Anchor-free Object Detector综述(不定时更新)
DenseBox (2015) (https://arxiv.org/abs/1509.04874)
densebox最早提出来是用来检测人脸的, 其有两个主要贡献, 第一是提出使用一个完整的FCN来预测box而不需要预先的proposal, 而且是end2end的训练过程; 第二是提出了用目标上已有的关键点信息来辅助box的定位.
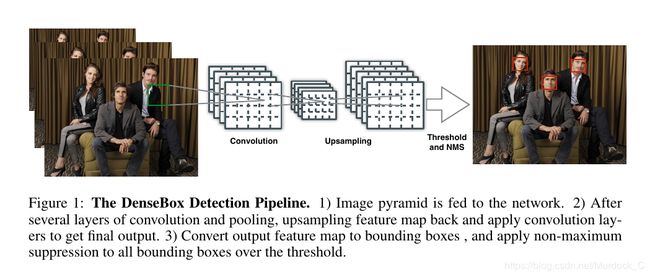
为了节省训练时间, densebox没有直接把一整张图片都丢进去训练, 而是在目标周围裁剪出240240大小的patch丢进去训练, 最后输出6060*5的输出, 每个featuremap上的位置产生一个5d vector, 代表 (score, d x t d_{xt} dxt, d y t d_{yt} dyt, d x b d_{xb} dxb, d y b d_{yb} dyb), score就是该点的confidence, 0~1之间; ( d x t d_{xt} dxt, d y t d_{yt} dyt)就是该点离gt box左上角的距离, ( d x b d_{xb} dxb, d y b d_{yb} dyb)就是该点离gt box右下角的距离. 在计算loss的时候, 类似于fast rcnn, 会把离真值点距离为2以内的点作为忽略区域, 在计算loss的时候权重为0. 对于离真值很远的点, 选取top 1%的点参与bp(根据计算出来的loss).

以检测人脸为例, densebox加入了人脸周围的72个关键点信息, 用来和最后输出的score heatmap相加来对score heatmap进行refine. densebox虽然在2015年就提出anchor-free的思想, 但由于其没有开源, 并且当时fast-rcnn几乎同一时间放出全部代码, 因此大家都转向了rcnn系列, 直到最近anchor-free的思想又被重新刷起来.

CornerNet (2018) (https://arxiv.org/abs/1808.01244)
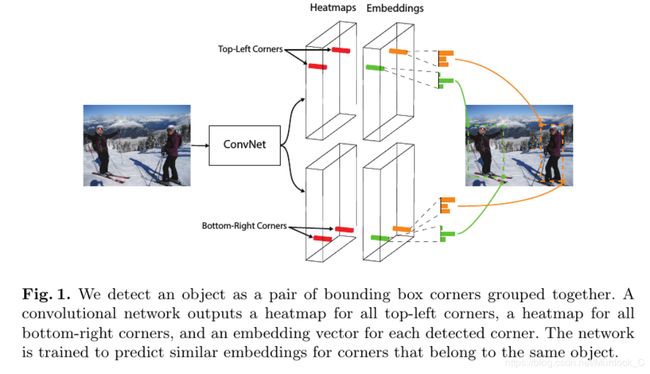
CornerNet采取了类似检测关键点的方法来检测框. 从流程图上可以看出, 模型最后的输出有三种, 一个是top-left corner, 一个是bottom-right corner, 还有一个是embedding vector. 模型会根据embedding vector来判断哪两个top-left和bottom-right点应该连在一起. 首先说明一下这个embedding vector, 这个embedding vector的具体值不重要, 重要的网络需要学习到:1. 同一个object的embedding vector尽可能相近; 2. 不同object的embedding vector尽可能差距过大.这样就可以把不同object的top-left corner和bottom-right corner区分开来. 这个embedding vector是在训练过程中自动学到的, 没有具体的embedding vector label. 具体看下面的公式, pull用来聚合同一个object的两个top-left corner点, push用来分开不同object, ek是etk和ebk的均值. 网络就是根据这个来自动学习到embedding值.

