kNN(k近邻法)
最近看了一些关于kNN(k近邻算法)的资料,本篇文章就当做一篇学习笔记来记录下我对kNN算法的理解。
目录
1、kNN算法的概念
2、距离度量
2.1 欧氏距离
2.2 余弦距离
2.3 曼哈顿距离
2.4 汉明距离
2.5 标准化的欧氏距离
2.6 马氏距离
3、k值的选择
4、k-d树
4.1 k-d树的建立
4.2 k-d树上的最邻近搜索
5、kNN的优缺点及改进方法
优点:
缺点:
改进方法:
参考文献:
1、kNN算法的概念
k近邻(k-Nearest Neighbor,简称kNN)算法是一种监督学习的学习算法。
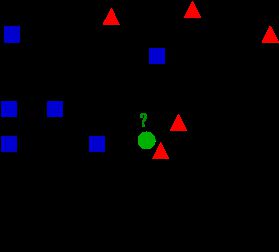
kNN的工作机制:给定测试样本,基于某种距离度量找出训练样本中与其最靠近的k个训练样本,然后基于这k个‘邻居’的信息来进行预测。因此,kNN不具有显式的学习过程。kNN实际上利用训练数据集对特征空间向量进行划分,并作为其分类的模型。模型有3个基本要素:距离度量、k值的选择以及分类决策规则。距离是衡量两个特征相似程度的一种度量方式,距离的度量方式是很多的,有欧式距离、余弦距离、曼哈顿距离等;k值的选择不同,最终的结果不同,从下图中我们可以看到当k= 3时,也就是实线的圆圈范围内,3个样本中有2个是![]() ,按照少数服从多数的原则,我们把待遇测样本分类为
,按照少数服从多数的原则,我们把待遇测样本分类为![]() ;但是当k= 5时,即虚线圆圈范围内,5个样本中有3个
;但是当k= 5时,即虚线圆圈范围内,5个样本中有3个![]() ,同样的,我们把待遇测样本分类为
,同样的,我们把待遇测样本分类为![]() 。可以看到,k值的选取不同,导致了最终的分类结果不同。因此k值的选择也是模型的关键部分;kNN的分类决策规则采用的是“投票法”,选择k个样本中出现最多的类别标记作为预测结果,即少数服从多数的思想。接下来。分别从以上三个方面对kNN算法进行展开说明。
。可以看到,k值的选取不同,导致了最终的分类结果不同。因此k值的选择也是模型的关键部分;kNN的分类决策规则采用的是“投票法”,选择k个样本中出现最多的类别标记作为预测结果,即少数服从多数的思想。接下来。分别从以上三个方面对kNN算法进行展开说明。
2、距离度量
在上面说到kNN是基于特征相似的学习算法,而在特征空间中两个实例点的距离可以反映两个实例点间的相似程度。常见的距离度量有多种,那么我们先列举下常见的距离度量。
2.1 欧氏距离
我们最常接触的距离就是欧几里得距离,也就是欧氏距离,也称为L2距离,它是度量欧几里得空间中两点间的直线距离。假设n维空间有两点![]() 和
和![]() ,那么它们的欧式距离为:
,那么它们的欧式距离为:
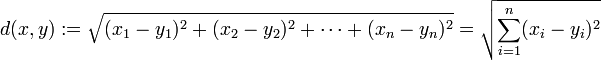
当n=2,n=3时分别对应平面上两点和三维空间中两点间的距离。
2.2 余弦距离
我在之前的博客《协方差和相关系数》中对余弦距离进行了说明,可以直接参考,这里就不再赘述。
2.3 曼哈顿距离
曼哈顿距离也称为L1距离或出租车几何,对于n为空间的两个点![]() 和
和![]() ,曼哈顿距离公式为:
,曼哈顿距离公式为:

