpoint存储在HDFS
RocksDB是嵌入式的KV对的DB,由facebook开发的,存储的数据庞大且高效
4.4.2.1 RocksDB的使用
第一步:导入依赖
org.rocksdb
rocksdbjni
5.11.3
第二步:通过程序验证数据的写入和读取
package com.jd.unbounded.sample_statebackend.b_rocksdb;
import org.rocksdb.Options;
import org.rocksdb.RocksDB;
import org.rocksdb.RocksDBException;
/**
* Description
* @author lijun
* @create 2020-03-31
*/
public class RocksDBTest {
//因为RocksDB是由C++编写的,在Java中使用首先需要加载Native库
static{
RocksDB.loadLibrary();
}
public static void main(String[] args) throws RocksDBException {
//1.打开数据库
//1.1 创建数据库配置
Options dbOpt = new Options();
//1.2 配置当数据库不存在时自动创建
dbOpt.setCreateIfMissing(true);
//1.3 打开数据库,因为RocksDB默认是保存在本地磁盘,所以需要指定位置
RocksDB rdb = RocksDB.open("/Users/lijun/Downloads/flink_input/rocksdb");
//2.写入数据
//2.1 RocksDB是以字节流的方式写入数据库中,所以我们需要将字符串转换为字节流再写入
byte[] key = "张五".getBytes();
byte[] value = "20".getBytes();
//2.2 调用put方法写入数据
rdb.put(key,value);
System.out.println("写入数据到RocksDB完成");
//3.调用get方法读取数据
System.out.println("从RocksDB读取key="+new String(key)+"的value为"+new String(rdb.get(key)));
//4.移除数据
rdb.delete(key);
//关闭资源
rdb.close();
dbOpt.close();
}
}
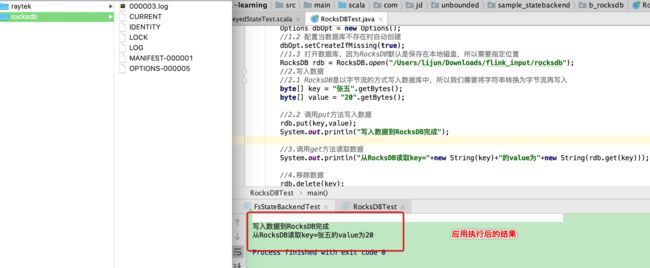
第三步:深度剖析RocksDB数据存储的情况

4.4.2.2 RocksDBStateBackend案例
添加依赖
org.apache.flink
flink-statebackend-rocksdb_2.11
1.9.1
源码
package com.jd.unbounded.sample_statebackend.b_rocksdb
import java.util.concurrent.TimeUnit
import org.apache.flink.api.scala._
import org.apache.flink.api.common.restartstrategy.RestartStrategies
import org.apache.flink.api.common.time.Time
import org.apache.flink.contrib.streaming.state.RocksDBStateBackend
import org.apache.flink.runtime.state.filesystem.FsStateBackend
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
/**
* Description
*
* @author lijun
* @create 2020-03-31
*/
object RocksDBStateBackendTest {
def main(args: Array[String]): Unit = {
//执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//设置状态后端(下述提示api过时的原因,官方推荐配置文件的方式,不建议使用硬编码的方式)
val rocks = new RocksDBStateBackend("hdfs://node01:9000/flink/state/fs",true)
//单独设置RocksDB存储的目录,若是不单独设置,目录在以java.io.tmpdir为key对应的值 (System.getProperty("java.io.tmpdir"))
rocks.setDbStoragePath("/Users/lijun/Downloads/flink_input/statebackend")
env.setStateBackend(rocks)
//启用checkpoint
env.enableCheckpointing(10000)
//计算
env.socketTextStream("node01",8888)
.flatMap(_.split("\\s+"))
.filter(_.nonEmpty).map((_,1))
.keyBy(0)
.sum(1)
.print("状态后端之RocksDBStateBackend")
// 启动
env.execute(this.getClass.getSimpleName)
//设置应用的重启策略(一般在配置文件设定)
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(60,Time.of(10,TimeUnit.SECONDS)))
}
}
效果确认
第一步:确认RocksDB中存储的state值
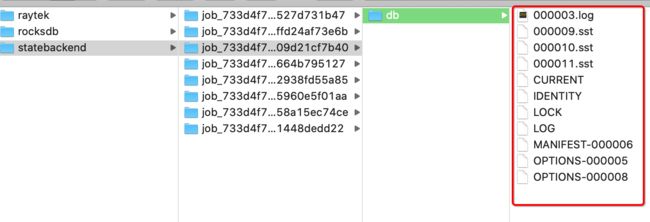
第二步:确认hdfs上对应的checkpoints中的内容