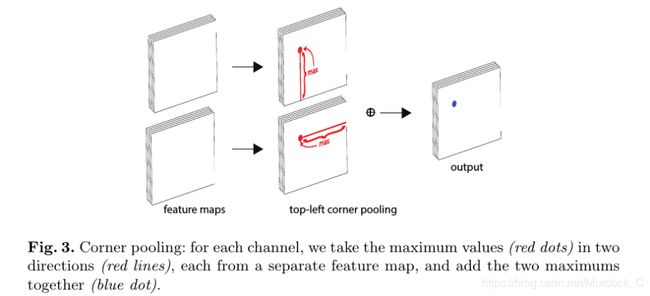
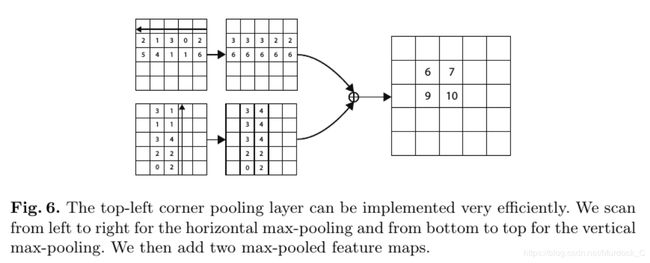
CornerNet贡献之处最大在于提出了corner pooling这个方法. 因为我们知道, 对于绝大部分object而言, 它的corner都是在目标之外的, 属于background, 是没有object信息的, 如果网络直接去找这些corner, 很可能找不到或者找不准. 所以作者提出了corner pooling这个概念使得corner有object信息在里面. 拿top-left corner为例, 它其实是有两个featuremap组成, 一个是top corner featuremap, 一个是left corner featuremap, 对于top corner featuremap而言, 要想找到真正的top corner点,就是对featuremap从下往上搜索, 已当前已有的最大值为当前corner pooling过后的值; 类似, 对于left corner featuremap而言, 就是从右向左搜索, 同样以当前以后的最大值为当前corner pooling过后的值. 具体做法如图所示. 之后, 再对两个pooling之后的featuremap直接进行element-wise add, 得到的结果就是top-left corner featuremap, 其中的最大值所在的位置就是top-left corner.

得到候选的top-left corner和bottom-right corner以及embedding vector, 剩下的就是暴力穷举, 找到符合要求的框. 这是cornernet在coco test-dev数据集上的表现, 最好的就是达到了42.1的AP, 在Titan X上, 平均一张图片需要244ms.511*511的输入.

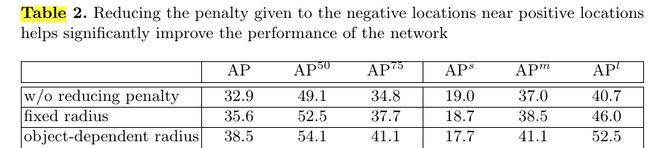
最后是文章给出了两个对比实验, table 1表明加入corner pooling找角点会比没有提高2个点左右, table 2就是在打label的时候, 是只把一个点当做gt其余位置全是bg, 还是固定离gt点某个范围内为gt但逐渐缩小score值, 还是根据box的大小动态的改变这个范围. 表中可以看出最后一种方法效果更好, 但有意思的地方在于对于small object, AP值反而是只有一个点为真值的时候效果最好. 个人猜想是因为small object本身太小, 若是还给它扩充范围, 就有可能把物体内部给包含进去, 这样就会造成学习到的corner不再是corner, 而是物体内部了, 所以造成AP值反而降低了.
Grid R-CNN (2018) (https://arxiv.org/abs/1811.12030)
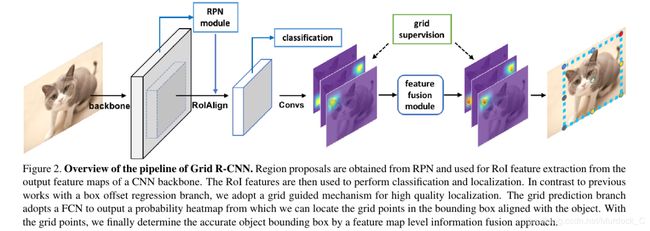
Grid R-CNN前半部分就是faster rcnn的rpn网络, 只是修改了后面的regression部分. 类似于cornernet, grid rcnn也是通过检测目标周围的关键点来对目标进行定位. 和cornernet不同的是, cornernet类似于bottom-up的方法, 就是先把所有的点检测出来, 然后再对点进行聚类, 把属于同一类的点合在一起, 而且cornernet只检测左上角和右下角两个点; grid rcnn则是类似top-down的方法, 先通过RPN把合适的proposal提出来, 然后再在单独的proposal上检测目标的关键点. 之所以叫做grid, 是因为网络检测object的NxN的网格点. 论文提出的例子是3x3, 即9个点.

