【NLP】词向量:从word2vec、glove、ELMo到BERT详解!
目前,词向量(又叫词嵌入word embedding)已经成为NLP领域各种任务的必备一步,而且随着bert elmo,gpt等预训练模型的发展,词向量演变为知识表示方法,但其本质思想不变。学习各种词向量训练原理可以很好地掌握NLP各种方法。生成词向量的方法有很多种,本文重点介绍word2vec,glove和bert。
各种词向量的特点:
- One-hot:维度灾难 and 语义鸿沟;
- 矩阵分解(LSA):利用全局语料特征,但SVD求解计算复杂度大;
- 基于NNLM/RNNLM的词向量:词向量为副产物,存在效率不高等问题;
- word2vec、fastText:优化效率高,但是基于局部语料;
- glove:基于全局预料,结合了LSA和word2vec的优点;
- elmo、GPT、bert:动态特征。
从one-hot到word2vec到elmo,可以看到技术的演进总是在现有基础上解决之前的问题,同时引出新的问题。这里总结一下比较经典的语言模型:word2vec、glove、ELMo、BERT。
word2vec
word2vec来源于2013年的论文《Efficient Estimation of Word Representation in Vector Space》,它的核心思想是利用神经网络对词的上下文训练得到词的向量化表示,训练方法:CBOW(通过附近词预测中心词)、Skip-gram(通过中心词预测附近的词):
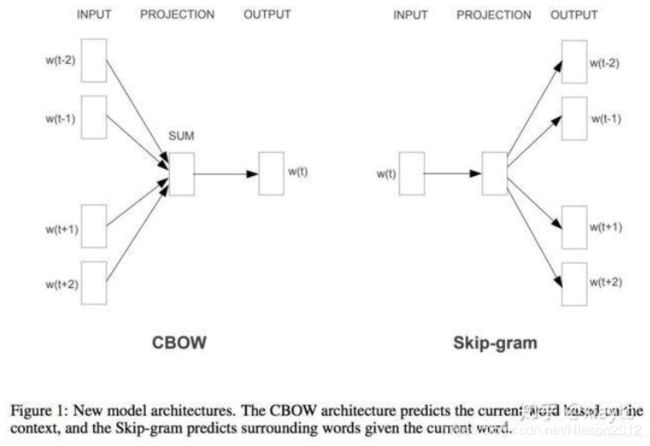
CBOW与Skip-gram基本结构
CBOW :
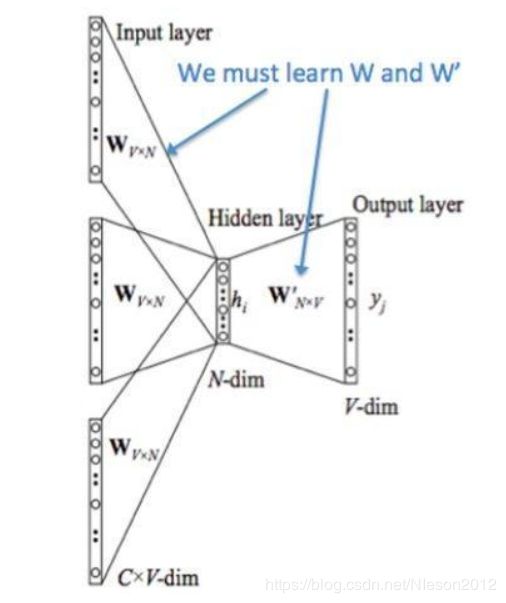
NOTE:花括号内{}为解释内容.
- 输入层:上下文单词的onehot. {假设单词向量空间dim为V,上下文单词个数为C}
- 所有onehot分别乘以共享的输入权重矩阵W. {V*N矩阵,N为自己设定的数,初始化权重矩阵W}
- 所得的向量 {因为是onehot所以为向量} 相加求平均作为隐层向量, size为1*N.
