TDSQL在微众银行的大规模实践之路

2014年:基于分布式的基础架构
微众银行在2014年成立之时,就非常有前瞻性的确立了微众银行的IT基础架构的方向:摒弃传统的基于商业IT产品的集中架构模式,走互联网模式的分布式架构。众所周知,传统银行IT架构体系非常依赖于传统的商业数据库,商业存储以及大中型服务器设备,每年也需要巨大的IT费用去维护和升级,同时这种集中式的架构,也不便于进行高效的实现水平扩展。从过往经验来看,当时除了oracle等少数传统的商业数据库,能满足金融级银行场景的数据库产品并不多。当时腾讯有一款金融级的分布式数据库产品TDSQL,主要承载腾讯内部的计费和支付业务,其业务场景和对数据库的可靠性要求,和银行场景非常类似,同时也经受了腾讯海量计费业务场景的验证。微众银行基础架构团队,经过多轮的评估和测试,最终确定和腾讯TDSQL团队合作,共同将TDSQL打造为适合银行核心场景使用的金融级分布式数据库产品,并将TDSQL用于微众银行的核心系统数据库。
Why TDSQL?
为什么会选用TDSQL,作为微众银行的核心数据库呢?本章节将会详细介绍TDSQL架构、以及TDSQL的核心特性,看看TDSQL是如何满足了金融级场景的数据库要求。
TDSQL架构介绍
TDSQL是基于MySQL/Mariadb社区版本打造的一款金融级分布式数据库集群方案。在内核层面,TDSQL针对MySQL 社区版本和Mariadb 社区版本的内核,在复制模块做了系统级优化,使得其具备主备副本数据强一致同步的特性,极大提升了数据安全性,同时相对原生的半同步复制机制,TDSQL强一致复制的性能也有极大提升。
TDSQL集成了TDSQL Agent、TDSQL SQLEngineSQLEngine、TDSQL Scheduler等多个模块,实现了读写分离、AutoSharding、自动主备强一致性切换、自动故障修复、实时监控、实时冷备等一系列功能。TDSQL架构模型如图1所示:

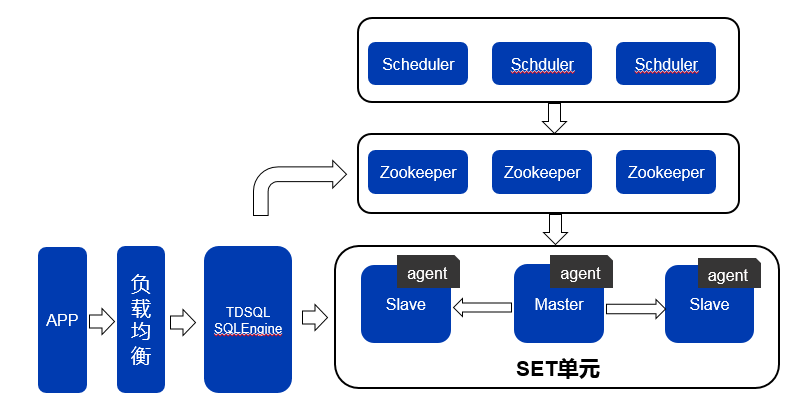
图1 TDSQL架构模型与SET模型
我们可以从横向和纵向两个维度来理解TDSQL的架构。
横向是TDSQL的请求处理路径,请过通过APP发出,经过负载均衡模块,转发到TDSQL SQLEngine集群;TDSQL SQLEngine收到请求后,进行请求解析,然后转发到set单元内的数据库实例节点上(写请求到master,读请求可以到master或slave);数据库实例处理好请求后,回包给TDSQL SQLEngine,TDSQL SQLEngine再通过负载均衡模块回包给app。