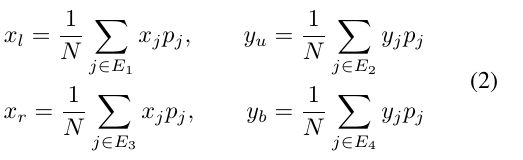
得到这9个点之后, 就可以根据这9个点来确定目标的边界,如公式2所示, x l x_{l} xl, y u y_{u} yu, x l x_{l} xl, y b y_{b} yb分别指向两个角点的坐标,.例如对于box的上面那条边, 就把落在这条边上的这三个点的y坐标乘上对应的confidence得到一个y值, 相对应的x值就是左边那条边上的三个点的x坐标乘上对应的confidence得到一个x值, 这样就确定了左上角的坐标点, 也就确定了上边和左边.
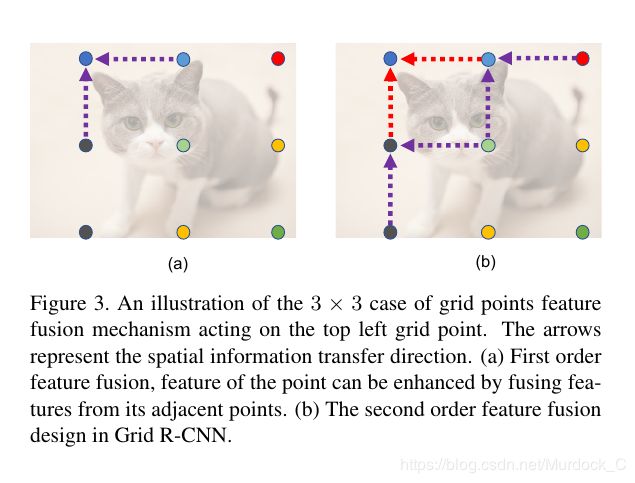
grid rcnn还提出了feature fusion操作用来进一步提高box的定位精度. 文章提了两种方式, 图a是1阶fusion, 以左上角点为需要fusion的点, 就是把离它grid距离为1的那两个点的featuremap, 做三个5x5的卷积然后和左上角点的原来的featuremap做element-wise add. 文章认为是相邻的点之间有连接信息, 加上这个feature fusion操作之后, 对提高点的精度有帮助. 图b就是2阶fusion, 原理和1阶fusion是一样的.
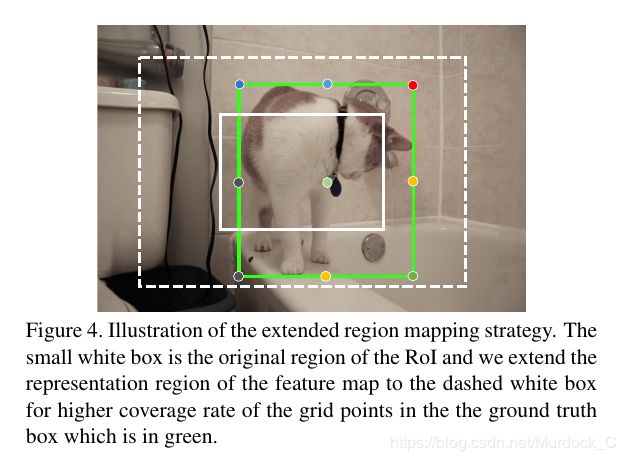
此外, 前面提取的proposal有可能没有正确的把全部的box点包含进去, 如图中的白色实线框所示.文章的做法是仍然用roi提取处的proposal做为输入, 在得到对应的heatmap上的点之后, 在返回原图时, 不再是根据heatmap的大小和原图的比例来映射, 而是采取一个扩大两倍的映射关系,通俗上来说就是左边的点更往左上角移动, 右边的点更往右上角移动, 这样在不增加proposal大小的情况下, 扩大了heatmap的表示范围, 这样就可能把全部的box都给包含进去, 如图上白色虚线框所示.(就是将heatmap上的点返回到原图时, 扩大2倍, 而不仅仅是原来的倍数关系)
ExtremeNet (2019) (https://arxiv.org/abs/1901.08043)

