使用Python进行OCR文字识别
从零开始OCR字符识别
出发目的:
期末快到了,各种各样的水课都布置了写文章写报告的作业,这对于我来说简直就是噩梦,上网参考文章想要引用但是又受限于图片格式和复制限制,所以我就想着使用ocr识别。
本文就来讲讲如何使用python和ocr将图片转化为文本。
本文参考wzgg的一篇博客,欢迎看wzgg博客
当然也欢迎来看我的博客
调用百度的OCR接口进行字符之别
注册账号点击跳转并创建 图像识别 > 通用文字识别 应用。


下载
pip3 install baidu-aip
pip和pip3没有本质区别,只是为了区别python2和python3.
![]()
解释器from aip import AipOcr,没有报错就可以了(这里wzgg的博客里有点问题)
![]()
因为暂时还没有系统学过python 这里就直接在wzgg的代码基础上进行修改了 也算是一种学习吧
from aip import AipOcr
import sys,os
from urllib.request import urlopen
APP_ID = '输入你的'
API_KEY = '输入你的'
SECRET_KEY = '输入你的'
client = AipOcr(APP_ID, API_KEY, SECRET_KEY)
length = len(sys.argv)
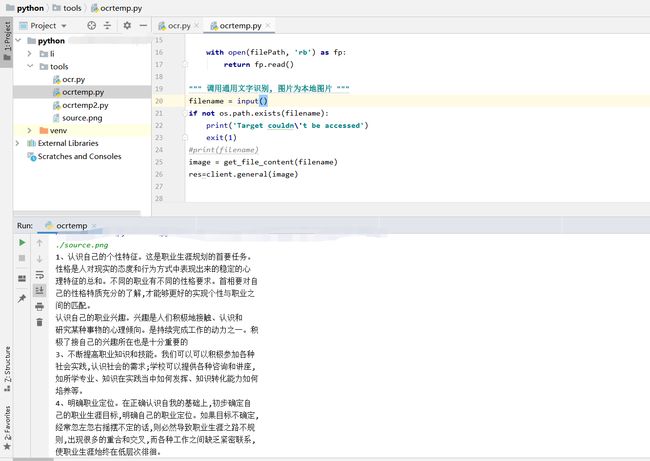
""" 读取图片 """
def get_file_content(filePath):
with open(filePath, 'rb') as fp:
return fp.read()
""" 调用通用文字识别, 图片为本地图片 """
filename = input()
if not os.path.exists(filename):
print('Target couldn\'t be accessed')
exit(1)
#print(filename)
image = get_file_content(filename)
res=client.general(image)
for item in res['words_result']:
print(item['words'])
我实现的是本地的ocr识别只需要在运行时输入图片地址即可。
下面给出我的成功示例。