NLP实战-中文命名实体识别
前言:
本项目将通过pytorch作为主要工具实现不同的模型(包括HMM,CRF,Bi-LSTM,Bi-LSTM+CRF)来解决中文命名实体识别问题,文章不会涉及过多的数学推导,但会从直观上简单解释模型的原理,主要 的内容会集中在代码部分。
本文的目录结构如下:
文章目录
- 概览
- 任务描述
- 数据集
- 运行结果
- 统计学习的方法
- 条件随机场(Conditional Random Field, CRF)
- 深度学习的方法
- Bi-LSTM
- Bi-LSTM+CRF
- 代码中一些需要注意的点
概览
任务描述
首先,我们明确一下命名实体识别的概念:
命名实体识别(英语:Named Entity Recognition,简称NER,是指识别文本中具有特定意义的实体,主要包括人名、地名、机构名、专有名词等,以及时间、数量、货币、比例数值等文字。
举个例子,假如有这么一句话:
ACM宣布,深度学习的三位创造者Yoshua Bengio, Yann LeCun, 以及Geoffrey Hinton获得了2019年的图灵奖。
那么NER的任务就是从这句话中提取出
- 机构名:ACM
- 人名:Yoshua Bengio, Yann LeCun,Geoffrey Hinton
- 时间:2019年
- 专有名词:图灵奖
目前在NER上表现较好的模型都是基于深度学习或者是统计学习的方法的,这些方法共同的特点都是需要大量的数据来进行学习,所以接下来我先介绍一下本项目使用的数据集的格式,好让读者在阅读模型的代码之前对数据的形式有个直观的认识。
数据集
数据集用的是论文ACL 2018Chinese NER using Lattice LSTM中从新浪财经收集的简历数据,数据的格式如下,它的每一行由一个字及其对应的标注组成,标注集采用BIOES(B表示实体开头,E表示实体结尾,I表示在实体内部,O表示非实体),句子之间用一个空行隔开。
美 B-LOC
国 E-LOC
的 O
华 B-PER
莱 I-PER
士 E-PER
我 O
跟 O
他 O
谈 O
笑 O
风 O
生 O
运行结果
下面是四种不同的模型以及这Ensemble这四个模型预测结果的准确率(取最好):
| HMM | CRF | BiLSTM | BiLSTM+CRF | Ensemble | |
|---|---|---|---|---|---|
| 准确率 | 91.22% | 95.43% | 95.44% | 95.75% | 95.89% |
最后一列Ensemble是将这四个模型的预测结果结合起来,使用“投票表决”的方法得出最后的预测结果。
下面本文将详细接受每种模型的实现:
统计学习的方法
### 隐马尔可夫模型(Hidden Markov Model,HMM)
隐马尔可夫模型描述由一个隐藏的马尔科夫链随机生成不可观测的状态随机序列,再由各个状态生成一个观测而产生观测随机序列的过程(李航 统计学习方法)。隐马尔可夫模型由初始状态分布,状态转移概率矩阵以及观测概率矩阵所确定。
上面的定义太过学术看不懂没关系,我们只需要知道,NER本质上可以看成是一种序列标注问题(预测每个字的BIOES标记),在使用HMM解决NER这种序列标注问题的时候,我们所能观测到的是字组成的序列(观测序列),观测不到的是每个字对应的标注(状态序列)。
对应的,HMM的三个要素可以解释为,初始状态分布就是每一个标注作为句子第一个字的标注的概率,状态转移概率矩阵就是由某一个标注转移到下一个标注的概率(设状态转移矩阵为 M M M,那么若前一个词的标注为 t a g i tag_i tagi ,则下一个词的标注为 t a g j tag_j tagj的概率为 M i j M_{ij} Mij),观测概率矩阵就是指在某个标注下,生成某个词的概率。根据HMM的三个要素,我们可以定义如下的HMM模型:
class HMM(object):
def __init__(self, N, M):
"""Args:
N: 状态数,这里对应存在的标注的种类
M: 观测数,这里对应有多少不同的字
"""
self.N = N
self.M = M
# 状态转移概率矩阵 A[i][j]表示从i状态转移到j状态的概率
self.A = torch.zeros(N, N)
# 观测概率矩阵, B[i][j]表示i状态下生成j观测的概率
self.B = torch.zeros(N, M)
# 初始状态概率 Pi[i]表示初始时刻为状态i的概率
self.Pi = torch.zeros(N)
有了模型定义,接下来的问题就是训练模型了。HMM模型的训练过程对应隐马尔可夫模型的学习问题(李航 统计学习方法),实际上就是根据训练数据根据最大似然的方法估计模型的三个要素,即上文提到的初始状态分布、状态转移概率矩阵以及观测概率矩阵。举个例子帮助理解,在估计初始状态分布的时候,假如某个标记在数据集中作为句子第一个字的标记的次数为k,句子的总数为N,那么该标记作为句子第一个字的概率可以近似估计为k/N,很简单对吧,使用这种方法,我们近似估计HMM的三个要素,代码如下(出现过的函数将用省略号代替):
class HMM(object):
def __init__(self, N, M):
....