ExtremeNet是2019年早些时候提出的one-stage目标检测算法. 类似于cornernet, 最后也是检测出来5个点, 包括center point, 上下左右四个边界点. 流程图所示, backbone网络为hourglass网络, 然后输出 4xCxHxW的extreme heatmap, CxHxW的center heatmap, 以及 4x2xHxW的offset map. offset map主要用来修正extreme point的位置.
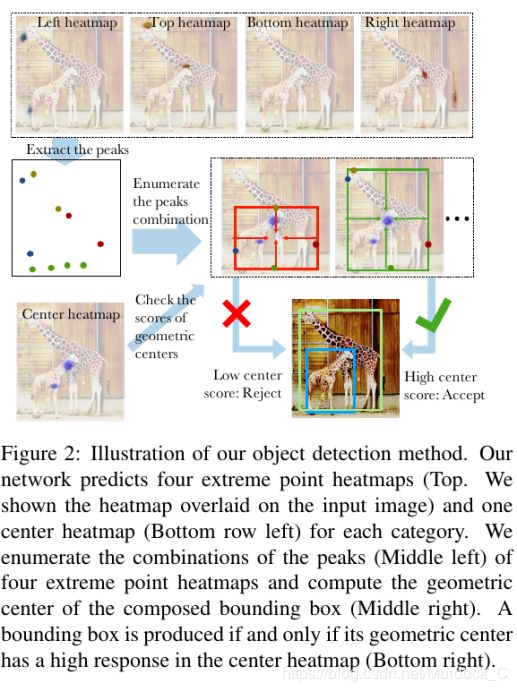
网络是根据加入offset之后的extreme point来确定哪些点应该组合在一起. 如图所示, 得到四种类型的极值点后, 会使用全局搜索的方式, 把所有的可能box组合遍历一遍, 如果四个点组成的框的中间位置confidence很高, 那就接受这个框, 否则就拒绝掉. confidence是指当前中心处的center confidence.

这是网络的一些结果, 可以发现提取出的object不再是用一个个四方形的框表示了, 而是用检测出来的四个极值点表示, 好处就是定位更准更符合现实, 坏处就是这种方法运行速度真的挺慢…, 322ms一张图片, GPU下.
CenterNet (2019) (https://arxiv.org/abs/1904.08189)

基于关键点的 one-stage 方法无法感知物体内部信息, 本论文的 baseline 为 CornerNet。首先,CornerNet 通过检测角点确定目标,而不是通过初始候选框 anchor 的回归确定目标,由于没有了 anchor 的限制,使得任意两个角点都可以组成一个目标框,这就对判断两个角点是否属于同一物体的算法要求很高,一但准确度差一点,就会产生很多错误目标框。其次,恰恰这个算法有缺陷。因为此算法在判断两个角点是否属于同一物体时,缺乏全局信息的辅助,因此很容易把原本不是同一物体的两个角点看成是一对角点,因此产生了很多错误目标框。如上图所示, 上面一行蓝色框是gt, 红色框是预测的, 可以发现很多错误的框也被预测出来.下面一行是本文的方法提取的框(不知道为啥没有放同样的图片做对比).