纵向是TDSQL集群的管理路径:TDSQL的一个管理单元称为一个set,每个set单元的每个数据库实例上,都会部署一个TDSQL Agent模块。Agent模块会收集所在数据库实例的所有监控信息(包括节点主备角色信息/节点存活状态/请求量/TPS/CPU负载/IO负载/慢查询/连接数/容量使用率等等),上报到zookeeper集群;zookeeper相当于整个TDSQL集群元数据存储管理中心,保存了集群所有元数据信息;TDSQL Scheduler模块会监控zookeeper的所存储的上报信息,并根据集群状态启动不同的调度任务,相当于TDSQL集群的大脑,负责整个集群的管理和调度。
TDSQL noshard与shard模式
TDSQL提供了noshard与shard两种使用模式,如图2所示。
所谓noshard模式,就是单实例模式,不做自动的分库分表,在语法和功能上完全兼容于MySQL,缺点是只支持垂直扩容,这会受限于单实例服务器的性能和容量上限,无法进行水平扩展。
Shard模式即AutoSharding模式。通过TDSQL SQLEngine模块,实现数据库的Sharding和分布式事务功能,底层的数据打散在多个数据库实例上,对应用层还是统一的单库视图。Shard模式可以实现容量和性能的水平扩展,通过两阶段XA支持分布式事务和各种关联操作,但是目前还不支持存储过程,同时在建表的时候需要业务指定shard key,对部分业务开发来说觉得会有一定的侵入性 。
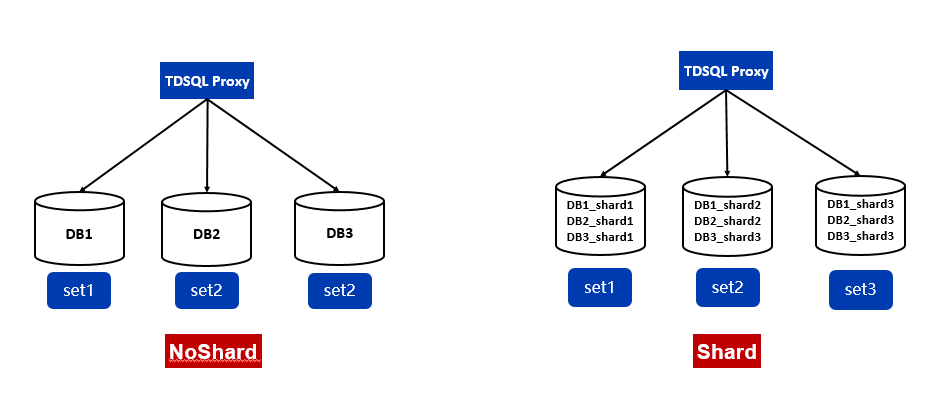
图2 TDSQL noshard与shard模式
微众银行当时在做系统架构的时候充分考虑了是采用shard版本的纯分布式数据库还是从应用层的角度来做分布式,通过大量的调研分析,最终觉得采用应用做分布式是最可控,最安全,最灵活,最可扩展的模式,从而设计了基于DCN的分布式可扩展架构,通过在应用层做水平拆分,数据库采用TDSQL noshard模式,保证了数据库架构的简洁性和业务层兼容性,这个后面会详述。
主备强一致切换与秒级恢复
TDSQL通过针对mysql内核源码的定制级优化,实现真正意义上的多副本强一致性复制,通过主备部署模式,可以实现RPO=0,即数据0丢失,这对于金融场景是至关重要也是最基础的要求;同时基于TDSQL Agent和Scheduler等模块,也实现了自动化的主备强一致切换,在30秒内可以完成整个主备切换流程,实现故障RTO的秒级恢复。
Watch节点模式
TDSQL slave节点提供了两种角色,一种是follower节点,一种是watch节点。Fllower节点与watch节点都从master节点实时同步数据,但watch节点不参与主备选举和主备切换,只作为观察者同步数据。Follower节点和watch节点的角色可以在线实时调整。
自动化监控与运维
TDSQL配套提供了赤兔管理平台系统,来支持整个TDSQL集群的可视化、自动化的监控和运维功能。如图3所示,为TDSQL赤兔管理平台的运行界面。
