机器学习教程 四.KNN(k最近邻)算法理解和应用
导语:商业哲学家 Jim Rohn 说过一句话,“你,就是你最常接触的五个人的平均。”那么,在分析一个人时,我们不妨观察和他最亲密的几个人。同理的,在判定一个未知事物时,可以观察离它最近的几个样本,这就是 kNN(k最近邻)的方法。
我们现在开始一个新的部分:分类算法。在分类算法中,我们将介绍两个主要的算法:K近邻(KNN)和支持向量机(SVM)。虽然这两种算法都是分类算法,但他们有很大区别的。我们今天从这博客主要学习KNN算法,我将学到:
1.KNN算法的概述
2.利用sklearn中的自带KNN算法对乳腺癌(UCI数据集)分类
3.自定义KNN算法对乳腺癌(UCI数据集)分类
首先我们先创建下图数据集:
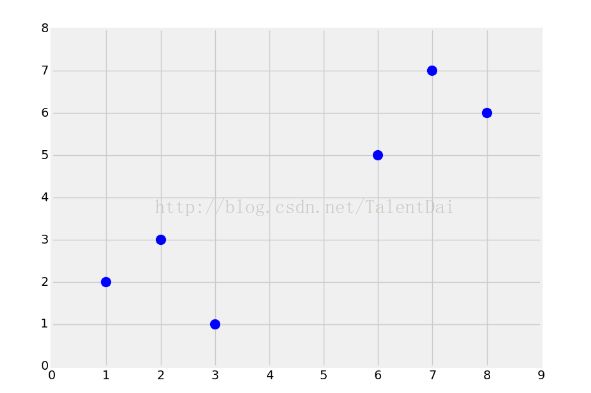
直观上,我们可以将数据集分为两组。分类算法属于监督机器学习,当我们将数据输入机器学习算法时,我们实际上已经告诉它组存在,且属于哪个组。还有一种类似的机器学习形式,算法自动发现它属于的组,叫做聚类,这是一种非监督机器学习方法,我们将在后面的系列中介绍。因此,在有监督学习的情况下,我们实际上会将被标记的数据用于训练:

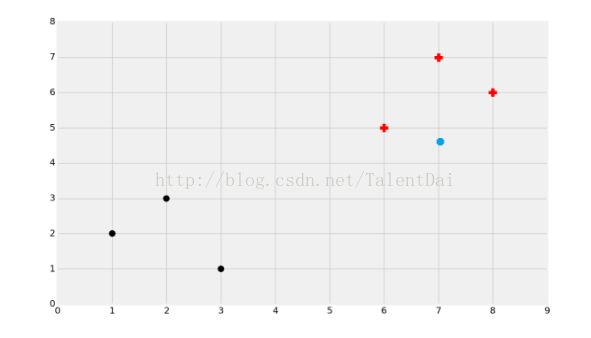
在这种情况下,选择有点难,不过大多数人会选择黑色。考虑一下你为什么做出这些选择?大多数人都会按照距离将这些数据集进行分组,这是最直观的感觉。#如果你拿出一把直尺,把这个点到最近的黑点直线的距离,和最近的红色加号的距离作比较,你会发现黑点确实更接近了。同理,我们可以跟训练数据里的每个点求距离,然后挑离这个训练数据最近的K个点看看这几个点属于什么类型,然后用少数服从多数的原则,给新数据归类。因此,机器学习算法诞生了:K近邻。
老规矩,在本教程中,我们将实际应用一个简单的算法示例,使用scikit- learn,然后我们将构建我们自己的算法,以了解更多关于它工作原理。为了举例说明分类,我们将使用一个乳腺癌数据集,它是加利福尼亚大学欧文分校(UCI)的数据集,UCI有一个大型机器学习存储仓库,我们可以在里面下载相应数据集玩耍啦。。。从乳腺癌数据集页面,选择Data Folder 链接,里面包含breast-cancer-wisconsin.data 和 breast-cancer-wisconsin.names两个文件,这两个文件不是下载下来的,而是用鼠标右键另存为保存的。从breast-cancer-wisconsin.names里面我们可以了解到数据集的属性,我们把相应的属性:(id,clump_thickness,uniform_cell_size,uniform_cell_shape,marginal_adhesion,single_epi_cell_size,bare_nuclei,bland_chromation,normal_nucleoli,mitoses,Class)填入breast-cancer-wisconsin.data第一行,好的一个完美的数据集生成了。。我先得做预处理我们观察数据集,发现id这列不是我们需要的我们需要把它删除,对于缺失值我们选择填补,撸起袖子开始干吧:
#导入库
import numpy as npfrom sklearn import preprocessing, cross_validation, neighbors
import pandas as pd
#预处理数据
df = pd.read_csv('breast-cancer-wisconsin.data.txt')df.replace('?',-99999, inplace=True)
df.drop(['id'], 1, inplace=True)
print(df.head())
我们看一下数据:

我们从breast-cancer-wisconsin.names文件中可以了解到,数据集中缺失值用'?'填补的,如果我们直接输入到算法,肯定会报错,所以我们做了 简单的处理,填补‘-999999’接下来,我们定义特征(X)和标签(y):
X = np.array(df.drop(['class'], 1))
y = np.array(df['class'])
然后我们很自然复制我第二篇博客步骤,我们使用scikits-learn中的cross_validation.train_test_split来创建训练和测试样本:
X_train, X_test, y_train, y_test = cross_validation.train_test_split(X, y, test_size=0.2)
# 定义K近邻分类器
clf = neighbors.KNeighborsClassifier()
