微博爬虫及舆情分析-4.用户舆情分析
import pandas as pd
import numpy as np
#读取训练数据集
mblog=pd.read_csv('clean_mblog.csv',encoding='utf_8_sig')
mblog.head()
import jieba.analyse
def get_keywords(raw):
if raw['isLongText'] == 1:
# 当text为长文本时,提取50个关键词
keywords = jieba.analyse.extract_tags(raw['chinese_text'],topK=50)
keywords = '|'.join(keywords)
return keywords
else:
# 当text为非长文本时,默认提取20个关键词
keywords = jieba.analyse.extract_tags(raw['chinese_text'])
keywords = '|'.join(keywords)
return keywords
#生成keyword数据
mblog['keywords'] = mblog.apply(get_keywords,axis=1)
#导入逻辑回归模型
from sklearn.linear_model import LogisticRegression
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer(max_features=2000,analyzer='word',tokenizer=lambda s:s.split('|'))
#生成词袋向量数据
blog_bow = vectorizer.fit_transform(mblog['keywords'])
#选定训练样本数据
y = mblog[mblog['attitude'].notnull()]['attitude']
X=blog_bow[:len(y),:]
#训练模型并查看训练准确率
lr_model = LogisticRegression(random_state=0,solver='lbfgs',multi_class='multinomial').fit(X,y)
lr_model.score(X,y)
# 0.99
# 对其他微博进行预测并查看结果
print(mblog.chinese_text.iloc[8])
print(lr_model.predict(blog_bow[8,:]))
华为Mate30保护壳曝光,感觉好丑啊
[0.]
在训练样本中该条微博被人工标注为-1:消极
但模型在预测时将其标注为0:中性
#查看训练数据各种态度的分布情况
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
%matplotlib inline
predict_attitude = pd.DataFrame(lr_model.predict(blog_bow[:,:]),columns=['predict'])
plt.figure(figsize=[15,5])
plt.subplot(1,2,1)
labels = ['消极','中立','积极']
plt.title('训练数据各种态度的分布情况')
mblog.groupby('attitude').size().plot.pie(labels=labels,autopct='%1.1f%%',explode=(0.05,0.05,0.05),shadow=True)
plt.subplot(1,2,2)
labels = ['消极','中立','积极']
plt.title('全部预测结果的态度分布情况')
predict_attitude.groupby('predict').size().plot.pie(labels=labels,autopct='%1.1f%%',explode=(0.05,0.05,0.05),shadow=True)
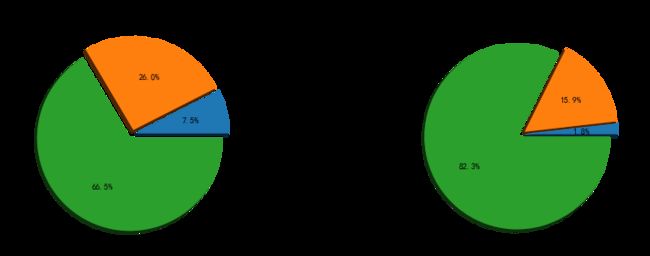
模型分析:
根据预测的多个微博数据结果,模型把大部分微博都预测为了积极的,分析数据的特点,推测可能是由于数据的分布极不均匀导致的
查看各种态度的分布情况可验证这一推测。