最后,角点的特征对边缘比较敏感,这导致很多角点同样对背景的边缘很敏感,因此在背景处也检测到了错误的角点。综上原因,使得 CornerNet 产生了很多误检,CenterNet的网络结构基本和Cornernet保持高度一致, 不同的地方就在于CenterNet还预测了目标的中心点, center-point, 并且对每一个点都加上了offset用来提高点的精度. 在inference的时候, 除了按照cornernet的做法找到两两匹配的top-left corner和bottom-right corner外, 网络还要进一步判断, 这两个点组成的box的中心处是否包含一个响应值很高的center point.(这个方法就和extreme net很像).另外, 考虑到图像中不同object有不同大小的框, 会根据组成的box大小来确定中心区域的大小. 如果框的大小大于150, n就设置为5; 小于150就设置为3, 文章只考虑到这两个大小.如图3所示:
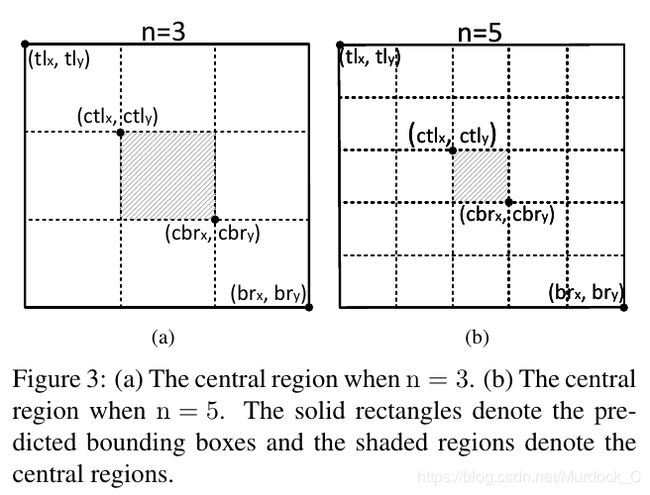
除此之外, 文章还提出了包含更多信息的corner pooling和center pooling. 在cornernet里, corner pooling只考虑边界上的信息, 文章认为这个信息可能还不够, 于是提出了cascade corner pooling. 其实就是相比于cornernet的corner pooling增加了从box内部往corner传递信息的方式. corner pooling的方法还是没有改变, 都是从一个方向往另外一个方向寻找最大值. 例如对于找top-left corner点, 因为是需要找到最上面的那条边的最大值, 之前的cornernet是直接按照这个线上的点从右往左遍历, centernet提出的cascade corner pooling会在做这个步骤之前, 先更新最上面的那条边上的每个值, 方法就是从下往上遍历, 类似于corner pooling, 更新边上的值, 之后再找top corner信息.其余点类似.

Objects as Points (2019, also called ‘CenterNet’) (https://arxiv.org/abs/1904.07850)
实这篇我认为才是真正的CenterNet, 只关注中心点, 不考虑其它, 思想简单, 效果超赞. 首先贴一下速度:

objects as points这篇文章思路很简单, 也是仿照cornernet的思想去找点, 但是只找了一个中心点和对应的宽高,没有像上面那篇文章要提三个点, 也没有cornernet里的pooling操作, 也没有extremenet里检测NxN个点, 就一个, 简单有效.(当然, 找的这个中心点同样有2个offset出现用来精确定位). 这个centerpoint就和前面那个Centernet的centerpoint不一样, 第一它没有center pooling操作, 而是吧centerpoint当做关键点来处理, 中心处响应值最高, 让后其上下左右四个位置低些, 其余位置为0. 为了提高中心点的定位精度, 同样也会在每个位置上预测两个offset. box的宽高通过直接回归得到.直接得到(h, w). 在将点回归到框的过程中, 会选择这个位置上的confidence比其8邻域位置confidence都要高的点.