def train(self, word_lists, tag_lists, word2id, tag2id):
"""HMM的训练,即根据训练语料对模型参数进行估计,
因为我们有观测序列以及其对应的状态序列,所以我们
可以使用极大似然估计的方法来估计隐马尔可夫模型的参数
参数:
word_lists: 列表,其中每个元素由字组成的列表,如 ['担','任','科','员']
tag_lists: 列表,其中每个元素是由对应的标注组成的列表,如 ['O','O','B-TITLE', 'E-TITLE']
word2id: 将字映射为ID
tag2id: 字典,将标注映射为ID
"""
assert len(tag_lists) == len(word_lists)
# 估计转移概率矩阵
for tag_list in tag_lists:
seq_len = len(tag_list)
for i in range(seq_len - 1):
current_tagid = tag2id[tag_list[i]]
next_tagid = tag2id[tag_list[i+1]]
self.A[current_tagid][next_tagid] += 1
# 一个重要的问题:如果某元素没有出现过,该位置为0,这在后续的计算中是不允许的
# 解决方法:我们将等于0的概率加上很小的数
self.A[self.A == 0.] = 1e-10
self.A = self.A / self.A.sum(dim=1, keepdim=True)
# 估计观测概率矩阵
for tag_list, word_list in zip(tag_lists, word_lists):
assert len(tag_list) == len(word_list)
for tag, word in zip(tag_list, word_list):
tag_id = tag2id[tag]
word_id = word2id[word]
self.B[tag_id][word_id] += 1
self.B[self.B == 0.] = 1e-10
self.B = self.B / self.B.sum(dim=1, keepdim=True)
# 估计初始状态概率
for tag_list in tag_lists:
init_tagid = tag2id[tag_list[0]]
self.Pi[init_tagid] += 1
self.Pi[self.Pi == 0.] = 1e-10
self.Pi = self.Pi / self.Pi.sum()
模型训练完毕之后,要利用训练好的模型进行解码,就是对给定的模型未见过的句子,求句子中的每个字对应的标注,针对这个解码问题,我们使用的是维特比(viterbi)算法。关于该算法的数学推导,可以查阅一下李航统计学习方法10.4.2,或者是Speech and Language Processing8.4.5,这两本参考书都讲的十分详细并且容易理解,建议阅读过相关部分再来看看代码加深理解。
它实现的细节如下:
class HMM(object):
...