- 乘以输出权重矩阵W' {N*V}
- 得到向量 {1*V} 激活函数处理得到V-dim概率分布 {PS: 因为是onehot嘛,其中的每一维斗代表着一个单词},概率最大的index所指示的单词为预测出的中间词(target word)
- 与true label的onehot做比较,误差越小越好
所以,需要定义loss function(一般为交叉熵代价函数),采用梯度下降算法更新W和W'。训练完毕后,输入层的每个单词与矩阵W相乘得到的向量的就是我们想要的词向量(word embedding),这个矩阵(所有单词的word embedding)也叫做look up table(其实聪明的你已经看出来了,其实这个look up table就是矩阵W自身),也就是说,任何一个单词的onehot乘以这个矩阵都将得到自己的词向量。有了look up table就可以免去训练过程直接查表得到单词的词向量了。
Skip-gram
跟CBOW的原理相似,它的输入是目标词,先是将目标词映射为一个隐藏层向量,根据这个向量预测目标词上下文两个词,因为词汇表大和样本不均衡,同样也会采用多层softmax或负采样优化。
分层softmax
一般神经网络语言模型在预测的时候,输出的是预测目标词的概率,也就是说我每一次预测都要基于全部的数据集进行计算,这无疑会带来很大的时间开销。不同于其他神经网络,word2vec提出两种加快训练速度的方式,一种是Hierarchical softmax,另一种是Negative Sampling。
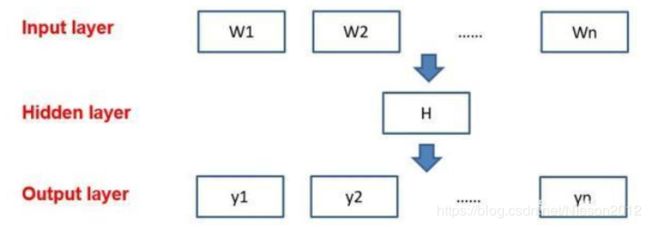
原始神经网络模型的输入输出框架
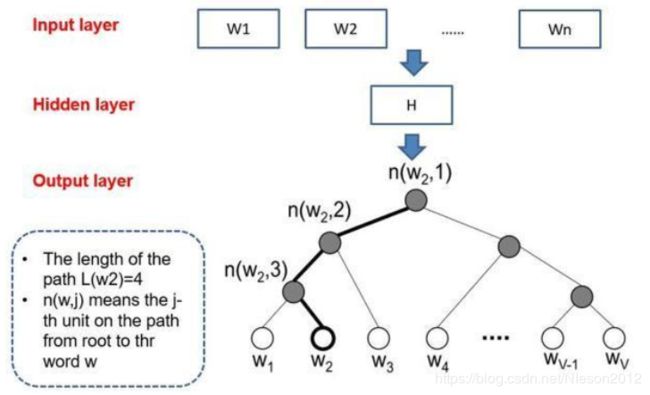
word2vec hierarchical softmax结构
和传统的神经网络输出不同的是,word2vec的hierarchical softmax结构是把输出层改成了一颗哈夫曼树,其中图中白色的叶子节点表示词汇表中所有的|V|个词,黑色节点表示非叶子节点,每一个叶子节点也就是每一个单词,都对应唯一的一条从root节点出发的路径。我们的目的是使得w=wO这条路径的概率最大,即: P(w=wO|wI)最大,假设最后输出的条件概率是W2最大,那么我只需要去更新从根结点到w2这一个叶子结点的路径上面节点的向量即可,而不需要更新所有的词的出现概率,这样大大的缩小了模型训练更新的时间。
我们应该如何得到某个叶子结点的概率呢?

