CNN网络结构发展演变:从LeNet到HRNet(一)
个人经验总结博客,写的不好的地方还请各路大神指正,不喜勿喷。网络结构图基本都是引用的,如有雷同,实在抱歉,可在下方评论中留言是否删除。
我们知道CNN网络结构一直在更新迭代,卷积可以理解为:“瞬时行为的持续性后果”,现在花点时间整理下CNN网络结构的发展演化。
首先说下一般CNN的网络结构组成:
1)卷积层
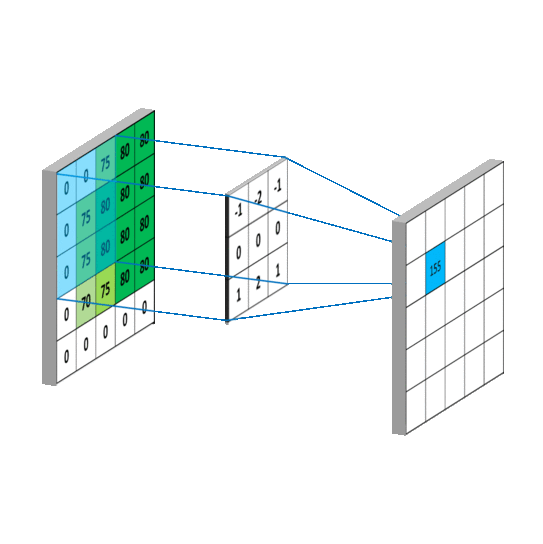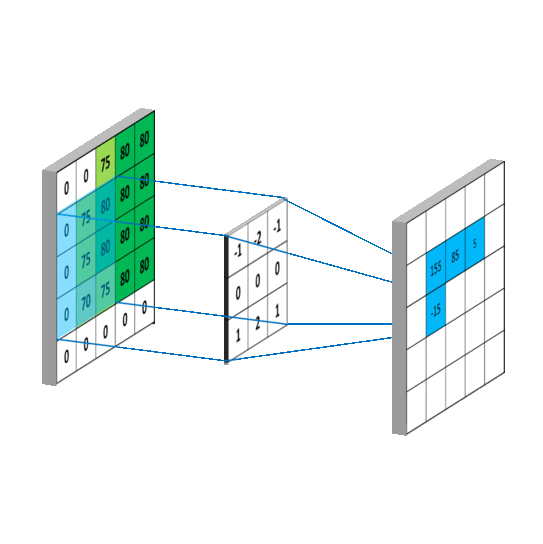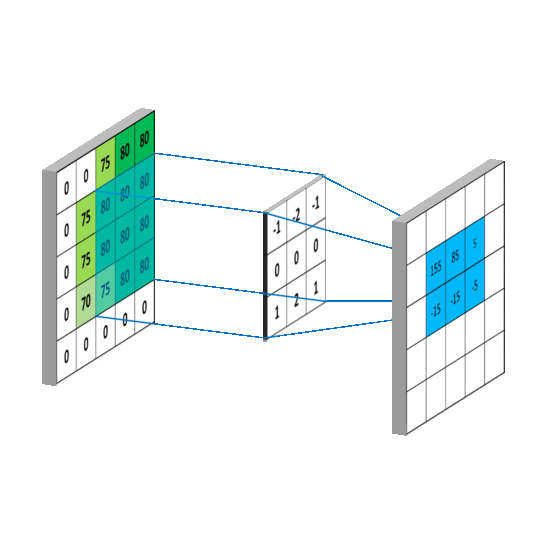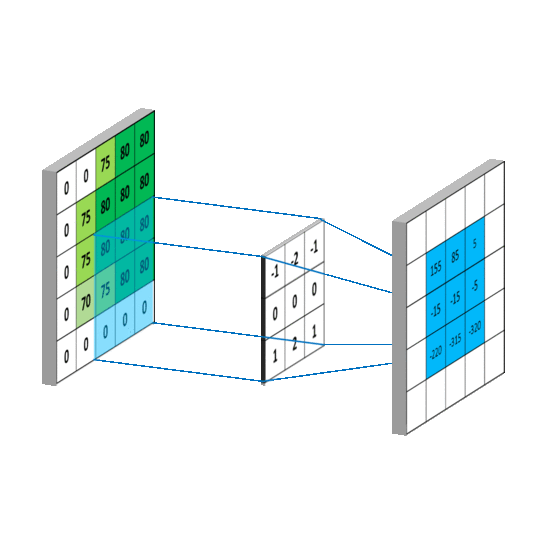
假设输入通道C_in, 输入通道H x W,输出通道C_out, kernal size设置为K。
(1) 普通卷积
按照如上参数,普通卷积的参数量是:
C_in x H x W x C_out
(2) Pointwise convolution
一般用于改变通道数。
(3) Depthwise Convolution
深度卷积的参数量一般是:
C_in×K×KxC_out / C_out
(4) 分组卷积(Group convolution)
分组卷积顾名思义就是将卷积分成G个组并行计算,计算量是:
C_in×K×KxC_out / G
每个组得到的特征图通过concat得到最终的输出feature map.
(5空间或者深度可分离卷积(Channelwise or Depthwise separable convolution)
空间可分离卷积的意思就是:将一个普通的卷积核分成Kx1和1xK这种科分离的卷积核。
而深度可分离卷积其实跟分组卷积有点像,是由深度卷积和点卷积搭配的一个结构,深度卷积是也是分组卷积,Group就是输出通道数C_out, 紧跟着后面是点卷积,故其参数量是:
C_in×K×K+C_out×1×1.
(6) 膨胀(空洞)卷积(Dilated convolution)

