神经网络基础:从一个线性模型说起
神经网络基础:从一个线性模型说起
- 1.从一个线性模型说起
- 1.1 一个通用的模式识别流程
- 1.2 一个线性分类器
- 1.3 softmax函数
- 2.损失函数
- 2.1 one-hot编码
- 2.2 交叉熵损失函数 Cross-Entropy Loss
- 2.2 折页损失 Hinge Loss
- 2.3 正则化 Regularization
- 2.4 总的损失
- 3.梯度计算
- 4. 优化方法
1.从一个线性模型说起
1.1 一个通用的模式识别流程
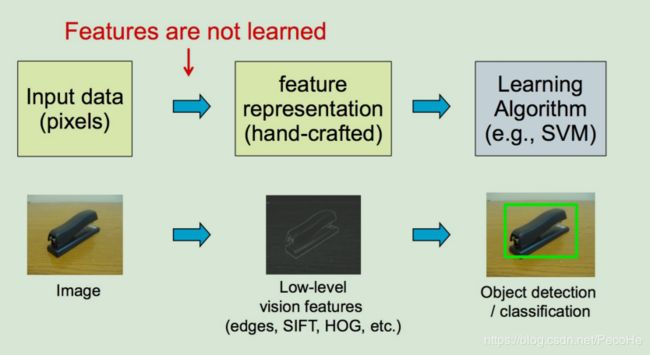
我们以图像分类为例,如上图所示假如我们要识别一个订书机,从机器学习的角度来看需要做如下几步:
首先是选择一个好的分类算法,比如支持向量机。
有了分类算法,我们还需要这个算法的输入,输入一般是一个特征向量。在实际应用中一般没有直接可以拿来作为输入的这么一种向量,我们有的是针对我们的业务或者说任务所获取到的数据,比如图像、语音、文本等。我们需要将这些原始的数据,变成分类算法可以接受的输入,这样的一个过程称为特征学习或者特征提取,特征表征。在深度学习之前,传统的机器学习中的特征提取一般是人工来做的,即常说的特征工程。而深度学习允许由多个处理层组成的计算模型来学习具有多个抽象级别的数据表示。
1.2 一个线性分类器
假设我们的分类模型输入是一个 D D D维的特征向量,分类的目标是分成 K K K类,我们需要设计这样的一个线性模型,该模型可以将一个 D D D维的输入映射到一个一个 K K K维的输出,输出中的每一个元素即该类别的得分。
线性代数的知识就可以帮助我们完成这样的设计,我们只需要一个 K K Kx D D D 维的矩阵 W W W就可以完成这样的一个映射。再加上 K K Kx 1 1 1维的偏置项 b b b,就得到了这样的一个函数,其中 x i x_i xi是 D D D维的输入:
f ( x i , W , b ) = W x i + b f(x_i ,W,b) = Wx_i + b f(xi,W,b)=Wxi+b
来看下面这张图,假设我们通过一定的方法可以将一幅猫的图像通过特征提取表示成一个四维的特征向量 x i [ 56 , 231 , 24 , 2 ] x_i[56,231,24,2] xi[56,231,24,2] :
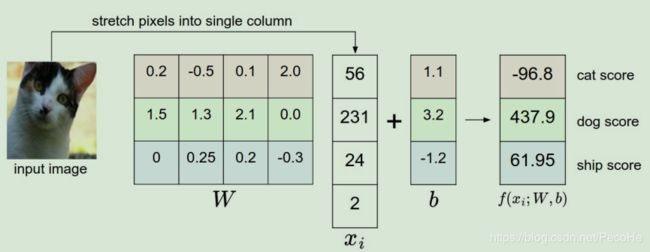
矩阵右乘向量的运算我们都会做,矩阵的每一个行向量分别与右边的向量点乘。那么矩阵的行向量和列向量的意义都是什么呢?