假设我们要计算W2叶子节点的概率,我们需要从根节点到叶子结点计算概率的乘积。我们知道,本模型替代的只是原始模型的softmax层,因此,某个非叶子节点的值即隐藏层到输出层的结果仍然是uj,我们对这个结果进行sigmoid之后,得到节点往左子树走的概率p,1-p则为往右子树走的概率。关于这棵树的训练方式比较复杂,但也是通过梯度下降等方法,这里不详述,感兴趣的可以阅读论文word2vec Parameter Learning Explained。
~~~
(2)Negative Sampling 负采样
传统神经网络在训练过程中的每一步,都需要计算词库中其他词在当前的上下文环境下出现的概率值,这导致计算量十分巨大。
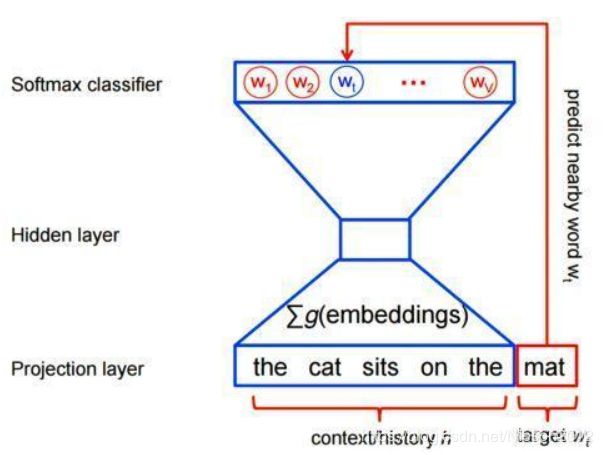
然而,对于word2vec中的特征学习,可以不需要一个完整的概率模型。CBOW和Skip-Gram模型在输出端使用的是一个二分类器(即Logistic Regression),来区分目标词和词库中其他的 k个词(也就是把目标词作为一类,其他词作为另一类)。下面是一个CBOW模型的图示,对于Skip-Gram模型输入输出是倒置的。

此时,最大化的目标函数如下:
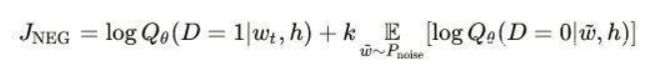
其中,Qθ(D=1|w,h)为二元逻辑回归的概率,具体为在数据集 D中、输入的embedding vector θ、上下文为 h的情况下词语 w 出现的概率;公式后半部分为 k 个从 [噪声数据集] 中随机选择 kk个对立的词语出现概率(log形式)的期望值。可以看出,目标函数的意义是显然的,即尽可能的 [分配(assign)] 高概率给真实的目标词,而低概率给其他 k 个 [噪声词],这种技术称为负采样(Negative Sampling)。
这种想法来源于噪声对比评估方法(NEC),大致思想是:假设X=(x1,x2,,xTd)是从真实的数据(或语料库)中抽取样本,但是样本服从什么样的分布我们不知道,那么先假设其中的每个xi服从一个未知的概率密度函数pd。这样我们需要一个相对可参考的分布反过来去估计概率密度函数pd,这个可参考的分布或称之为噪音分布应该是我们知道的,比如高斯分布,均匀分布等。假设这个噪音分布的概率密度函数pn,从中抽取样本数据为Y=(y1,y2,,yTn)Y=(y1,y2,,yTn),而这个数据称之为噪声样本,我们的目的就是通过学习一个分类器把这两类样本区别开来,并能从模型中学到数据的属性,噪音对比估计的思想就是“通过比较而学习”。
具体来说,word2vec里面的负采样:将输出层的V个样本分为正例(Positive Sample)也就是目标词对应的项,以及剩余V1个负例(Negative Samples)。举个例子有个样本phone
number,这样wI=phone,wO=number, 正例就是number这个词,负例就是不太可能与phone共同出现的词。负采样的思想是每次训练只随机取一小部分的负例使他们的概率最小,以及对应的正例概率最大。随机采样需要假定一个概率分布,word2vec中直接使用词频作为词的分布,不同的是频数上乘上0.75,相比于直接使用频次作为权重,取0.75幂的好处可以减弱不同频次差异过大带来的影响,使得小频次的单词被采样的概率变大。

采样权重
负采样定义的损失函数如下:
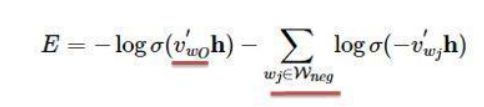
损失函数,一部分是正样本(期望输出的词),另一部分是负采样随机抽取出来的负样本集合,V'wo是输出向量
如果大家理解的还不是很深的话,接下来将通过谷歌发布的tensorflow官方word2vec代码解析加深理解。代码链接:https://github.com/tensorflow/tensorflow/blob/master/tensorflow/examples/tutorials/word2vec/word2vec_basic.py,之后我会对代码进行详细剖析,欢迎跟踪~谢谢
glove
