《C++ Primer》学习笔记(五):循环、分支、跳转和异常处理语句
专栏C++学习笔记
《C++ Primer》学习笔记/习题答案 总目录
- https://blog.csdn.net/TeFuirnever/article/details/100700212
——————————————————————————————————————————————————————
- 《C++ Primer》习题参考答案:第5章 - 循环、分支、跳转和异常处理语句
文章目录
- 专栏C++学习笔记
- [Cpp-Prime5 + Cpp-Primer-Plus6 源代码和课后题](https://github.com/TeFuirnever/Cpp-Primer-Plus-Plus-Plus)
- 循环、分支、跳转和异常处理语句
- 1、简单语句
- 2、语句作用域
- 3、条件语句
- 1)if语句
- 2)switch语句
- 4、迭代语句
- 1)while语句
- 2)传统的for语句
- 3)范围for语句
- 4)do-while语句
- 5、跳转语句
- 1)break语句
- 2)continue语句
- 3)goto语句
- 6、try语句块和异常处理
- 1)throw表达式
- 2)try语句块
- 3)标准异常
- 参考文章
Cpp-Prime5 + Cpp-Primer-Plus6 源代码和课后题
循环、分支、跳转和异常处理语句
1、简单语句
通常情况下,语句是顺序执行的,但除非是最简单的程序,否则仅有顺序执行远远不够。因此, C++语言提供了一组 控制流(flow-of-control) 语旬以支持更复杂的执行路径。
C++语言中的大多数语句都以分号结束,一个表达式加上 ; 就变成了 表达式语句(expression statement)。如果在程序的某个地方,语法上需要一条语句但是逻辑上不需要,则应该使用 空语句(null statement),空语句中只含有一个单独的分号 ;。
ival + 5; // 一条没什么实际用处的表达式语句
cout << ival; // 一条有用的表达式语句
// 重复读入数据直至到达文件末尾或某次输入的值等于sought
while (cin >> s && s != sought)
; // 空语句
使用空语句时应该加上注释,从而令读这段代码的人知道该语句是有意省略的。
不要漏写分号 ;!!!不要漏写分号 ;!!!不要漏写分号 ;!!!重要的事情说三遍,另外,也不要多写分号,即空语句,多余的空语句并非总是无害的。
ival = vl + v2;; // 正确: 第二个分号表示一条多余的空语句
// 出现了糟糕的情况:额外的分号,循环体是那条空语句
while (iter != svec.end()) ; // while循环体是那条空语句
++iter; // 递增运算不属于循环的一部分
复合语句(compound statement) 是指用花括号括起来的(可能为空)语句和声明的序列,也叫做块(block),一个块就是一个作用域,在块中引入的名字只能在块内部以及嵌套在块中的子块里访问。通常,名字在有限的区域内可见,该区域从名字定义处开始,到名字所在(最内层)块的结尾处为止。
如果在程序的某个地方,语法上需要一条语句,但是逻辑上需要多条语句,则应该使用复合语句。把要执行的语句用花括号括起来, 就将其转换成了一条(复合〉语句。
while (val <= 10) {
sum += val; // 把sum+val的值赋给sum
++val; // 给val加1
}
语句块不以分号作为结束。
所谓空块, 是指内部没有任何语句的一对花括号。空块的作用等价于空语句:
while (cin >> s && s != sought)
{ } // 空块
2、语句作用域
可以在 if、switch、while 和 for 语句的控制结构内定义变量,这些变量只在相应语句的内部可见,一旦语句结束,变量也就超出了其作用范围。
while (int i = get_num()) // 每次迭代时创建并初始化i
cout << i << endl;
i = 0; // 错误:在循环外部无法访问i
如果其他代码也需要访问控制变量,则变量必须定义在语句的外部:
// 寻找第一个负位元素
auto beg = v.begin();
while (beg != v.end() && *beg >= 0)
++beg;
if (beg == v.end())
// 此时我们知道v中的所有元素都大于等于0
因为控制结构定义的对象的值马上要由结构本身使用,所以这些变量必须初始化。
3、条件语句
1)if语句
if 语句的形式:
if (condition)
statement
if-else 语句的形式:
if (condition)
statement
else
statement2
其中 condition 是判断条件,可以是一个表达式或者初始化了的变量声明,condition 必须用圆括号括起来。
- 如果 condition 为真,则执行 statement。执行完成后,程序继续执行
if语句后面的其他语句。 - 如果 condition 为假,则跳过 statement。对于简单
if语句来说,程序直接执行if语句后面的其他语句;对于if-else语句来说,程序先执行 statement2,再执行if语句后面的其他语句。