这个思想可以用于多个任务, 文章给出了三种类型的例子, object detection, 3D object detection, multi human pose estimation. 对于2d object detection, 就输出HxWx5的featurmap, 包括(confidence, 2个offset, 2个object size). 对于3D object detection而言, 输出 HxWx12的featuremap, 包括(3个方向的size, 1个深度, 8个方向的指向). 对于pose estimation而言, 输出 HxWx(3k+2)的featuremap. 其中kx2是k个关键点离centerpoint的偏移, k是每个关键点的point, 2是每个关键点自身的偏移. 在pose estimation inference的时候, 首先得到k个关键点的位置, 然后根据center point的2k个偏移得到另外一组k个关键点位置, 然后判断这k个关键点哪个是哪个类型的关键点, 就是找离它最近的那k个关键点其中是哪个, 最后应该还是以centpoint回归得到的点为准.
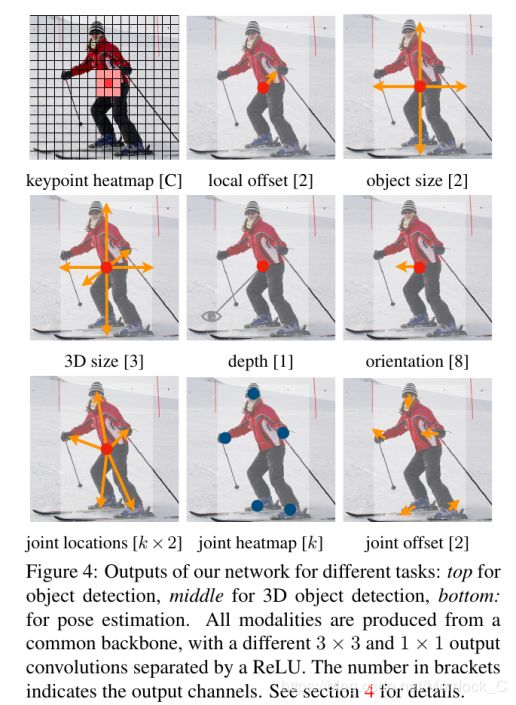
其实它的精度不如前面的CenterNet, 但在保持可以接受的AP精度下, 做到了速度快, 而且还很容易推广到其它任务, 可以一个backbone做多件任务.
FCOS (2019) (https://arxiv.org/abs/1904.01355)
这篇文章比较系统的说明了anchor-based detector的一些缺点, 比如:
- anchor-based detector的检测性能十分依赖于预先定义好的anchor大小, 数量, 长宽比等, 这些超参经过细心的调试过后, Retinanet可以在Coco上提高4%的AP
- 预先设定好的anchor大小丧失了普适性, 对于不同的场景需要设计新的的anchor重新调整
- anchor数量太多, 但positive样本太少, 造成样本间不平衡
- 训练时需要计算anchor和gt的IOU, 占用大量的内存和时间

FCOS的网络结构还是FPN的结构, 就是在生成p3~p7的时候, 没有在C5上采样得到P6, 而是直接用P5采样得到P6.
网络的输出有三个branch, classification branch输出每个点的类别, regression branch输出每个点的四个值, (l,t,r,b), 这个待会介绍. 其实这两个branch都和keypoint detection思想很像, 特别是和densebox思想很像, 和之前的centernet, cornernet相比也没有什么特别优秀的地方, 网络最主要的贡献在于提出了centernet-ness branch这个方法.

如图所示, (l,t,r,b)就是我们之前提到的regression branch提到的输出, 但如果只考虑这个情况, 就会有一个问题, 如图的右半部分所示, 同一个点其实可以回归两个gt box的值, 那么究竟回归哪一个, 文章中提出了2种方法, 一种是限制每一层featuremap需要检测的box大小范围, 从P3-P7,检测范围分别是[0, 64, 128, 256, 512, +无穷], 例如对于P3, 其上的box范围应该在[0, 64]之间, 超出这个范围的模型都会当做负样本, 如果同一层有完全重叠的两个box, 已小的box为准. 除此之外, 还用到了center-ness来辅助网络训练, 过滤掉score高但iou低的框, 就是质量不好的box.

center-ness大家可以从左图上直接理解, box的中心处响应值最高, 随后逐次降低, 值的范围在0~1之间. centet-ness branch中每个featuremap位置上的值计算是根据regression计算得到的(l, t, r, b), 用公式3计算得到, 可以看出, 越是中间位置, centerness值就越高, 越偏离中心处, centerness值就会越低, centerness-branch的loss用BCE来计算. center-ness在inference的时候, 会和classification score相乘, 这样就把不是中心处的点的classfication score降低, 因此低质量的box就会被抑制掉, 从而尽可能的消除提取的box有歧义的地方.下面的表格大家也可以看到, 加上center-ness, 对网络的涨点还是很有帮助的. 第一行是不加centerness-branch, 第二行是指通过regression得到的(l, t, r, b)计算centerness, 第三行是本文最终采用的方式, 和classfication共用一个head, 单独产生一个branch.