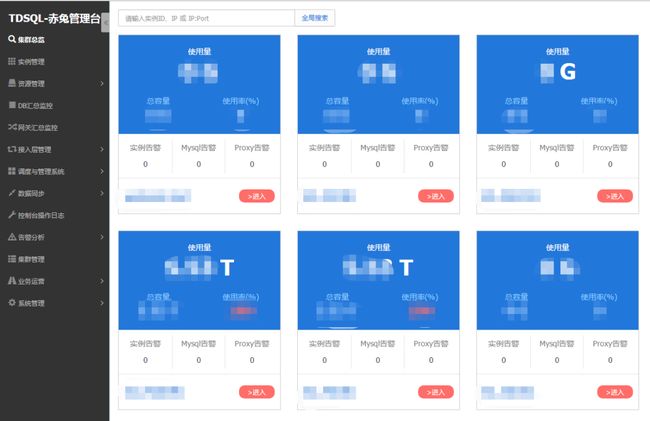
图3 TDSQL赤兔管理平台
通过TDSQL赤兔管理平台,可以实现监控数据的采集与显示,告警和策略配置,日常运维操作(主备切换,节点替换,配置更改等),数据库备份与恢复,慢查询分析,性能分析等一系列功能,极大的提升了运维效率和运维准确性。
基于以上的TDSQL的架构和特性,我们认为TDSQL很好了满足金融业务场景中对数据库的高可用、高可靠、可运维的要求,同时基于MySQL和X86的软硬件平台,也能极大的降低数据库层面的IT成本,从而极大降低户均成本,非常适用互联网时代的新一代银行架构。
基于DCN的分布式扩展架构
前文提到,微众银行为了实现业务规模的水平扩展,设计了基于DCN的分布式可扩展架构,从而即实现了扩展性,也保证了数据库层面架构以的简洁性。
DCN,即Data Center Node(数据中心节点),是一个逻辑区域概念,DCN是一个自包含单位,包括了完整的应用层,接入层和数据库库。可以通俗的理解为,一个DCN,即为一个微众银行的线上的虚拟分行,这个虚拟分行只承载微众银行某个业务的一部分客户。通过一定的路由规则(比如帐户号分段),将不同的客户划分到不同的DCN内。一旦某个DCN所承载的客户数达到规定的上限,那么这个DCN将不再增加新的客户。这时通过部署新的DCN,来实现容量的水平扩展,保证业务的持续快速发展。
不同的客户保存在不同的DCN,那么就需要有一个系统来保留全局的路由信息,记录某个客户到底在哪个DCN,这个系统就是GNS(Global Name Service),应用模块会先请求GNS,拿到对应客户的DCN信息,然后再去请求对应的DCN。GNS使用了redis缓存,以保证较高的查询QPS性能,同时采用TDSQL做持久化存储,以保证数据的安全性。
RMB(Reliable Message Bug),可靠消息总线,是DCN架构的另一个核心模块,主要负责各个业务系统之间高效、准确、快速的消息通信。DCN的整体架构如图4所示

图4 DCN架构模型
微众银行IDC架构
有了基于DCN的基础架构模型,下一步就是基础物理环境的建设。微众银行经过4年多的发展,目前已发展成为两地六中心的架构,如图5所示:
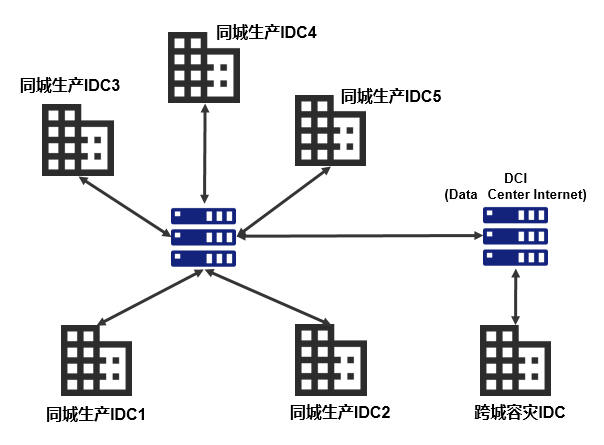 图5 微众银行IDC架构
图5 微众银行IDC架构
其中两地位于深圳和上海,深圳作为生产中心,在深圳同城有5个IDC机房,上海作为跨城异地容灾,有1个IDC机房。深圳5个同城IDC,通过多条专线两两互联,保证极高的网络质量和带宽,同时任何两个IDC之间的距离控制在10~50公里左右,以保证机房间的网络ping延迟控制在2ms左右。这一点非常重要,是实现TDSQL同城跨IDC部署的前提。
基于TDSQL的同城应用多活