word2vec只考虑到了词的局部信息,没有考虑到词与局部窗口外词的联系,glove利用共现矩阵,同时考虑了局部信息和整体的信息。Count-based模型,如GloVe,本质上是对共现矩阵进行降维。首先,构建一个词汇的共现矩阵,每一行是一个word,每一列是context。共现矩阵就是计算每个word在每个context出现的频率。由于context是多种词汇的组合,其维度非常大,我们希望像network embedding一样,在context的维度上降维,学习word的低维表示。这一过程可以视为共现矩阵的重构问题,即reconstruction loss。(这里再插一句,降维或者重构的本质是什么?我们选择留下某个维度和丢掉某个维度的标准是什么?Find the lower-dimensional representations which can explain most of the variance in the high-dimensional data,这其实也是PCA的原理)。
来自论文《Glove: Global vectors for word representation》。Glove损失函数的确定

ELMO
之前介绍词向量均是静态的词向量,无法解决一次多义等问题。下面介绍三种elmo、GPT、bert词向量,它们都是基于语言模型的动态词向量。下面从几个方面对这三者进行对比:
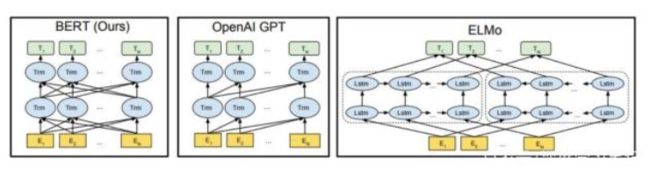
ELMO是“Embedding from Language Models"简称。在此之前word embedding本质是个静态方式,静态的意思就是说单词训练好之后就固定了,在以后使用时,单词不会跟着上下文场景变化而变化。如Jobs is the CEO of apple,he finally eat an apple.用word2vec “apple”的表示是一样的向量,动态模型可以解决此问题。
ELMO的本质思想是:事先用一个语言模型去学习单词的word embedding, 当在使用时,单词已经具备了特定的上下文,这时候可以根据上下文的语义去调整单词的word embedding, 这样经过调整的word embedding更能表达这个上下文中具体的含义,也就解决了一词多义问题,故ELMO本质就是根据当前上下文对Word Embedding进行动态调整的过程。
Elmo采用典型的两阶段过程:第一阶段使用预训练语言模型进行训练,第二阶段当做具体的下游任务时,从预训练的网络中提取对应的词的Word Embedding作为特征补充到下游任务中。
第一阶段,预训练:采用双层双向LSTM对上下文进行编码,上下文使用静态的word embedding, 对每层LSTM,将上文向量与下文向量进行拼接作为当前向量,利用大量的预料训练这个网络。对于一个新的句子,可以有三种表示,最底层的word embedding, 第一层的双向LSTM层的输出,这一层能学习到更多句法特征,第二层的双向LSTM的输出,这一层能学习到更多词义特征。经过elmo训练,不仅能够得到word embedding, 又能学习到一个双层双向的神经网络。

第二阶段,下游任务使用:将一个新的句子作为elmo预训练网络的输入,这样该句子在elmo网络中能获得三个embedding, 可以将三个embedding加权作为word embedding, 并将此作为下游任务的输入,这被称为“Feature-based Pre-Training"。
GPT
GPT是Generative Pre-Traxining的简称。与ELMO相似,采用两阶段的模式:利用语言模型进行预训练,通过fine-tuning模式应用到下游任务。
利用语言模型进行预训练:与elmo不同的是,GPT使用transformer进行提取特征,并且是单向的transformer,只是根据上文来预测某个词,Transformer模型主要是利用自注意力(self-attention)机制的模型。

fine-tuning: 与ELMo当成特征的做法不同,OpenAI GPT不需要再重新对任务构建新的模型结构,而是直接在transformer这个语言模型上的最后一层接上softmax作为任务输出层,然后再对这整个模型进行微调。