矩阵的列数为4是因为特征向量的维度是4,矩阵的行数为3是因为分类的目标类书是3。从图中可以看到输入是一只猫,并且猫的类别是第一个类,因此我们的目标是让这个矩阵第一行向量与特征向量运算后的结果,即得分值尽量的最大,这样才能得到正确的分类结果。
向量点乘的意义是两个向量的相似度。当两个向量点乘结果为0时,说明两个向量是正交的。如果这两个向量的方向一致,则乘出来的结果越大。因此向量点乘的意义就是两个向量的相似度,并且这个相似度是两个向量的夹角。
所以上图中矩阵右乘向量的运算其实就是在计算 W W W的3个行向量分别与 x i x_i xi的相似度。我们说过 W W W的行向量维度是4是因为输入的特征向量的维度是4, W W W行向量上的每一个元素就是对应位置 x i x_i xi中特征的权重。所以 W W W实际上是一个世界观的描述算子,它刻画了世界中不同特征的权重。
回到图中不难发现,目前这个分类器对输入图像处理后得到的分类结果是狗,显然这个结果是不正确的。那么问题出在哪了?显然问题出现在了W上,因此需要改变W,改变W,纠正它的世界观就是学习算法做的事情。
1.3 softmax函数
在上面的分类器完成分类后得到的输出是每个类别的分数,当你跟一个不懂机器学习的人来说,猫的得分是-96.8,狗的得分是437.9,显然他们不一定能够理会你的意思,但是如果你告诉他这个图片是猫的概率是90%,狗的概率是5%,那是个人就能懂了。
sofamax函数就可以完成这样的事情:将得分映射成(0~1)的概率值:
f j ( z ) = e z j ∑ k e z k f_j(z)=\frac{e^{z_j}}{\sum{k^{e{z_k}}}} fj(z)=∑kezkezj
2.损失函数
损失函数可以帮助衡量模型的好坏,它决定了训练的反馈信号。
2.1 one-hot编码
对于分类问题来说,损失函数需要衡量出目标类别与当前预测的差距。
例如对于一个三分类问题来说,假设模型输出经过softmax之后的概率分布为[0.1,0.1,0.8],真实分类是2,则需要将2通过独热编码one-hot变成一个分布[0,0,1],这时候就可以计算[0.1,0.1,0.8],[0,0,1]这两个向量的距离。
2.2 交叉熵损失函数 Cross-Entropy Loss
假设 ( x i , y i ) (x_i,y_i) (xi,yi) 是一对训练样本,其中 x i ∈ R D x_i\in R^D xi∈RD 是训练数据并且 y i ∈ R K y_i\in R^K yi∈RK 是经过独热编码后的标签,除了 x i x_i xi 真实对应类别的那一位为1其余位均为0, y i ^ ∈ R K \hat{y_i}\in R^K yi^∈RK是经过softmax函数处理过后的概率分布,则交叉熵损失为:
L o s s i = − y i ⋅ l o g ( y i ^ ) Loss_i=-{y_i} \cdot log (\hat{y_i}) Lossi=−yi⋅log(yi^)
举个栗子,对于上述的预测分布[0.1,0.1,0.8]和[0,0,1]该如何计算交叉熵损失呢?
首先我们知道 y i = [ 0 , 0 , 1 ] y_i=[0,0,1] yi=[0,0,1], y i ^ = [ 0.1 , 0.1 , 0.8 ] \hat{y_i}=[0.1,0.1,0.8] yi^=[0.1,0.1,0.8],两个向量点乘,不管 y i ^ \hat{y_i} yi^ 里面的元素是什么,经过与 y i y_i yi 中的非1,在上面的例子中即向量前面的两位0运算后都是0,因此我们只需要计算与 y i y_i yi 中非0位对应的那个元素的log值,即:
L o s s i = − 1 ⋅ l o g ( 0.8 ) = 0.0969 Loss_i=-1\cdot{log(0.8)}=0.0969 Lossi=−1⋅log(0.8)=0.0969
这是预测正确时的损失,我们再来看看预测错误时的损失,假设 y i ^ = [ 0.1 , 0.8 , 0.1 ] \hat{y_i}=[0.1,0.8,0.1] yi^=[0.1,0.8,0.1],则
L o s s i = − 1 ⋅ l o g ( 0.1 ) = 0.99999 Loss_i=-1\cdot{log(0.1)}=0.99999 Lossi=−1⋅log(0.1)=0.99999
显然错误时的损失更大!