if 语句可以嵌套,其中 else 与离它最近的尚未匹配的 if 相匹配。
记得用花括号 {},否则很容易出现一个错误,就是本来程序中有几条语句应该作为一个块来执行,最后没有。。。这一点要和 python 区别开,因为 python 是以缩进分块的。为了避免此类问题,强烈建议在 if 或 else 之后必须写上花括号(对 while 和 for 语句的循环体两端也有同样的要求),这么做的好处是可以避免代码混乱不惰,以后修改代码时如果想添加别的语旬,也可以很容易地找到正确位置。
当代码中 if 分支多下 else 分支时,C++规定 else 与离它最近的尚未匹配的 if 匹配,从而消除了程序的二义性。
// 错误:实际的执行过程并非像缩进格式显示的那样,else分支匹配的是内层if语句
if (grade % 10 >= 3)
if (grade %10 > 7)
lettergrade +='+'; // 末尾是8或者9的成绩添加一个加号
else
lettergrade += '-';
// 等价于 <=>
// 违背了初衷
if (grade % 10 >= 3)
if (grade %10 > 7)
lettergrade +='+'; // 末尾是8或者9的成绩添加一个加号
else
lettergrade += '-'; // 末尾是3、4、5、6或者7的成绩添加一个减号!
要想 else 分支和外层的 if 语句匹配起来,可以在内层 if 语句的两端加上花括号, 使其成为一个块:
// 错误:实际的执行过程并非像缩进格式显示的那样,else分支匹配的是内层if语句
if (grade % 10 >= 3) {
if (grade %10 > 7)
lettergrade +='+'; // 末尾是8或者9的成绩添加一个加号
} else
lettergrade += '-'; // 末尾是1或者2的成绩添加一个减号!
最初的想法是如果 >=3,则进入嵌套判断——如果 >7,那么输出一个带 + 的结果;如果 <3,则输出一个带 - 的结果。写成一个分段函数的话就是:
o u t = { x − ( g r a d e % 10 < 3 ) x ( 7 > = g r a d e % 10 > = 3 ) x + ( g r a d e % 10 > 7 ) out=\left\{ \begin{array}{rcl} x- & & {(grade \% 10 < 3)}\\ x & & {(7 >= grade \% 10 >= 3)}\\ x+ & & {(grade \% 10 > 7)} \end{array} \right. out=⎩⎨⎧x−xx+(grade%10<3)(7>=grade%10>=3)(grade%10>7)
写错之后就变成了:
o u t = { x − ( 7 > = g r a d e % 10 > = 3 ) x + ( g r a d e % 10 > 7 ) out=\left\{ \begin{array}{rcl} x- & & {(7 >= grade \% 10 >= 3)}\\ x+ & & {(grade \% 10 > 7)} \end{array} \right. out={x−x+(7>=grade%10>=3)(grade%10>7)
测试用例:
#include 如上面的程序,可以使用 22 进行测试:
- 如果不是最初的想法的话,输出结果应该是22。
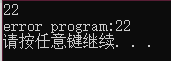
- 如果是最初的想法的话,输出结果应该是22-;

2)switch语句
switch 语句的形式:

举一个例子,输入文本,统计五个元音字母在文本中出现的次数,程序如下:
#include 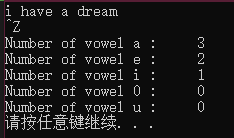
switch 语句先对括号里的表达式求值,值转换成整数类型后再与每个 case 标签(case label)的值进行比较(case 标签必须是整型常量表达式)。如果表达式的值和某个 case 标签匹配,程序从该标签之后的第一条语句开始执行,直到到达 switch 的结尾或者遇到 break 语句为止。
通常情况下每个 case 分支后都有 break 语句,如果确实不应该出现 break 语句,最好写一段注释说明程序的逻辑。尽管 switch 语句没有强制一定要在最后一个 case 标签后写上 break,但为了安全起见,最好添加 break,这样即使以后增加了新的 case 分支,也不用再在前面补充 break 语句了。
另外,switch 语句中可以添加一个 default 标签(default label),如果没有任何一个 case 标签能匹配上 switch 表达式的值,程序将执行 default 标签后的语句。即使不准备在 default 标签下做任何操作,程序中也应该定义一个 default 标签,其目的在于告诉他人我们已经考虑到了默认情况,只是目前不需要实际操作。
不允许跨过变量的初始化语句直接跳转到该变量作用域内的另一个位置。如果需要为 switch 的某个 case 分支定义并初始化一个变量,则应该把变量定义在块内。
case true:
{
// 正确:声明语句位于语句块内部
string file_name = get_file_name();
// ...