由于不同NLP任务的输入有所不同,在transformer模型的输入上针对不同NLP任务也有所不同。具体如下图,对于分类任务直接讲文本输入即可;对于文本蕴涵任务,需要将前提和假设用一个Delim分割向量拼接后进行输入;对于文本相似度任务,在两个方向上都使用Delim拼接后,进行输入;对于像问答多选择的任务,就是将每个答案和上下文进行拼接进行输入。

BERT
BERT是“Bidirectional Encoder Representations from Transformers"的简称。
同GPT采用两阶段模式:利用双向transformer语言模型进行预训练,通过fine-tuning模式解决下游任务。
BERT创新: Masked语言模型和Next Sentence Prediction。
BERT(Bidirectional Encoder Representations from Transformers)详解(参考链接:https://plmsmile.github.io/2018/12/15/52-bert/
http://fancyerii.github.io/2019/03/09/bert-theory/#elmo):
1.总体框架:利用半监督学习一个双向语言模型,然后在下游任务中,经过该语言模型后,接其他任务。

2. BERT输入表示(如图):
句子开头有一个特殊的Token [CLS]句子结束有一个特殊的Token [SEP]如果是两个句子同时输入,则只有开头有[CLS],后面那个句子没有[CLS],只有[SEP]每个token有三个embedding,词的Embedding;位置的Embedding和Segment的Embedding词embedding不用多说,位置embedding是将位置用低维稠密向量表示,segment的embedding是为了将多个句子区分,第一个句子可能用0表示,第二个用1,只有一个句子的时候可能只用0第一个token很有用,可不能小瞧,因为它本身没有任何意义,在进行self-attention时,会获取下文所有信息(编码整个句子的语义),不像其他单词,在self-attention时获取最多的信息是来自于自己。注意这里的分词会把”playing”分成”play”和”##ing”两个Token,这种把词分成更细粒度的Word Piece的方法是一种解决未登录词的常见办法

3. BERT预训练(至关重要的两点):
Mask language model:遮掩语言模型Next Sentence Prediction:预测下一个句子(关系)4. Mask language model(遮掩语言模型):在预训练的时候,随机mask掉15%的单词,让语言模型去预测这个单词,如图(图中512是padding,规定了句子的长度):
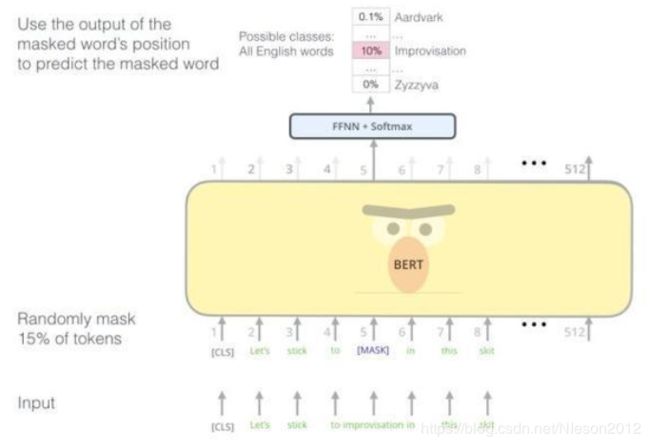
这样的话有两个缺点:
大量mask标记,造成预训练和finetune时候的差距,因为finetune没有mask,finetune的时候用的是自己的数据集收敛很慢,但是效果好(比单向语言模型慢)关于第一条的解决方案:
80%的概率替换成[MASK],比如my dog is hairy → my dog is [MASK]10%的概率替换成随机的一个词,比如my dog is hairy → my dog is apple10%的概率替换成它本身,比如my dog is hairy → my dog is hairy这样的好处在于:BERT并不知道[MASK]替换的是哪一个词,而且任何一个词都有可能是被替换掉的,比如它看到的apple可能是被替换的词。这样强迫模型在编码当前时刻的时候不能太依赖于当前的词,而要考虑它的上下文,甚至更加上下文进行”纠错”。比如上面的例子模型在编码apple是根据上下文my dog is应该把apple(部分)编码成hairy的语义而不是apple的语义。5. Next Sentence Prediction(预测下一个句子):对于像QA、NLI等需要理解多个句子之间关系的下游任务,只靠语言模型是不够的。还需要提前学习到句子之间的关系。是一个二分类任务。输入是A和B两个句子,标记是IsNext或NotNext,用来判断B是否是A后面的句子。这样,就能从大规模预料中学习到一些句间关系。