这是一个由语义分割而产生的卷积结构,一般我们下采样都是采用pooling池化层,但是pooling池化层往往造成不可逆的特征丢失,而为了不造成不可逆的特征丢失,我们可以不用pooling层,但这样又会造成计算量过大,而既为了有下采样,又不让计算量过大,这个时候空洞卷积就产生了。我们知道普通卷积的dilated_rate=1,空洞卷积的膨胀率即dilated_rate > 1,我们可以理解为漏筛型结构,两两卷积核之间相差dilated-1的距离。如上所示就是dilated_rate=2的空洞卷积。
(7) 转置卷积(Deconvolution)
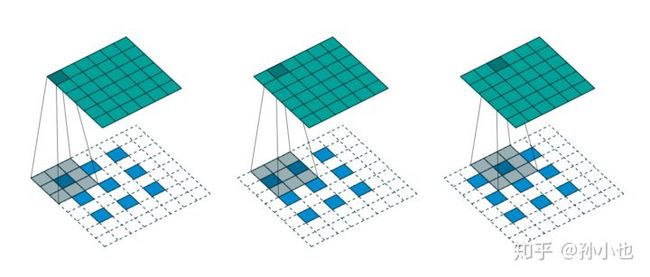
转置卷积也叫反卷积,顾名思义,就是跟正常的普通卷积相反的过程,跟膨胀卷积的区别是:膨胀卷积是kernel卷积核空洞,而反卷积是输入空洞。一般反卷积用于upsampling。除了反卷积以外,还有双线性插值,也可以起到upsample的作用。
2) 池化层
最大池化(MaxPooling)、平均池化(AveragePooling), 全局平均池化(GAP:Global AveragePooling)
池化的作用就是下采样,最大池化就是选取以stride为步长,K x K大小的核选取K x K范围内的最大值,平均池化就是计算K x K范围内的平均值。
全局平均池化层一般用于替代全连接层,全连接层计算量大且容易引起过拟合(如Alexnet)。而全局平均池化层则直接取整张feature map的均值,也没什么计算量,也避免了过拟合。
3) 激活层
激活函数的作用就是增加神经网络的非线性。这一部分可以单独讲讲。
4) BN层
机器学习领域有个很重要的假设:IID独立同分布假设,就是假设训练数据和测试数据是满足相同分布的,这是通过训练数据获得的模型能够在测试集获得好的效果的一个基本保障。那BatchNorm的作用是什么呢?BatchNorm就是在深度神经网络训练过程中使得每一层神经网络的输入保持相同分布的。

5) Dropout层
Dropout层曾有人 类比于无性繁殖和有性繁殖,按理来说无性繁殖直接延续优秀基因存活率应该会比无性繁殖高,但实际却是有性繁殖的存活率高得多,原因或许就是有性繁殖将基因联合适应性减小,适应性更强。Dropout就像是强迫一个神经单元,和随机挑选出来的其他神经单元共同工作,达到好的效果。消除减弱了神经元节点间的联合适应性,增强了泛化能力。
6) Disout层

相比于Dropout以一定概率停止某个神经元的激活,disout是采用是一种新型的特征图扰动的方法来增强神经网络的泛化能力。目前disout在多项任务上,其效果优于dropout,比如在ImageNet上训练的ResNet-50可以达到78.76%的准确率,而谷歌Dropout系列方法仅为76.8%。
开源链接:https://github.com/huawei-noah/Disout
论文链接:https://www.aaai.org/Papers/AAAI/2020GB/AAAI-TangY.402.pdf
1. LeNet
网络结构图:由两个卷积层,两个全连接层,和一个输出层组成。
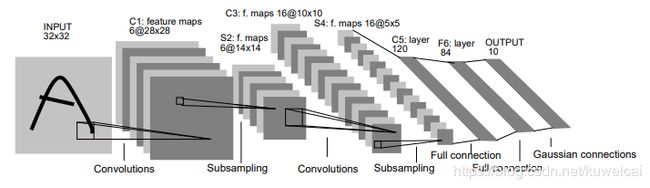
2. AlexNet
3. VGGNet
4. GoogleNet
5.Inceptionv1-Inceptionv4
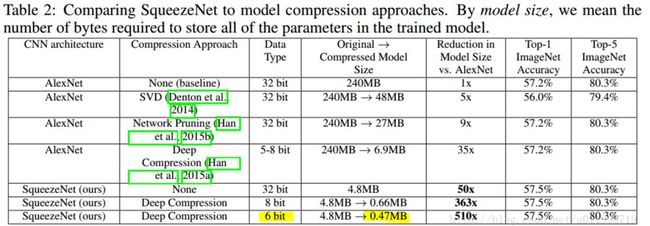
6. SqueezeNet
SqueezeNet是有fire module组成,fire module是由squeeze层和Expand层组成,squeeze层就是1x1的卷积层,expand层是由1x1卷积核的卷积层和 3x3 卷积核的卷积层,最后将两者的feature map进行concat。