}
break;
case false:
if (file_name.empty()) // 错误:file_name不在作用域之内
4、迭代语句
迭代语句通常称为循环,它重复执行操作直到满足某个条件才停止。while 和 for 语句在执行循环体之前检查条件,do-while 语句先执行循环体再检查条件。
1)while语句
while 语句的形式:
while (condition)
statement
只要 condition 的求值结果为 true,就一直执行 statement(通常是一个块)。condition 不能为空,如果 condition 第一次求值就是 false,statement 一次都不会执行。
定义在 while 条件部分或者 while 循环体内的变量,每次迭代都经历从创建到销毁的过程。在不确定迭代次数,或者想在循环结束后访问循环控制变量时,使用 while 比较合适。
vector<int> v:
int i;
// 重复读入数据,直至到达文件末尾或者遇到其他输入问题
while (cin >> i)
v.push_back(i);
// 寻找第一个负值元素
auto beg = v.begin();
while (beg != v.end() && *beg >= 0)
++beg;
if (beg == v.end())
// 此时我们知道v中的所有元素都大于等于0
2)传统的for语句
for 语句的形式:
for (initializer; condition; expression)
statement
一般情况下,initializer 负责初始化一个值,这个值会随着循环的进行而改变。condition 作为循环控制的条件,只要 condition 的求值结果为 true,就执行一次 statement,执行后再由 expression 负责修改 initializer 初始化的变量,修改发生在每次循环迭代之后,这个变量就是 condition 检查的对象。如果 condition 第一次求值就是 false,statement 一次都不会执行。statement 可以是一条单独的语句也可以是一条复合语句。
initializer 中也可以定义多个对象,但是只能有一条声明语句,因此所有变量的基础类型必须相同。
注意:for 语句头中定义的对象只在 for 循环体内可见。
for 语句头能省略掉 initializer 、condition 和 expression 中的任何一个(或者全部)。
auto beg = v.begin();
for ( /* 空语句 */; beg != v.end() && *beg >= 0; ++beg)
; //什么也不做
for (int i = 0; /* 条件为空 */ ; ++i) {
//对i进行处理,循环内部的代码必须负责终止迭代过程
}
vector<int> v;
for (int i; cin >> i; /* 表达式为空 */)
v.push_back(i);
3)范围for语句
范围 for 语句的形式:
for (declaration : expression)
statement
其中 expression 表示一个序列,拥有能返回迭代器的 begin 和 end 成员,比如用花括号括起来的初始值列表、数组或者者 vector 或 string 等类型的对象。declaration 定义一个变量,序列中的每个元素都应该能转换成该变量的类型(可以使用 auto)。如果需要对序列中的元素执行写操作,循环变量必须声明成引用类型,每次迭代都会重新定义循环控制变量,并将其初始化为序列中的下一个值,之后才会执行 statement。
vector<int> v = {O, 1, 2, 3, 4, 5, 6, 7, 8, 9};
// 范围变量必须是引用类型,这样才能对元素执行写操作
for (auto &r : v) // 对于v中的每一个元素
r *= 2; // 将v中每个元素的值翻倍
// 等价于<=>
for (auto beg = v.begin(), end = v.end(); beg != end; ++beg) {
auto &r = *beg; // r必须是引用类型,这样才能对元素执行写操作
r *= 2; // 将v中每个元素的值翻倍
}
4)do-while语句
do-while 语句的形式:
do
statement
while (condition);
do while语句应该在括号包围起来的条件后面用一个分号表示语句结束。
计算 condition 的值之前会先执行一次 statement,condition 不能为空。如果 condition 的值为 false,循环终止;否则重复执行 statement。
condition 使用的变量必须定义在循环体之外,因为 do-while 语句先执行语句或块,再判断条件,所以不允许在条件部分定义变量。
//不断提示用户输入一对数.然后求其和
string rsp; //作为循环的条件,不能定义在do的内部
do {
cout << " please enter two values: ";
int val1 = 0, val2 = 0;
cin >> val1 >> val2;
cout << "The sum of " << val1 << " and " << val2
<< " = " << val1 + val2 << "\n\n"
<< "More? Enter yes or no: ";
cin >> rsp;
} while (!rsp.empty() && rsp[0] != 'n');

5、跳转语句
跳转语句中断当前的执行过程。
1)break语句
break 语句只能出现在迭代语句或者 switch 语句的内部(包括嵌套在此类循环里的语句或块的内部),负责终止离它最近的 while、do-while、for 或者 switch 语句,并从这些语句之后的第一条语句开始执行。break 语句的作用范围仅限于最近的循环或者 switch。
string buf;
while (cin >> buf && !buf.empty()) {
switch(buf[0]) {
case '-':
// 处理到第一个空白为止
for (auto it = buf.begin()+1; it != buf.end(); ++it) {
if (*it == ' ')
break; // #1,离开for循环
// . . .