我们以二维平面为例,引用百度百科中的图片对曼哈顿距离进行形象的说明:
红色、黄色以及蓝色折线的长度就是两个点之间的曼哈顿距离。假设左下角的点为![]() 右上角的点为
右上角的点为![]() ,那么它们之间的曼哈顿距离用公式表示为 :
,那么它们之间的曼哈顿距离用公式表示为 :
![]()
而绿色直线表示的是两点间的直线距离也就是欧式距离。
2.4 汉明距离
汉明距离实际上是源自于信息论中的一种距离度量方式,它表示两个字符串对应位置的不同字符的个数。汉明距离在编码中应用广泛,我们以二进制码为例,假设有以下两个二进制码:
101010011011
110101011010
标识颜色的为两个二进制码之间相同位置的不同字符,那么这两个二进制字符串的汉明距离为6。
2.5 标准化的欧氏距离
标准欧氏距离的思路:既然数据各维分量的分布不一样,那先将各个分量都“标准化”到均值、方差相等。这个在机器学习数据预处理中应用的较多,实际上就是对数据进行归一化。样本集的标准化过程(standardization)用公式描述就是:
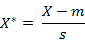
其中X为样本集,m为样本集的均值,s为标准差。
对于n维空间的两个点![]() 和
和![]() ,它们标准化后的欧氏距离为:
,它们标准化后的欧氏距离为:

其中 表示数据在第i个维度上的标准差。
表示数据在第i个维度上的标准差。
2.6 马氏距离
说到马氏距离就不得不说协方差矩阵。在说协方差矩阵之前我们先说说以下这三个概念:方差、标准差以及协方差。
方差:方差是标准差的平方,而标准差的意义是数据集中各个点到均值点距离的平均值。反应的是数据的离散程度。
协方差:标准差与方差是描述一维数据的,当存在多维数据时,我们通常需要知道每个维数的变量中间是否存在关联。协方差就是衡量多维数据集中,变量之间相关性的统计量。比如说,一个人的身高与他的体重的关系,这就需要用协方差来衡量。如果两个变量之间的协方差为正值,则这两个变量之间存在正相关,若为负值,则为负相关。
接下来,我们说所协方差矩阵,协方差是衡量两个变量之间的相关性,协方差矩阵来衡量这么多变量之间的相关性。假设 X 是以n 个随机向量(其中的每个随机向量是也是一个向量,当然是一个行向量)组成的列向量:![]()
其中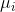 是第i个元素的期望值,即
是第i个元素的期望值,即![]() ,协方差矩阵的第i,j项被定义为如下形式:
,协方差矩阵的第i,j项被定义为如下形式:
![]()
即:
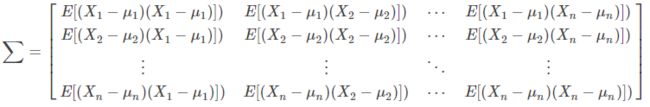
千呼万唤始出来,下面介绍马氏距离。
马氏距离表示数据的协方差距离。它是一种有效的计算两个未知样本集的相似度的方法。与欧氏距离不同的是它考虑到各种特性之间的联系(例如:一条关于身高的信息会带来一条关于体重的信息,因为两者是有关联的)并且是尺度无关的(scale-invariant),即独立于测量尺度。
对于一个均值为,协方差矩阵为的多变量向量,其马氏距离为:
如果协方差矩阵为单位矩阵,马哈拉诺比斯距离就简化为欧氏距离;如果协方差矩阵为对角阵,其也可称标准化的欧式距离。