Squeeze的网络结构表和参数量如下所示:
7. XceptionNet

8. MobileNetv1-MobileNetv3
MobileNet得益于Separable Conv的使用,其中大量使用深度可分离卷积(3 x 3的depthwise GConv -- 1 x 1的pointwise conv)和1 x 1的pointwise conv -- 3 x 3的depthwise GConv -- 1 x 1的pointwise conv网络结构,极大的减少参数量,并保证了较好的精度。激活函数也是从v1中的ReLU换成了v3中的hswish激活函数。另外v3中增加了SE-Net模块,SE-Net通过自适应地重新校准通道特征响应来引入通道注意力(channel-attention)机制。包括下面的ResNeSt也是用到了注意力机制,不同的是,SE-Net引入的是通道注意力机制,而ResNeSt 实际上是站在巨人们上的"集大成者",特别借鉴了:Multi-path 和 Feature-map Attention思想。
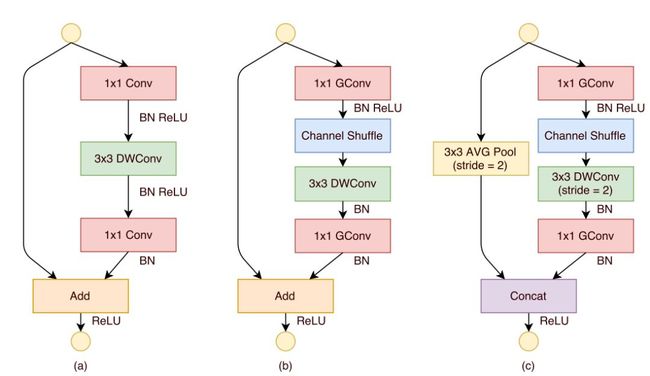
9. ShuffleNetv1-v3
ShufflentNet也用了separable conv和1-3-1的网络block,除此之外还用到了通道shuffle,增强了模型的泛化性能,并减少了计算量。
10. NasNet
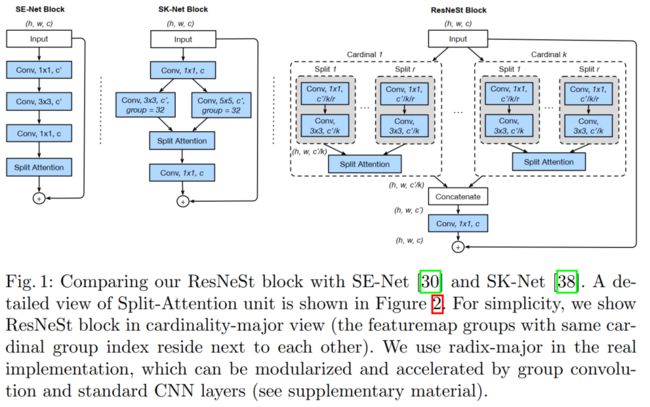
11. ResNet及其变体,Res2Next, ResNeXt,ResNeSt
ResNet是He Kaiming发明的网络结构,至今都是流传甚广,目前各种变体还都是采用了ResNet中的经典残差模块。目前刷新ResNet变体中最佳的网络结构是ResNeSt,这是一种基于split attention模块的网络结构。
ResNet通过前层与后层的“短路连接”(Shortcuts),加强了前后层之间的信息流通,在一定程度上缓解了梯度消失现象,从而可以将神经网络搭建得很深。
1) ResNet

2) ResNeSt
12. DenseNet及其变体:PeleeNet、VoVNet

13. NasNet/MNasNet
13. EfficientNet/EfficientNet-Lite和EfficientDet
EfficientNet据说是目前兼具速度和精度的网络结构模型,
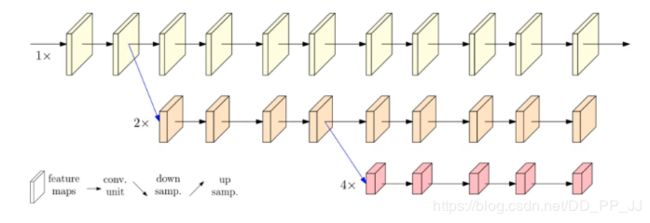
14. HRNet
普通的网络结构是采用串联的方式将卷积层串联起来:
而HRNet则是采用并联的方式,并且将不同分辨率的feature map之间进行融合fuse。