这张图就是图像化标明为什么center-ness有效, 左图是单纯的classfication score, 右图是乘上center-ness之后的结果, 横坐标是score, 纵坐标是当前位置所regression的box和gt最大的iou值. 可以看到加入center-ness之后, 很多高分低iou的box就被过滤掉了, 这也是为什么AP能提高的原因.
CornerNet-Lite (2019) (https://arxiv.org/abs/1904.08900)
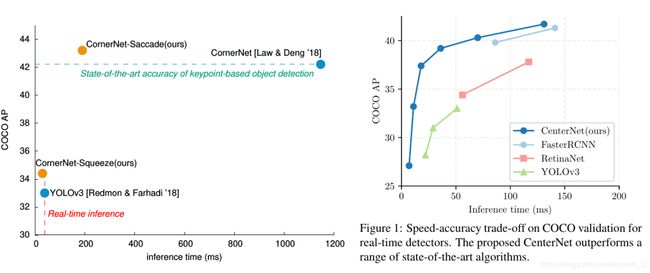
Cornernet的作者又提出了一个基于cornernet魔改的2个网络, cornernet-saccade和cornernet-squeeze, 统一称为cornernet-lite. 首先看速度, 左侧是cornernet-lite的两个网络性能/速度, 右侧是Objects as Points的网络速度/性能.从图中可以看到, objects as points无论从速度还是精度上, 同比都比cornernet-squeeze要高.
cornernet-saccade和cornernet-squeeze是cornernet修改的两个方向, 都旨在提高同时提高速度和精度, 只不过侧重点不一样.文章提出了两个方向: 1. 降低参与运算的featuremap数目 2. 降低featuremap每个位置需要运算的次数

Estimating Object Locations:
首先是要获得一张图片中可能存在目标物的位置信息。本文在一张下采样后的图片上得到attention maps,用于代表目标物的位置以及对应位置上目标物的大致大小。给定一张图片,缩小2倍,至边长为255或者为192,将边长为192的进行padding操作使其大小与255的相同,因此,可以进行并行处理。使用低分辨率图片的原因有两个:(1)这样操作会减少inference时间上的消耗(2)网络可以很容易得到图片中的上下文信息进而进行attention maps的预测。
对于下采样后的图片,CornerNet-Saccade预测出3个attention maps,其中一个用于小目标,一个用于中等目标,剩下一个作用于大的目标。如果一个目标物的较长边的像素小于32,则被视为小目标,32到96的视为中等目标,大于96的是大目标。针对不同尺寸的物体的位置进行独立的预测,可以更好的控制CornerNet-Saccade对每个位置的重视程度。相比于中等目标,可以更多的关注小目标。
通过在不同尺寸的feature maps上预测出attention maps。feature maps由CornerNet-Saccade的backbone hourglass网络得到。每一个hourglass模型通过一系列的卷积及下采样操作对输入图片进行缩小,然后,通过一系列的上采样及转置卷积将feature map恢复到输入图片大小的分辨率。而attention maps由上采样的层得到。对于尺寸较精细的feature maps用于预测小目标,而粗糙尺寸的框用于检测较大的目标。本文通过在每个feature map后面更上一个3x3的conv-ReLU+1x1的conv-sigmoid模型来得到attention maps。在测试过程中,只处理分数大于0.3的位置。
当CornerNet-Saccade处理下采样后的图片,极有可能会检测到一些目标物,同时,产生一些边界框,单由于分辨率较低,因此,这些框可能并不是很准确,因此,需要在高分辨率上进行评估,进而得到更好的边界框。
(训练时,将对应attention map上的边界框的中心设置为positive,其余为negative,然后,使用的Focal loss。)
目标检测:CornerNet-Saccade利用从downsized image中得到的位置来确定哪里需要进行处理。如果直接从downsized图片中裁剪,则一些目标物可能会太小以至于无法准确的进行检测。因此,需要刚开始就在高分辨率的feature map上得到尺寸信息。对于从attention maps得到的位置,可以针对不同尺寸的目标设置不同的放大尺寸。Ss代表小目标的缩放尺寸,Sm代表中等目标的缩放尺寸,Sl代表大目标的缩放尺寸。整体三者之间存在一种关系,Ss>Sm>sl,因为,我们需要对小目标进缩放的成都要大一些。本文设置如下,Ss=4,sm=2,sl=1.对于可能存在的位置(x,y),根据预测出来的边界框的目标尺寸,目标的长边为24,中等目标的为64,大目标的为192, 然后按照si的比例对downsized图片进行放大,然后,将在高分辨率下得到的图片裁剪再缩放为255*255放入下一个网络中.
应为attention map和hourglass网络都可以得到粗略的box, 有些可能是重复的, 因此需要先进行NMS, 在保证score的情况下,以attention map得到的box为准.
cornernet-saccade的改进方向: 降低运算的featuremap大小, 在coco test-dev上AP为43.2, 190ms一张图片, 引用了attention的思想, 这个偏重效果更好