}
// 离开for循环:break #1将控制权转移到这里
// 剩余的'-'处理:
break; // #2,结束switch
case '+':
// . . .
}
// 结束switch: break #2将控制权转移到这里
} // 结束while
2)continue语句
continue 语句只能出现在迭代语句的内部,负责终止离它最近的循环的当前一次迭代并立即开始下一次迭代。continue 语句只能出现在 for、while 和 do while 循环的内部,或者嵌套在此类循环里的语句或块的内部。和 break 语句不同的是,只有当 switch 语句嵌套在迭代语句内部时,才能在 switch 中使用 continue。
continue 语句中断当前迭代后,具体操作视迭代语句类型而定:
- 对于
while和do-while语句来说,继续判断条件的值。 - 对于传统的
for语句来说,继续执行for语句头中的第三部分,之后判断条件的值。 - 对于范围
for语句来说,是用序列中的下一个元素初始化循环变量。
string buf ;
while (cin >> buf && !buf.empty()) {
if (buf[O] !='_')
continue; // 接着读取下一个输入
// 程序执行过程到了这里?说明当前的输入是以下画线开始的;接着处理buf......
3)goto语句
goto 语句(labeled statement)是一种特殊的语句,它的作用是从 goto 语句无条件跳转到同一函数内的另一条语句,在它之前有一个标识符和一个冒号。
如果能不使用
goto语句,强烈建议就不要使用了,因为它乱跳的缘故,使得程序既难理解又难修改。
goto 语句的形式:
goto label;
goto 语句使程序无条件跳转到标签为 label 的语句处执行。
end: return; // 带标签语句,可以作为goto的目标
标签标识符独立于变量和其他标识符的名字,它们之间不会相互干扰。但两者必须位于同一个函数内,同时 goto 语句也不能将程序的控制权从变量的作用域之外转移到作用域之内。
// ...
goto end;
int ix =10; // 错误:goto语句绕过了一个带初始化的变量定义
end:
// 错误:此处的代码需妥使用ix,但是goto语句绕过了它的声明
ix = 42;
6、try语句块和异常处理
异常(exception) 是指程序运行时的反常行为,这些行为超出了函数正常功能的范围。当程序的某一部分检测到一个它无法处理的问题时,需要使用 异常处理(exception handling)。
异常处理机制为程序中 异常检测 和 异常处理 这两部分的协作提供支持,包括 throw 表达式(throw expression)、try 语句块(try block)和异常类(exception class)。
- 异常检测部分使用
throw表达式表示它遇到了无法处理的问题(throw引发了异常)。 - 异常处理部分使用
try语句块处理异常。try语句块以关键字try开 始,并以一个或多个catch子句(catch clause)结束。try语句块中代码抛出的异常通常会被某个catch子句处理,catch子句也被称作异常处理代码(exception handler)。 - 异常类用于在
throw表达式和相关的catch子句之间传递异常的具体信息。
1)throw表达式
throw 表达式包含关键字 throw 和紧随其后的一个表达式,其中表达式的类型就是抛出的异常类型。throw 表达式后面通常紧跟一个分号,从而构成一条表达式语句。
// 首先检查两条数据是否是关于同一种书籍的
if (item1.isbn() != item2.isbn())
throw runtime_error("Data must refer to same ISBN");
// 如果程序执行到了这里,表示两个ISBN
cout << item1 + item2 << endl;
2)try语句块
try 语句块的通用形式:
try {
program-statements
}
catch (exception-declaration) {
handler-statements
}
catch (exception-declaration) {
handler-statements
} // . . .