def decoding(self, word_list, word2id, tag2id):
"""
使用维特比算法对给定观测序列求状态序列, 这里就是对字组成的序列,求其对应的标注。
维特比算法实际是用动态规划解隐马尔可夫模型预测问题,即用动态规划求概率最大路径(最优路径)
这时一条路径对应着一个状态序列
"""
# 问题:整条链很长的情况下,十分多的小概率相乘,最后可能造成下溢
# 解决办法:采用对数概率,这样源空间中的很小概率,就被映射到对数空间的大的负数
# 同时相乘操作也变成简单的相加操作
A = torch.log(self.A)
B = torch.log(self.B)
Pi = torch.log(self.Pi)
# 初始化 维比特矩阵viterbi 它的维度为[状态数, 序列长度]
# 其中viterbi[i, j]表示标注序列的第j个标注为i的所有单个序列(i_1, i_2, ..i_j)出现的概率最大值
seq_len = len(word_list)
viterbi = torch.zeros(self.N, seq_len)
# backpointer是跟viterbi一样大小的矩阵
# backpointer[i, j]存储的是 标注序列的第j个标注为i时,第j-1个标注的id
# 等解码的时候,我们用backpointer进行回溯,以求出最优路径
backpointer = torch.zeros(self.N, seq_len).long()
# self.Pi[i] 表示第一个字的标记为i的概率
# Bt[word_id]表示字为word_id的时候,对应各个标记的概率
# self.A.t()[tag_id]表示各个状态转移到tag_id对应的概率
# 所以第一步为
start_wordid = word2id.get(word_list[0], None)
Bt = B.t()
if start_wordid is None:
# 如果字不再字典里,则假设状态的概率分布是均匀的
bt = torch.log(torch.ones(self.N) / self.N)
else:
bt = Bt[start_wordid]
viterbi[:, 0] = Pi + bt
backpointer[:, 0] = -1
# 递推公式:
# viterbi[tag_id, step] = max(viterbi[:, step-1]* self.A.t()[tag_id] * Bt[word])
# 其中word是step时刻对应的字
# 由上述递推公式求后续各步
for step in range(1, seq_len):
wordid = word2id.get(word_list[step], None)
# 处理字不在字典中的情况
# bt是在t时刻字为wordid时,状态的概率分布
if wordid is None:
# 如果字不再字典里,则假设状态的概率分布是均匀的
bt = torch.log(torch.ones(self.N) / self.N)
else:
bt = Bt[wordid] # 否则从观测概率矩阵中取bt
for tag_id in range(len(tag2id)):
max_prob, max_id = torch.max(
viterbi[:, step-1] + A[:, tag_id],
dim=0
)
viterbi[tag_id, step] = max_prob + bt[tag_id]
backpointer[tag_id, step] = max_id
# 终止, t=seq_len 即 viterbi[:, seq_len]中的最大概率,就是最优路径的概率
best_path_prob, best_path_pointer = torch.max(
viterbi[:, seq_len-1], dim=0
)
# 回溯,求最优路径
best_path_pointer = best_path_pointer.item()
best_path = [best_path_pointer]
for back_step in range(seq_len-1, 0, -1):
best_path_pointer = backpointer[best_path_pointer, back_step]
best_path_pointer = best_path_pointer.item()
best_path.append(best_path_pointer)
# 将tag_id组成的序列转化为tag
assert len(best_path) == len(word_list)
id2tag = dict((id_, tag) for tag, id_ in tag2id.items())
tag_list = [id2tag[id_] for id_ in reversed(best_path)]
return tag_list
以上就是HMM的实现了,全部代码可见文末。
条件随机场(Conditional Random Field, CRF)
上面讲的HMM模型中存在两个假设,一是输出观察值之间严格独立,二是状态转移过程中当前状态只与前一状态有关。也就是说,在命名实体识别的场景下,HMM认为观测到的句子中的每个字都是相互独立的,而且当前时刻的标注只与前一时刻的标注相关。但实际上,命名实体识别往往需要更多的特征,比如词性,词的上下文等等,同时当前时刻的标注应该与前一时刻以及后一时刻的标注都相关联。由于这两个假设的存在,显然HMM模型在解决命名实体识别的问题上是存在缺陷的。