2.2 折页损失 Hinge Loss
在交叉熵损失中,因为包含指数计算,因此计算代价是昂贵的。并且有的时候我们不需要概率分布,这个时候就可以使用折页损失函数:
L o s s i = ∑ j ≠ y i m a x ( 0 , f ( x i , W ) j − f ( x i , W ) y i + ∆ ) Loss_i =\sum_{j\neq y_i}max(0,f(x_i ,W)_j− f(x_i ,W)_{y_i} + ∆) Lossi=j=yi∑max(0,f(xi,W)j−f(xi,W)yi+∆)
折页损失将将 f ( x i , W ) f(x_i ,W) f(xi,W) 的输出中除了第 y i y_i yi (即正确的类别)类对应那位的得分值依次与第二类对应得分值比较。
举个栗子,假设 x i x_i xi 对应的标签是2,那么我们将 f ( x i , W ) f(x_i ,W) f(xi,W) 的输出中除了第二类对应那位的得分值依次与第二类对应得分值比较,用前者减去后者。我们知道如果分类正确了,那么后者的值应该是最大的,因此得到的每一个差值都是负值,小于0,此时经过max函数与0比较,得到的就是0,每一项都是0累加之后最终的损失值也为0。如果分类错误了,必然有某一项的分数是比实际正确的类分数大的,因此差值中必然有一项的值大于0,因此每一项与0比较之后在累加的损失值就是大于0的值。
式子中的∆是一个可接受范围,举个栗子,假设猫的分数是80,狗的分数是81,虽然根据分数大可以判定为狗,但是这么接近的分数,显然直接判定为狗是不合理的。因此加上一个∆,必须狗的得分比猫的得分多∆这么多才认为判断为狗是可靠的。
折页损失与交叉熵损失对比如下图:

2.3 正则化 Regularization
正则化是一种常见的防止模型学习过度拟合的方法。最常见的正则化约束是L2范数正则化:
R ( W ) = ∑ k ∑ d W k , d 2 R(W)={\sum_{k}} {\sum_{d}}{W^2_{k,d}} R(W)=k∑d∑Wk,d2
即当两套权重的Loss差不多时,选择权重值比较少的那套参数。
2.4 总的损失
总的损失就是前面说的折页损失或者交叉熵损失加上正则化项:
L = 1 N ∑ i L i + λ R ( W ) L =\frac{1}{N}\sum_iL i + λR(W) L=N1i∑Li+λR(W)
3.梯度计算
在看这张对猫咪分类的图片:
我们说目前的 W W W 是不好的,那么如何优化 W W W 呢?
由前面损失函数部分可以知道,假设采用折页损失,那么对于一个样本来说,该样本的损失为:
L o s s i = ∑ j ≠ y i m a x ( 0 , W j T x i − W y i T x i + ∆ ) Loss_i =\sum_{j\neq y_i}max(0,W^T_jx_i-W^T_{y_i}x_i+ ∆) Lossi=j=yi∑max(0,WjTxi−WyiTxi+∆)
则 L o s s i Loss_i Lossi对 W y i W_{y_i} Wyi求偏导可以得到:
∂ L o s s i ∂ W y i = − [ ∑ j ≠ y i 1 ( W j T x i − W y i T x i + ∆ > 0 ) ] x i \frac{\partial Loss_i}{\partial W_{y_i}} =-[\sum_{j\neq y_i}1(W^T_jx_i-W^T_{y_i}x_i+ ∆>0)]x_i ∂Wyi∂Lossi=−[j=yi∑1(WjTxi−WyiTxi+∆>0)]xi
则 L o s s i Loss_i Lossi对一个 W j W_{j} Wj求偏导可以得到:
∂ L o s s i ∂ W j = 1 ( W j T x i − W y i T x i + ∆ > 0 ) ] x i \frac{\partial Loss_i}{\partial W_{j}} =1(W^T_jx_i-W^T_{y_i}x_i+ ∆>0)]x_i ∂Wj∂Lossi=1(WjTxi−WyiTxi+∆>0)]xi
其中 1 ( 条 件 ) 1(条件) 1(条件) 为指示函数,当括号里的条件成立时它等于1,否则等于0。
4. 优化方法
采用梯度下降优化方法:
while True:
//求解梯度
weights_grad = gradient(loss_fun, data, weights)
//调整权重
weights += - step_size * weights_grad
至此,一套线性分类器的流程就走完了。