# 训练分类器
clf.fit(X_train, y_train)
# 测试
accuracy = clf.score(X_test, y_test)
print(accuracy)
结果如下:
![]()
很棒,这精确度!!!接下来我要做一件有趣的事,我们不去除没有意义的数据(id)看看测试的结果,我直接copy前面的代码:
import numpy as np
from sklearn import preprocessing, cross_validation, neighbors
import pandas as pd
df = pd.read_csv('breast-cancer-wisconsin.data.txt')
df.replace('?',-99999, inplace=True)
#df.drop(['id'], 1, inplace=True)
X = np.array(df.drop(['class'], 1))
y = np.array(df['class'])
X_train, X_test, y_train, y_test = cross_validation.train_test_split(X, y, test_size=0.2)
clf = neighbors.KNeighborsClassifier()
clf.fit(X_train, y_train)
accuracy = clf.score(X_test, y_test)
print(accuracy)
结果为:
![]()
看到没,没有意义的数据喂给算法,精确度真的不忍直视。所以数据预处理和特征工程非常重要,这里我希望你们看知乎中这篇文章(特征工程),接下来我们将从头开始构建我们自己的K近邻算法,而不是使用scikit- learn中现成的(不要只会做掉包侠呦),我们需要尝试更多地了解算法,了解它是如何工作的,最重要的是,了解他们的优缺点,在什么条件下使用最好,这样我们在机器学习的 海洋中就可以运筹帷幄了。。其实KNN的指导思想很简单,正所谓“近朱者赤,近墨者黑”,由你的邻居来推断出你的类别。
实现KNN算法步骤如下:
1)算距离:给定测试对象,计算它与训练集中的每个对象的距离
2)找邻居:圈定距离最近的k个训练对象,作为测试对象的近邻
3)做分类:根据这k个近邻归属的主要类别,来对测试对象分类
我们开始第一步:算距离,这里我只介绍其中的一种,欧式距离: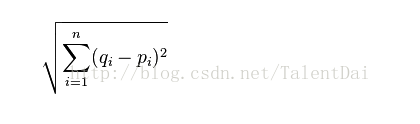
是不是很简单?说直白点它就是每个点的距离的平方和的平方根,我们自己创建两个点:
import math
plot1 = [1,3]
plot2 = [2,5]
euclidean_distance = math.sqrt( (plot1[0]-plot2[0])**2 + (plot1[1]-plot2[1])**2 )
print(euclidean_distance)
我们可以看看这两点的距离:
![]()
接下来我们开始正式coding啦:首先我们先导入相应的库:
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import style
import warnings
from math import sqrt
from collections import Counter
style.use('fivethirtyeight')
# 然后创建数据集:
dataset = {'k':[[1,2],[2,3],[3,1]], 'r':[[6,5],[7,7],[8,6]]}
new_features = [5,7]
# dataset(数据集)只是一个Python字典,其中的键看作类,后面的值看做这个类相关的数据点,new_features是我们想要测试的数据。
# 我们可以做一个快速的图表:
for i in dataset:
for ii in dataset[i]:
plt.scatter(ii[0],ii[1],s=100,color=i)
plt.scatter(new_features[0], new_features[1], s=100)
plt.show()
这段代码的效果图如下:

我们可以看到明显的红色和黑色部分,蓝色的点是new_features,我们将尝试对其进行分类。下面我们开始定义KNN函数了:
def k_nearest_neighbors(data, predict, k=3):
if len(data) >= k:
warnings.warn('K is set to a value less than total voting groups!')
