【图像描述论文笔记】Mind’s Eye: A Recurrent Visual Representation for Image Caption Generation
Mind’s Eye: A Recurrent Visual Representation for Image Caption Generation(cvpr 2015)
- 前言(与该论文无关)
- 主要思想
- 简介
- 具体方法
- 优化目标
- 模型结构
- 总结
- 后记
前言(与该论文无关)
先说一下这篇文章我读完的个人感受啊。在我已经了解了很多时新的图像描述方法之后,这篇文章中所提出的一种“新”的RNN就有点相形见绌了。不过这只是我们站在上帝视角的看法。这篇文章既然能入选cvpr 2015,那肯定也是有点东西的,估计有些内在美还没有被我发现叭。
还是延续上一篇论文笔记的风格,只介绍模型和里面所用到的一些算法,实验部分就一笔带过辣。这个周末准备作一篇真正意义上图像描述入门级的论文的解读,就作为这周笔记的压轴吧。而这篇呢,恕我直言,就当作开胃小菜好了(没有任何贬低的意思)。接下来跟随我的解读大家大概也会有这样的想法。
主要思想
这篇论文主要的研究内容是图片与描述的双向映射。没错,在生成的图像描述的同时,作者希望计算机能像人类一样听到一幅描述后能自动“联想”出一幅画面(即找到与描述最匹配的图像映射)。对这个想法来讲的关键的在于能找到这样一个RNN,在接收到文字信息时能够动态地建立相应地视觉表述,并且能够一直记得这样地对应关系。
而作者提出的这个模型貌似已经能够很好地完成从图像到描述或者从描述到图像这两个相反的过程。并且在句子生成、句子检索和图像检索等2几个小任务上验证了该模型地可行性。其中生成图像描述的任务可以几乎达到当时最好的效果,而另外两个任务甚至能得到比现有成果更好的效果。
这样一看这篇论文与我研究的图像描述就有一丢丢的偏差了,毕竟人家作者主打的是后面两个任务的结果嘛,不过这也不妨我们继续看看他的方法,我这个人就是喜欢博采众长。既然他的方法能几乎达到最好水平,那就学习一下吧。
简介
A good image description is often said to “paint a picture in your mind’s eye.”
一个生动的图像描述就像“在心灵的眼睛上画了一幅画”。
作者如是说。
联想到这篇论文的标题:Mind’s Eye: A Recurrent Visual Representation for Image Caption Generation。这里的心里之眼正对应后文作者提出的让计算机记住图片的方法,嗯哼骚呢,看来和在下一样也是个诗人哈哈哈。
回到正题。人们往往通过生成一幅精神画面,而会对某样东西或某段文字更加映像深刻。正如下图:

这个我表示很赞同,平时背书也没有逐字背诵,而是把要背的那页纸映在脑海中,这样不用背就可以记得,亲测有效噢!
由此,作者希望也能够通过某种方法也让电脑这样记住图像与描述的对应,那么问题来了:
Critical to both of these tasks is a novel representation that dynamically captures the visual aspects of the scene that have already been described.
这两个任务的关键是一种新颖的表示形式,它可以动态捕获已经描述的场景的视觉方面。重中之重呢是动态这个词!!那么我们接下来也进入我们这篇文章的重中之重啦,模型。
具体方法
优化目标
我们有两个方向的目标:
-
First, we want to be able to generate sentences given a set of visual observations or features.
首先,我们想要在接受一组视觉特征后模型可以产生句子。简而言之就是,在时间步t接受到先前产生的单词Wt−1 = w1,…,wt−1和已观察的特征V之后,计算出一个单词Wt产生的可能性。 -
Second, we want to enable the capability of computing the likelihood of the visual features V given a set of spoken or read words Wt for generating visual representations of the scene or for performing image search.
其次,我们希望能够计算给定一组单词Wt的视觉特征V的似然估计,以生成场景的视觉表示或执行图像搜索。
为了完成这两个目标,我们需要引入一个潜在变量U,用来对先前生成或读取的单词Wt-1的视觉解释进行编码。同时这个U在对单词的视觉记忆中起很大的作用。那么有了U,我们的优化目标就变为P(wt|V,Wt−1,Ut−1) 和P(V |Wt−1,Ut−1),最终目标可以把这两个概率结合起来:
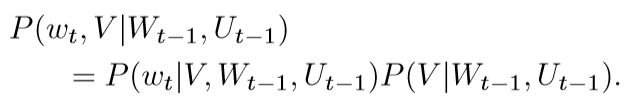
同时作者指出,在先前的一些工作中的优化目标都是P(wt|V,Wt−1)而不是P(V |Wt−1)。
模型结构
该论文的模型是建立在前人模型的基础之上,那我们得先简单介绍一下前人所提出的这种RNN。如图:

这幅图中绿色的部分就是啦。其中Wt与V在上文已经介绍过了,而St即代表在t时间步的状态,即前文的语境义。那么显而易见,w˜t就是每个单词生成的似然值。当然啦,图中的蓝色部分是作者在此模型上添加的(前文介绍过的U)。
在生成描述时,该模型会将相关的图像记忆U与现在读入的图像V相比较,从而生成图像描述。当时间步刚开始时,U代表图像特征的先验概率。随着训练的进行,图像特征也会随之更新以表示不同单词的视觉特征。这个有点像聚类了,比如在看到水池而生成“sink”时,其他与火炉或者冰箱对应的图像记忆值会增加,因为他们与水池有相似之处。
读到这里的时候我就有了满头的包,这他喵的不是模仿的LSTM嘛?
好了实验部分不多赘述。
总结
总之,该论文描述了第一个能够生成新颖的图像描述和视觉特征的双向模型。该模型用了一个来记录“记忆“的参数,在读取或者生成新单词时建立对应的视觉特征。
主要贡献为(以下我就懒了一下上了原文的话及翻译):
-
A bi-directional mapping model using recurrent neural networks: unlike previous approaches which map both sentences and images to a common embedding ( and then calculate the similarity and match / generate, I guess ) that may be used for image search or for ranking image captions.
使用递归神经网络的双向映射模型:与以前的方法不同,以前的方法将句子和图像都映射到共同的嵌入(然后计算相似性并匹配/生成,我想是),该嵌入可用于图像搜索或对图像标题进行排名 。 -
A bi-directional representation: generates both novel descriptions from images and visual representations from descriptions.
双向表示:从图像生成新颖的描述,并从描述生成视觉表示。 -
A novel recurrent visual memory: automatically learns to remember long-term visual concepts.
新颖的经常性视觉记忆:自动学习记住长期的视觉概念。
后记
由于这篇论文与LSTM太相似的,读来并没有太大的收获。不过我并没有这个资格去评判论文的好坏,毕竟在2015年能写出这样的文章已经算是很难得了,尤其是那个时候图像描述方面才算刚刚起步。不论如何,这篇文章还是有很多好的想法值得借鉴的。我现在这个阶段要做的就是通读论文,学学别人是如何找到一个好的点来些论文的。