如何用python爬虫爬取比特币行情数据
由于2018年比特币价格走势和A股市场的走势相关性很高,因此笔者就想基于此构建一个统计套利策略看下效果。自然的,数据是最基本的。可是找来找去,只发现Tushare免费提供了数字货币的相关数据,但是却没有提供笔者想要的数据,最后无奈之下,想到了爬虫,于是就想着毕竟之前也看过一些,可以试试自己去官网上直接爬取,没想到,之前学的一点爬虫还是派上用场了,成功获取了需要的数据,特此总结记录一下,以便以后查阅。
笔者目前需要的数据是coinmarketcap网站提供的全球数字货币交易所的历史比特币成交量加权价格和美国gemini交易所的下午4点的历史拍卖价格这两类数据,前者是为了看下比特币总体的价格走势,后者才是真实用在策略中的数据,因为美国的CBOE推出的比特币期货是以后者为结算价的。当然,笔者这里只是粗略的看下策略效果,没有用到期货数据。下面具体讲是如何通过爬虫爬取这两类数据的。
首先需要说明的一点是,很多网站都提供了API,用户可以直接通过其提供的API进行数据获取,这样可以直接获取到相应格式的数据,不需要网页解析什么的,可以省去很多事;其中coinmarketcap和gemini也都提供了公共API,用户可以直接使用,但是对于genimi提供的API,只可以获取近7天的数据,所以笔者就利用的次一点的方法——爬虫,当然这也是无奈之举;对于coinmarketcap,笔者就直接爬虫爬取了,因为其实也比较简单。coinmarketcap和gemini这两个网站的网页加载技术还比较简单,对于需要的数据所在页面,并没有用到AJAX,即异步加载技术,因此在请求网页数据的时候,url地址就不需要逆向分析,直接简单的观察就可以看出url的规律,因此在获取网页数据的时候,就省事了很多。特别是coinmarketcap,其历史数据可以直接在一个页面中全部显示,如图一,直接选择All Time,就会在一个网页中显示出所有的历史数据,所以只需要发起一次请求就行,剩下的就是网页代码解析了。
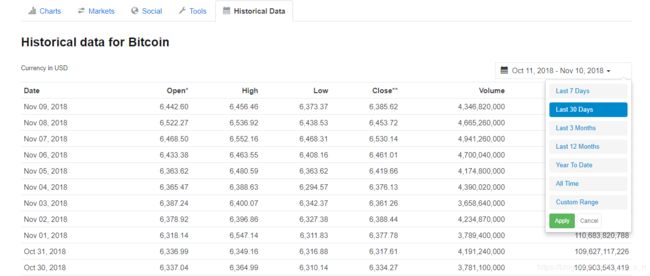 (图一)
(图一)
在获取了网页数据之后,笔者是通过xpath语法从网页代码中提取需要的数据的,在提取数据时,可以直接用chrome查看网页源代码,并定位到需要的数据上,然后在对应的代码上右键点击选择copy中的copy xpath,就可以直接利用得到的xpath进行分析,这样可以很有效的定位到需要的数据,如图二,可以看到网页源代码中有很多的tr标签,实际上就对应着左侧多行的数据。
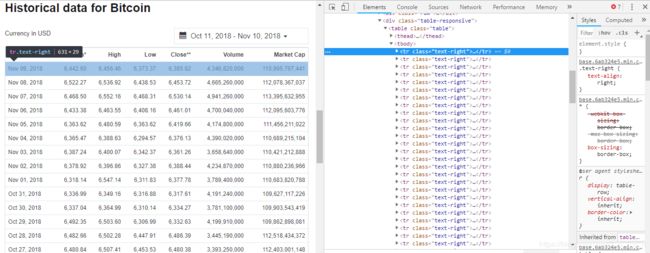 (图二)
(图二)
下面的具体的代码,需要用到的requests库用来请求网页,这个网站可以不用请求头直接利用url地址获取,lxml库用来解析获取到的html网页,然后再利用xpath来提取相应的数据,如代码块一所示。代码写的比较粗糙,其中数据处理的逻辑也有点繁琐,大家只看整体的网页获取和解析,以及数据提取的整体步骤就行。
import requests
from lxml import etree
import pandas as pd
import numpy as np
res1=requests.get(r'https://coinmarketcap.com/currencies/bitcoin/historical-data/?start=20130428&end=20181109')
selector=etree.HTML(res1.text)
url_infos=selector.xpath('//tr[@class="text-right"]')
#从获取的网页代码中提取需要的数据
data=[]
for url_info in url_infos:
l=[]
#获取单行数据并做初步处理
for i in range(7):
d=url_info.xpath('td[%d+1]/text()'%i) #这里不能直接在字符串中用i做加法运算,而要通过格式化表达进行识别,不然无法识别参数i
if i==0:
l+=d
else:
if d[0]=='-':
d[0]=np.nan
l+=d
else:
d[0]=d[0].replace(',','')
d[0]=float(d[0])
l+=d
data.append(l)
arr=np.array(data)
df=pd.DataFrame(arr) #将数据转为DataFrame数据类型
df.columns=['date','open','high','low','close','volume','Market Cap']
df['date']=df['date'].map(pd.to_datetime)(代码块一)
接下来是关于获取gemini交易所数据,这个网站和coinmarketcap不同的点在于其数据是分页显示的,因此需要发起多次请求如图三所示,一共分成38页显示;而且这个网站还必须加入请求头User-Agent参数伪装成浏览器才可以获取到数据,由于需要多次获取,而且获取的数据量也不大,因此笔者每次获取后进行了两秒钟的休眠,防止网站发现请求频率过高禁掉我的ip。其他的过程和coinmarketcap一样,代码有点不一样,具体代码可参见代码块二。
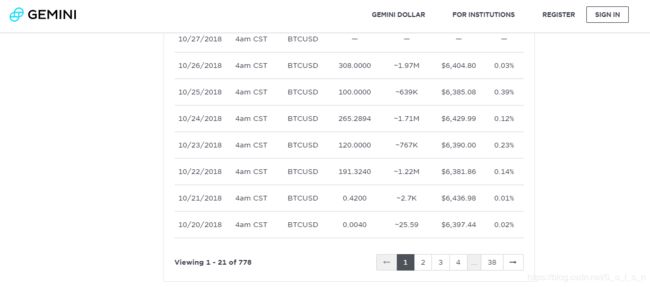 (图三)
(图三)
import requests
from lxml import etree
import pandas as pd
import numpy as np
import time
#此方法用于从标签中提取数据
def get_info(url_infos):
l=[]
for url_info in url_infos:
sub_l=[]
for j in range(7):
j+=1
if j<3:
dt=url_info.xpath('td[%d]/time/text()'%j)
sub_l+=dt
else:
dt=url_info.xpath('td[%d]/text()'%j)
sub_l+=dt
l.append(sub_l)
return l
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36'}
data=[]
for i in range(38):
i+=1
url=r'https://gemini.com/auction-data/?currentPage=%d&startIndex=1&filter=4PM-BTC-USD'%i
res=requests.get(url,headers=headers)
selector=etree.HTML(res.text)
url_infos=selector.xpath('//*[@id="auctionData"]/table/tbody/tr')
data_sub=get_info(url_infos)
data+=data_sub
time.sleep(2) #休眠两秒以降低请求频率
arr=np.array(data)
df=pd.DataFrame(arr)
df.columns=['date','time','symbol','volume','notional usd','price','absolute diff']
df[df=='—']=np.nan(代码块二)