基于以上的 DCN 架构和 IDC 架构,我们设计了TDSQL数据库在微众银行的部署架构。如图6所示:
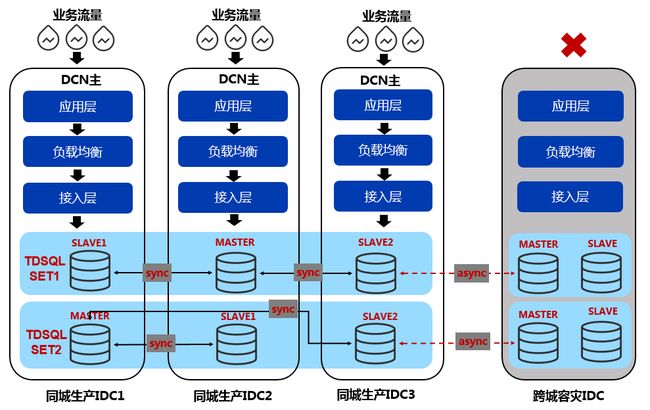 图6 微众银行基于TDSQL的同城多活架构
图6 微众银行基于TDSQL的同城多活架构
我们采用同城3副本+跨城2副本的3+2 noshard部署模式。同城3副本为1主2备,分别部署同城的3个IDC中,副本之间采用TDSQL强一致同步,保证同城3 IDC之间的RPO=0,RTO秒级恢复。跨城的2副本通过同城的一个slave进行异步复制,实现跨城的数据容灾。基于以上架构,我们在同城可以做到应用多活,即联机的业务流量,可以同时从3个IDC接入,任何一个IDC故障不可用,都可以保证数据0丢失,同时在秒级内可以恢复数据库服务。
在同一IDC内,服务器之间的ping延迟通常在0.1ms以内,而同城跨IDC之间服务器的ping延迟会大大增加,那是否会影响TDSQL主备强同步的性能呢?另外IDC之间的网络稳定性能否保证呢?我们通过以下几个措施来消除或者规避这个问题。
首先,在基础设施层面,我们会保证同城的三个IDC之间的距离控制在10~50公里左右,控制网络延迟在2ms左右;同时在IDC之间建设多条专线,保证网络传输的质量和稳定性;其次,TDSQL针对这种跨IDC强同步的场景,作了大量的内核级优化,比如采用队列异步化,以及并发复制等技术。通过基准测试表明,跨IDC强同步对联机OLTP的性能影响仅在10%左右。
从我们实际生产运营情况来看,这种同城跨IDC的部署模式,对于联机OLTP业务的性能影响,完全是可以接受的,但对于集中批量的场景,因为累积效应,可能最终会对批量的完成时效产生较大影响。如果批量APP需要跨IDC访问数据库,那么整个批量期间每次访问数据库的网络延迟都会被不断累积放大,最终会严重影响跑批效率。为了解决这个问题,我们利用了TDSQL的watch节点的机制,针对参与跑批的TDSQL SET,我们在原来一主两备的基础上,额外部署了一个与主节点同IDC的WATCH节点,同时保证批量APP与主节点部署在同一APP。如图7所示:
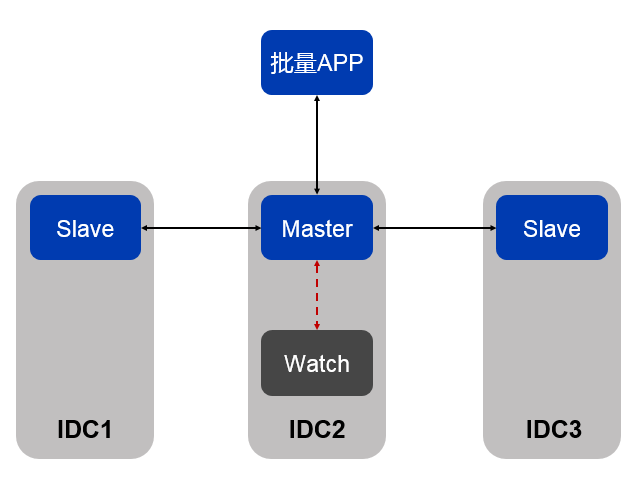
图7 TDSQL带WATCH节点的部署模式
WATCH节点与主节点同IDC部署,从主节点异步同步数据。因为是WATCH节点是异步同步,所以主节点的binlog会确保同步到跨IDC的另外两个备节点事务才算成功,这样即使主节点所在的IDC整个宕掉,仍能保证数据的完整性,不会影响IDC容灾特性。当主节点发生故障时,scheduler模块对对比watch节点和其他2个强同步备机的数据一致性,如果发现watch节点的数据跟另外2个idc数据一样新(这是常态,因为同IDC一般都比跨IDC快),则优先会将这个watch节点提升为主机。这就保证了批量APP与数据库主节节点尽量处于同一个IDC,避免了跨IDC访问带来的时延影响。