try 语句块中的 program-statements 组成程序的正常逻辑,其内部声明的变量在块外无法访问,即使在 catch 子句中也不行。语句块之后是 catch 子句,catch 子句包含:关键字 catch、括号内一个对象的声明(异常声明,exception declaration)和一个块。当选中了某个 catch 子句处理异常后,执行与之对应的块。catch 一旦完成,程序会跳过剩余的所有 catch 子句,继续执行后面的语句。
while (cin >> item1 >> item2) {
try {
// 执行添加两个Sales_item对象的代码
// 如果添加失败,代码抛出一个runtime_error异常
} catch (runtime_error err) {
// 提醒用户两个ISBN必须一致,询问是否重新输入
cout << err.what()
<< "\nTry Again? Enter y or n" << endl;
char c;
cin >> c;
if (!cin || c == 'n')
break; // 跳出while循环
}
}

寻找处理代码的过程与函数调用链刚好相反。当异常被抛出时, 首先搜索抛出该异常的函数。如果没找到匹配的 catch 子句, 终止该函数, 并在调用该函数的函数中继续寻找。如果还是没有找到匹配的 catch 子句,这个新的函数也被终止, 继续搜索调用它的函数。以此类推,沿着程序的执行路径逐层回退,直至找到适当类型的 catch 子句为止。如果最终没能找到与异常相匹配的 catch 子句,程序会执行名为 terminate 的标准库函数。该函数的行为与系统有关,一般情况下,执行该函数将导致程序非正常退出。类似地,如果一段程序没有 try 语句块且发生了异常,系统也会调用 terminate 函数并终止当前程序的执行。
3)标准异常
异常类分别定义在4个头文件中:
-
头文件 exception 定义了最通用的异常类
exception。它只报告异常的发生,不提供任何额外信息。 -
头文件 stdexcept 定义了几种常用的异常类。
-
头文件 new 定义了
bad_alloc异常类。 -
头文件 type_info 定义了
bad_cast异常类。
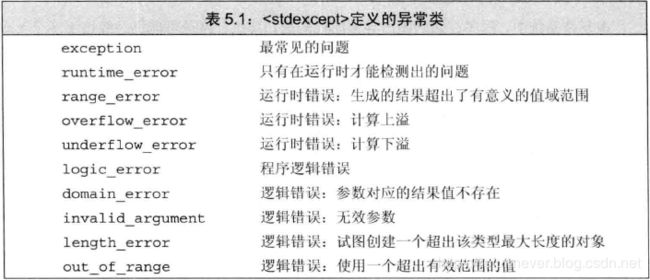
标准库异常类只定义了几种运算,包括创建或拷贝异常类型的对象,以及为异常类型的对象赋值。
标准库异常类的继承体系:
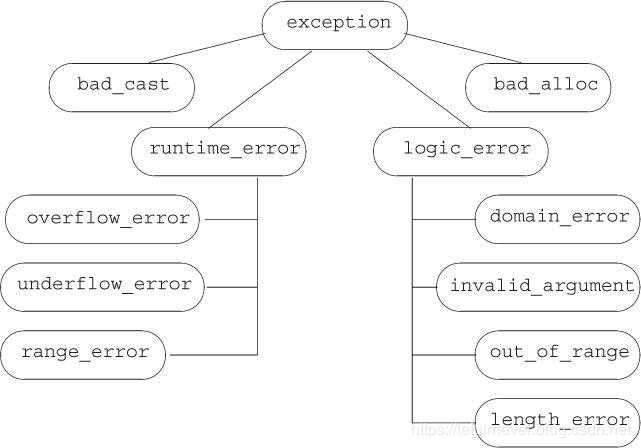
只能以默认初始化的方式初始化 exception、bad_alloc 和 bad_cast 对象,不允许为这些对象提供初始值。其他异常类的对象在初始化时必须提供一个 string 或一个C风格字符串,通常表示异常信息,但是不允许使用默认初始化的方式,且必须提供含有错误相关信息的初始值。
如果想要更多的资源,欢迎关注 @我是管小亮,文字强迫症MAX~
回复【福利】即可获取我为你准备的大礼,包括C++,编程四大件,NLP,深度学习等等的资料。
想看更多文(段)章(子),欢迎关注微信公众号「程序员管小亮」~

参考文章
- 《C++ Primer》