而条件随机场就没有这种问题,它通过引入自定义的特征函数,不仅可以表达观测之间的依赖,还可表示当前观测与前后多个状态之间的复杂依赖,可以有效克服HMM模型面临的问题。
下面是条件随机场的数学形式(如果觉得不好理解。也可以直接跳到代码部分):
为了建立一个条件随机场,我们首先要定义一个特征函数集,该函数集内的每个特征函数都以标注序列作为输入,提取的特征作为输出。假设该函数集为:
![]()
其中 x = ( x 1 , . . . , x m ) x=(x_1, ..., x_m) x=(x1,...,xm)表示观测序列, s = ( s 1 , . . . . , s m ) s = (s_1, ...., s_m) s=(s1,....,sm)表示状态序列。然后,条件随机场使用对数线性模型来计算给定观测序列下状态序列的条件概率:

其中 s ′ s^{'} s′是是所有可能的状态序列, w w w是条件随机场模型的参数,可以把它看成是每个特征函数的权重。CRF模型的训练其实就是对参数 w w w的估计。假设我们有 n n n个已经标注好的数据 { ( x i , s i ) } i = 1 n \{(x^i, s^i)\}_{i=1}^n {(xi,si)}i=1n,
则其对数似然函数的正则化形式如下:

那么,最优参数 w ∗ w^* w∗就是:

模型训练结束之后,对给定的观测序列 x x x,它对应的最优状态序列应该是:
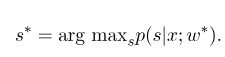
解码的时候与HMM类似,也可以采用维特比算法。
下面是代码实现:
from sklearn_crfsuite import CRF # CRF的具体实现太过复杂,这里我们借助一个外部的库
def word2features(sent, i):
"""抽取单个字的特征"""
word = sent[i]
prev_word = "" if i == 0 else sent[i-1]
next_word = "" if i == (len(sent)-1) else sent[i+1]
# 因为每个词相邻的词会影响这个词的标记
# 所以我们使用:
# 前一个词,当前词,后一个词,
# 前一个词+当前词, 当前词+后一个词
# 作为特征
features = {
'w': word,
'w-1': prev_word,
'w+1': next_word,
'w-1:w': prev_word+word,
'w:w+1': word+next_word,
'bias': 1
}
return features
def sent2features(sent):
"""抽取序列特征"""
return [word2features(sent, i) for i in range(len(sent))]
class CRFModel(object):
def __init__(self,
algorithm='lbfgs',
c1=0.1,
c2=0.1,
max_iterations=100,
all_possible_transitions=False
):
self.model = CRF(algorithm=algorithm,
c1=c1,
c2=c2,
max_iterations=max_iterations,
all_possible_transitions=all_possible_transitions)
def train(self, sentences, tag_lists):
"""训练模型"""
features = [sent2features(s) for s in sentences]
self.model.fit(features, tag_lists)
def test(self, sentences):
"""解码,对给定句子预测其标注"""
features = [sent2features(s) for s in sentences]
pred_tag_lists = self.model.predict(features)
return pred_tag_lists
深度学习的方法
Bi-LSTM
除了以上两种基于概率图模型的方法,LSTM也常常被用来解决序列标注问题。和HMM、CRF不同的是,LSTM是依靠神经网络超强的非线性拟合能力,在训练时将样本通过高维空间中的复杂非线性变换,学习到从样本到标注的函数,之后使用这个函数为指定的样本预测每个token的标注。下方就是使用双向LSTM(双向能够更好的捕捉序列之间的依赖关系)进行序列标注的示意图:

LSTM比起CRF模型最大的好处就是简单粗暴,不需要做繁杂的特征工程,直接训练即可,同时比起HMM,LSTM的准确率也比较高。
下面是基于双向LSTM的序列标注模型的实现:
import torch
import torch.nn as nn
from torch.nn.utils.rnn import pad_packed_sequence, pack_padded_sequence
class BiLSTM(nn.Module):
def __init__(self, vocab_size, emb_size, hidden_size, out_size):
"""初始化参数:
vocab_size:字典的大小
emb_size:词向量的维数
hidden_size:隐向量的维数
out_size:标注的种类
"""
super(BiLSTM, self).__init__()