通过以上部署架构,我们实现了同城跨IDC级别的高可用,以及同城跨IDC的应用多活,极大提升了微众银行基础架构的整体可用性与可靠性。
TDSQL集群规模
微众银行成立4年多以来,业务迅速发展,目前有效客户数已过亿级,微粒贷,微业贷等也成为行业的明星产品。在业务规模迅速增长的过程中,我们的数据库规模也在不断的增长。当前微众银行的TDSQL SET个数已达350+(生产+容灾),数据库实例个数已达到1700+, 整体数据规模已达到PB级,承载了微众银行数百个核心系统。在以往的业务高峰中,最高达到日3.6亿+的金融交易量,最高的TPS也达到了10万+。如图8所示:
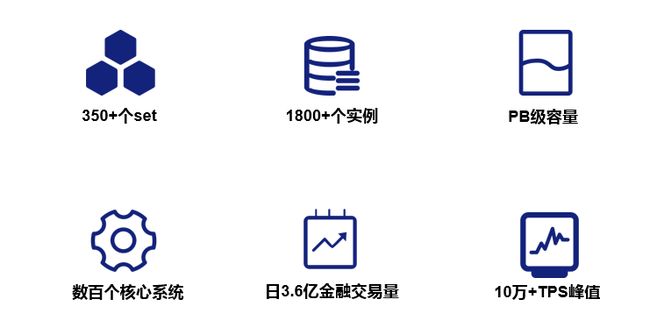 图8 微众银行TDSQL业务规模
图8 微众银行TDSQL业务规模
在过去4年多的运营中,TDSQL也从未出现过大的系统故障,或者数据安全问题,同时基于TDSQL的X86的软硬件架构,帮助微众银行极大的降低IT户均成本,极大提升了微众银行的行业竞争力。微众银行通过实践证明,TDSQL作为金融级的核心数据库,是完全胜任的。
微众银行数据库现状及未来发展
目前,TDSQL承载了微众银行99%以上线上数据库业务,同时我行也大量采用了redis作为缓存,以解决秒杀,抢购等热点场景,另外还有少量的mongodb满足文档类的存储需求。同时我行从去年开始,也尝试引入了NEWSQL数据库TiDB,解决少部分无法拆分DCN,但同时又对单库存储容量或吞吐量有超大需求的业务场景。整体来看,我行目前的数据库主要有TDSQL,TIDB以及Redis/MongoDB,TDSQL主要承载核心系统业务 ,TIDB作为补充解决单库需要超大容量或超大吞吐量的非联机业务需求,Reids和MongoDB则主要是提供缓存及文档型的存储。
当然我们并不会止步于此,微众银行数据库团队和腾讯云TDSQL团队未来会有更加深入的合作。比如我们和腾讯云TDSQL团队合作的TDSQL智能运维-扁鹊项目,目前已在微众银行灰度上线,可以实时分析TDSQL的运行状态和性能问题,是提升运维效率的利器。我们和也在和TDSQL研发团队共同调研和评估MySQL 8.0版本,以及MySQL基于MGR的高可用功能,未来可能会尝试将MySQL 8.0和MGR集成到TDSQL系统中,并尝试在银行核心系统中试用。
作者简介:
胡盼盼,微众银行数据库平台负责人。硕士毕业于华中科技大学,毕业后加入腾讯,任高级工程师,从事分布式存储与云数据库相关的研发与运营工作;2014 年加入微众银行,负责微众银行的数据库平台的设计规划和运营管理。
黄德志,微众银行数据库平台高级 DBA。2009年加入平安科技,先后担任数据库资深开发工程师及资深运维工程师。2016年加入微众银行任高级DBA,负责TDSQL相关运维工作。