cornernet-squeeze则偏重于速度, 解决方法是降低每个featuremap位置需要参与的运算次数, 使用了squeezeNet和mobileNet的思想, 修改了卷积的组成方式.具体方法就是把原来的3x3的卷积, 先用1x1的卷积通道数减半, 然后再用一个1x1和3x3的depthwise卷积恢复.cornernet-squeeze输入大小和cornernet一致,为511*511, 但在进入hourglass之前, 相比cornernet, 又多增加了一次downsample(3:2).

文章中也讨论过如果两者结合在一起反而效果会更差. 原因是作者认为cornernet-squeeze因为其网络结构十分紧凑的原因, 没有办法同时做目标检测和predict attention map这两件事情. 如果预测的attention map不精确, 加上saccade就不能提高精度, 反而会增加计算量,提高运行速度.
总结
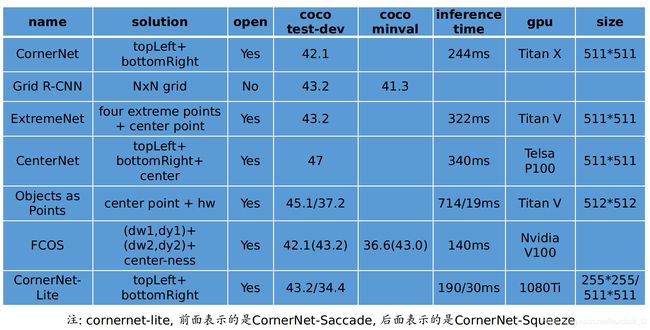
这个是这些框架一个整体比较, 选取的都是其最优能达到的效果, 其中FCOS括号里是其github上开源的repo里提到的精度, 外面是论文里提到的精度. FCOS开源的模型精度比论文里提高了不少, 最快的模型可以在70ms的速度下, coco minval test-dev都达到37的AP.
从15年densebox第一次提出anchor-free的思想, 到今年的anchor-free detector的文章井喷, 我觉得有2点原因, 1是anchor-based的网络已经调不动了或者只是AP0.1的大小提升; 2是18年出的cornernet开源, 让大家认识到这个方向的可行性(densebox没有开源). 无论哪种方法, 其实都是着重于如何更有效的表达’box’这个概念. cornernet用上下两个角点, centernet加上了中心点, grid rcnn用九个点, objects as points用1个点+hw, extreme net用四个极值点+中心点, FCOS和densebox很像, 多加了一个center-ness branch. 从整体速度/精度平衡上看, objects as points做到了最优的速度/精度平衡, 而且思路很简单.
有一个思路, 就是把centernet, objects as points, FCOS, cornernet-lite的优点结合起来, 预测中心点+hw+center-ness, 再改下backbone, 看看能到哪一步