self.embedding = nn.Embedding(vocab_size, emb_size)
self.bilstm = nn.LSTM(emb_size, hidden_size,
batch_first=True,
bidirectional=True)
self.lin = nn.Linear(2*hidden_size, out_size)
def forward(self, sents_tensor, lengths):
emb = self.embedding(sents_tensor) # [B, L, emb_size]
packed = pack_padded_sequence(emb, lengths, batch_first=True)
rnn_out, _ = self.bilstm(packed)
# rnn_out:[B, L, hidden_size*2]
rnn_out, _ = pad_packed_sequence(rnn_out, batch_first=True)
scores = self.lin(rnn_out) # [B, L, out_size]
return scores
def test(self, sents_tensor, lengths, _):
"""解码"""
logits = self.forward(sents_tensor, lengths) # [B, L, out_size]
_, batch_tagids = torch.max(logits, dim=2)
return batch_tagid
Bi-LSTM+CRF
简单的LSTM的优点是能够通过双向的设置学习到观测序列(输入的字)之间的依赖,在训练过程中,LSTM能够根据目标(比如识别实体)自动提取观测序列的特征,但是缺点是无法学习到状态序列(输出的标注)之间的关系,要知道,在命名实体识别任务中,标注之间是有一定的关系的,比如B类标注(表示某实体的开头)后面不会再接一个B类标注,所以LSTM在解决NER这类序列标注任务时,虽然可以省去很繁杂的特征工程,但是也存在无法学习到标注上下文的缺点。
相反,CRF的优点就是能对隐含状态建模,学习状态序列的特点,但它的缺点是需要手动提取序列特征。所以一般的做法是,在LSTM后面再加一层CRF,以获得两者的优点。
下面是给Bi-LSTM加一层CRF的代码实现:
class BiLSTM_CRF(nn.Module):
def __init__(self, vocab_size, emb_size, hidden_size, out_size):
"""初始化参数:
vocab_size:字典的大小
emb_size:词向量的维数
hidden_size:隐向量的维数
out_size:标注的种类
"""
super(BiLSTM_CRF, self).__init__()
# 这里的BiLSTM就是LSTM模型部分所定义的BiLSTM模型
self.bilstm = BiLSTM(vocab_size, emb_size, hidden_size, out_size)
# CRF实际上就是多学习一个转移矩阵 [out_size, out_size] 初始化为均匀分布
self.transition = nn.Parameter(
torch.ones(out_size, out_size) * 1/out_size)
# self.transition.data.zero_()
def forward(self, sents_tensor, lengths):
# [B, L, out_size]
emission = self.bilstm(sents_tensor, lengths)
# 计算CRF scores, 这个scores大小为[B, L, out_size, out_size]
# 也就是每个字对应对应一个 [out_size, out_size]的矩阵
# 这个矩阵第i行第j列的元素的含义是:上一时刻tag为i,这一时刻tag为j的分数
batch_size, max_len, out_size = emission.size()
crf_scores = emission.unsqueeze(
2).expand(-1, -1, out_size, -1) + self.transition.unsqueeze(0)
return crf_scores
def test(self, test_sents_tensor, lengths, tag2id):
"""使用维特比算法进行解码"""
start_id = tag2id['' ]
end_id = tag2id['' ]
pad = tag2id['' ]
tagset_size = len(tag2id)
crf_scores = self.forward(test_sents_tensor, lengths)
device = crf_scores.device
# B:batch_size, L:max_len, T:target set size
B, L, T, _ = crf_scores.size()
# viterbi[i, j, k]表示第i个句子,第j个字对应第k个标记的最大分数
viterbi = torch.zeros(B, L, T).to(device)
# backpointer[i, j, k]表示第i个句子,第j个字对应第k个标记时前一个标记的id,用于回溯
backpointer = (torch.zeros(B, L, T).long() * end_id).to(device)