对于这个任务,BERT会以50%的概率抽取有关联的句子(注意这里的句子实际只是联系的Token序列,不是语言学意义上的句子),另外以50%的概率随机抽取两个无关的句子,然后让BERT模型来判断这两个句子是否相关。6. 下游特定任务:
单句子分类(CLS+句子):输入是一个序列,所有的Token都是属于同一个Segment(Id=0),我们用第一个特殊Token [CLS]的最后一层输出接上softmax进行分类,用分类的数据来进行Fine-Tuning。利用CLS进行分类。
多句子分类(CLS+句子A+SEP+句子B):对于相似度计算等输入为两个序列的任务,过程如图左上所示。两个序列的Token对应不同的Segment(Id=0/1)。我们也是用第一个特殊Token [CLS]的最后一层输出接上softmax进行分类,然后用分类数据进行Fine-Tuning。利用CLS分类。
NER(CLS+句子):序列标注,比如命名实体识别,输入是一个句子(Token序列),除了[CLS]和[SEP]的每个时刻都会有输出的Tag,然后用输出的Tag来进行Fine-Tuning利用句子单词做标记。QA:CLS+问题+SEP+文章。比较麻烦,比如比如SQuAD v1.1数据集,输入是一个问题和一段很长的包含答案的文字(Paragraph),输出在这段文字里找到问题的答案。比如输入的问题是:
Where do water droplets collide with ice crystals to form precipitation?
包含答案的文字是:
... Precipitation forms as smaller droplets coalesce via collision with other raindrops or ice crystals within a cloud. ...
答案是:
”within a cloud”
我们首先把问题和Paragraph表示成一个长的序列,中间用[SEP]分开,问题对应一个Segment(id=0),包含答案的文字对于另一个Segment(id=1)。这里有一个假设,那就是答案是Paragraph里的一段连续的文字(Span)。BERT把寻找答案的问题转化成寻找这个Span的开始下标和结束下标的问题。
对于Paragraph的第i个Token,BERT的最后一层把它编码成Ti,然后我们用一个向量S(这是模型的参数,需要根据训练数据调整)和它相乘(内积)计算它是开始位置的得分,因为Paragraph的每一个Token(当然WordPiece的中间,比如##ing是不可能是开始的)都有可能是开始可能,我们用softmax把它变成概率,然后选择概率最大的作为答案的开始:

类似的有一个向量T,用于计算答案结束的位置。

总结
word2vec:
nlp中最早的预训练模型,缺点是无法解决一词多义问题.
ELMO:
优点: 根据上下文动态调整word embedding,因为可以解决一词多义问题;
缺点:1、使用LSTM特征抽取方式而不是transformer,2、使用向量拼接方式融合上下文特征融合能力较弱,伪双向。
GPT:
优点:使用transformer提取特征
缺点:使用单项的语言模型,即单向transformer.
BERT:
优点:使用双向语言模型,即使用双向transformer;使用预测目标词和下一句这中多任务学习方式进行训练。
缺点:对文本字数512限制,不利于文本生成。
参考:
https://arxiv.org/abs/1810.04805
https://zhuanlan.zhihu.com/p/35074402
https://www.zhihu.com/question/44832436/answer/266068967
https://zhuanlan.zhihu.com/p/53425736
https://www.cnblogs.com/robert-dlut/p/9824346.html