distances = []
for group in data:
for features in data[group]:
euclidean_distance = sqrt( (features[0]-predict[0])**2 + (features[1]-predict[1])**2 )
distances.append([euclidean_distance,group])
# i[0]为距离,i[1]为类别,我们需要的是类别
votes = [i[1] for i in sorted(distances)[:k]]
vote_result = Counter(votes).most_common(1)[0][0]
return vote_result
这里我们默认k值为3,如果选择小的k值,则只有和输入实例比较近的点才会对预测结果产生影响,这样做会导致分类系统的抗噪声能力弱,如果输入实例附近恰好有噪声,分类就极大地可能出错,导致过拟合。如果选择大的k值,相当于在较大领域进行预测,假设k值和数据集数据的个数一样,则无论输入什么实例,都将分类为数据集中数量最多的类别。一般情况下,k值选取一个比较小的数值。通常使用交叉验证法选取最优k值。上面函数我简单做个介绍,我们先定义一个列表,里面准备放欧式距离(new_features和dataset之间的距离) 和当前dataset中点所属类别(比如dataset中【1,2】属于k类),然后我需要利用for循环计算前K个点所属的类别,所以这些是3票,我们将使用Python标准库模块的Counter函数来统计票数,我们开始做图:
dataset = {'k':[[1,2],[2,3],[3,1]], 'r':[[6,5],[7,7],[8,6]]}
new_features = [5,7]
for i in dataset:
for ii in dataset[i]:
plt.scatter(ii[0],ii[1],s=100,color=i)
plt.scatter(new_features[0], new_features[1], s=100)
result = k_nearest_neighbors(dataset, new_features)
plt.scatter(new_features[0], new_features[1], s=100, color = result)
plt.show()
看看我们的效果:
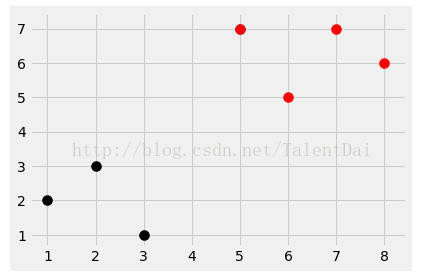
看到没有?正如我们想看到的,完美的分类,科学是严谨的,我需要看看那么我们这个算法精确度怎么样?我们来回顾一下乳腺癌数据集,用scikit - learn K近邻给了我们93%的准确率,现在我们要测试我们自己的算法到底怎么样?
import numpy as np
import warnings
from collections import Counter
import pandas as pd
import random
def k_nearest_neighbors(data, predict, k=3):
if len(data) >= k:
warnings.warn('K is set to a value less than total voting groups!')
distances = []
for group in data:
for features in data[group]:
euclidean_distance = sqrt( (features[0]-predict[0])**2 + (features[1]-predict[1])**2 )
distances.append([euclidean_distance,group])
# i[0]为距离,i[1]为类别,我们需要的是类别
votes = [i[1] for i in sorted(distances)[:k]]
vote_result = Counter(votes).most_common(1)[0][0]
return vote_result
df = pd.read_csv('breast-cancer-wisconsin.data.txt')
df.replace('?',-99999, inplace=True)
df.drop(['id'], 1, inplace=True)
# 一些数据点虽然是数字,但是字符串数据类型,我们将整个dataframe转换为float
full_data = df.astype(float).values.tolist()
# 接下来,我们将对数据进行shuffle,然后将其拆分:
random.shuffle(full_data)
test_size = 0.2
# 2代表良性肿瘤,4代表恶性肿瘤
train_set = {2:[], 4:[]}
test_set = {2:[], 4:[]}
train_data = full_data[:-int(test_size*len(full_data))]
test_data = full_data[-int(test_size*len(full_data)):]
# 现在我们有了和测试集相同的字典,其中的键是类,值是属性。
for i in train_data:
train_set[i[-1]].append(i[:-1])
for i in test_data:
test_set[i[-1]].append(i[:-1])
correct = 0
total = 0
# 我k值选择了5,因为这是Scikit学习KNeighborsClassifier的默认值。
for group in test_set:
for data in test_set[group]:
vote = k_nearest_neighbors(train_set, data, k=5)
if group == vote:
correct += 1
total += 1
print('Accuracy:', correct/total)
结果如下:
![]()
我们的KNN分类器还是可以的,哈哈哈。。。现在我们对KNN有了直观的了解了,但这还不够,我们还需多翻翻资料,看优秀代码来巩固今天所学的。。。下一篇博客 我们将要学一个新的算法SVM(支持向量机)