lengths = torch.LongTensor(lengths).to(device)
# 向前递推
for step in range(L):
batch_size_t = (lengths > step).sum().item()
if step == 0:
# 第一个字它的前一个标记只能是start_id
viterbi[:batch_size_t, step,
:] = crf_scores[: batch_size_t, step, start_id, :]
backpointer[: batch_size_t, step, :] = start_id
else:
max_scores, prev_tags = torch.max(
viterbi[:batch_size_t, step-1, :].unsqueeze(2) +
crf_scores[:batch_size_t, step, :, :], # [B, T, T]
dim=1
)
viterbi[:batch_size_t, step, :] = max_scores
backpointer[:batch_size_t, step, :] = prev_tags
# 在回溯的时候我们只需要用到backpointer矩阵
backpointer = backpointer.view(B, -1) # [B, L * T]
tagids = [] # 存放结果
tags_t = None
for step in range(L-1, 0, -1):
batch_size_t = (lengths > step).sum().item()
if step == L-1:
index = torch.ones(batch_size_t).long() * (step * tagset_size)
index = index.to(device)
index += end_id
else:
prev_batch_size_t = len(tags_t)
new_in_batch = torch.LongTensor(
[end_id] * (batch_size_t - prev_batch_size_t)).to(device)
offset = torch.cat(
[tags_t, new_in_batch],
dim=0
) # 这个offset实际上就是前一时刻的
index = torch.ones(batch_size_t).long() * (step * tagset_size)
index = index.to(device)
index += offset.long()
tags_t = backpointer[:batch_size_t].gather(
dim=1, index=index.unsqueeze(1).long())
tags_t = tags_t.squeeze(1)
tagids.append(tags_t.tolist())
# tagids:[L-1](L-1是因为扣去了end_token),大小的liebiao
# 其中列表内的元素是该batch在该时刻的标记
# 下面修正其顺序,并将维度转换为 [B, L]
tagids = list(zip_longest(*reversed(tagids), fillvalue=pad))
tagids = torch.Tensor(tagids).long()
# 返回解码的结果
return tagids
以上就是这四个模型的具体实现了,模型的效果比较在前面已经给出了。
全部的代码地址在 https://github.com/luopeixiang/named_entity_recognition
(这个项目后续会尝试使用其他模型来做这个问题,如果觉得有帮助可以点个star哦~)
本文同步发于知乎文章: https://zhuanlan.zhihu.com/p/61227299
代码中一些需要注意的点
-
HMM模型中要处理OOV(Out of vocabulary)的问题,就是测试集里面有些字是不在训练集里面的,
这个时候通过观测概率矩阵是无法查询到OOV对应的各种状态的概率的,处理这个问题可以将OOV对应的状态的概率分布设为均匀分布。 -
HMM的三个参数(即状态转移概率矩阵、观测概率矩阵以及初始状态概率矩阵)在使用监督学习方法进行估计的过程中,如果有些项从未出现,那么该项对应的位置就为0,而在使用维特比算法进行解码的时候,计算过程需要将这些值相乘,那么如果其中有为0的项,那么整条路径的概率也变成0了。此外,解码过程中多个小概率相乘很可能出现下溢的情况,为了解决这两个问题,我们给那些从未出现过的项赋予一个很小的数(如0.00000001),同时在进行解码的时候将模型的三个参数都映射到对数空间,这样既可以避免下溢,又可以简化乘法运算。
-
CRF中将训练数据以及测试数据作为模型的输入之前,都需要先用特征函数提取特征!
-
Bi-LSTM+CRF模型可以参考:Neural Architectures for Named Entity Recognition,可以重点看一下里面的损失函数的定义。代码里面关于损失函数的计算采用的是类似动态规划的方法,不是很好理解,这里推荐看一下以下这些博客:
- CRF Layer on the Top of BiLSTM - 5
- Bi-LSTM-CRF for Sequence Labeling PENG
- Pytorch Bi-LSTM + CRF 代码详解