回到之前的问题,在这些常见的距离度量中,我们应该怎么选择,实际上我们一般选择最常见的欧式距离作为特征相似性的度量,即在空间上两点离得越近,那么他们的相似程度就越高。
3、k值的选择
不同的k值会产生不同的分类结果。如果选择较小的k值,相当于用较小邻域中的训练实例进行预测,若邻近的实例恰好是噪声,那么预测就会出错,k值减小意味着整体模型变得复杂,容易发生过拟合;如果选择较大的k值,相当于用较大邻域中的训练实例进行预测,k值增大意味着模型变得简单;当k等于样本实例数N时,模型过于简单,只是对数据进行了统计,没有实际意义。
那么该如何选取k值的大小呢,下面这个图片给出了选择k值的两个建议:一是让k的值为样本点总数的平方根,比如我有50个样本点,那么我可以令k=7,当然这只是个建议,当样本点的数量较大时比如有10000个样本点时,这时候我们通常不会取k=100,实际上我们k一般取值为不大于25的整数;第二个是在二分类问题中,我们让k取奇数值,比如k= 1,k= 3,k = 5等等。当然这些都不是绝对的,实际上在真实的应用中,我们一般把k的初始值设置的较小,然后通过调参,不断的改变k的取值,直到k为某一值时的准确率最高时,我们就取该值,这个过程其实就类似于深度学习中的调参过程。

说完了k值的选取,那么选取不同的k值对我们的模型有什么影响呢。首先我们看一下,k值选取太小时会发生什么,k值太小时会导致模型复杂,发生过拟合,什么意思呢,一图胜千言,我们上图来解释。![]() 为待分类样本,
为待分类样本,![]() 和
和![]() 为已知带类标样本。
为已知带类标样本。

我们取比较极端的情况,令k = 1,很明显,这时候![]() 被分到
被分到![]() 中,实际上
中,实际上![]() 为
为![]() 的可能性并不大,那么此时,模型就更容易学到噪声,模型发生过拟合。那么什么又是过拟合呢,借用周志华老师在机器学习中的话说就是:当学习器把训练样本学的‘太好’了的时候,很可能把自身的一些特点当做所有潜在样本都具有的性质,这样导致泛化性能下降,从而产生过拟合。
的可能性并不大,那么此时,模型就更容易学到噪声,模型发生过拟合。那么什么又是过拟合呢,借用周志华老师在机器学习中的话说就是:当学习器把训练样本学的‘太好’了的时候,很可能把自身的一些特点当做所有潜在样本都具有的性质,这样导致泛化性能下降,从而产生过拟合。

其次我们再来看看,在样本集中一共有17个样本,我们把k的初始值设置为![]() ,大约是4,那么当我们去k为3,4,5,甚至k=8时,都可以把
,大约是4,那么当我们去k为3,4,5,甚至k=8时,都可以把![]() 判定为
判定为![]() ,显然这种可能性更大一些。这时候,我们就能把
,显然这种可能性更大一些。这时候,我们就能把![]() 正确的分类。
正确的分类。
最后,我们来看下当k的取值太大时将会发生什么情况,同样的,我们取比较极端的情况,令k=N,其中N为样本个数,在这幅图中的话,k=17,其中![]() 为8个,
为8个,![]() 为9个,根据少数服从多数的原则,这时候会把
为9个,根据少数服从多数的原则,这时候会把![]() 判定为
判定为![]() ,这显然是不对的。实际上,当k=N时,模型并没有进行学习,只是做了个统计而已,统计各个不同的样本在总样本中占的比例,然后把待测样本直接归为比例最高的那一类。如下图所示。一般情况下,k的取值是不大于20 的整数。
,这显然是不对的。实际上,当k=N时,模型并没有进行学习,只是做了个统计而已,统计各个不同的样本在总样本中占的比例,然后把待测样本直接归为比例最高的那一类。如下图所示。一般情况下,k的取值是不大于20 的整数。

4、k-d树
k-d树是k-dimension tree的简称,首先这里的k-d树中的k和kNN中的k的意义是不同的,k-d树中的k表示维度,即k维空间;而kNN中的k表示的是最邻近点的个数。那么什么是k-d树呢,k-d树就是对数据点在k维空间进行划分的一种数据结构,主要用于多维空间关键数据搜索(如:范围搜索和最近邻搜索)。某三维k-d树如下图所示,来自维基百科:

可以看到k-d树把三维空间分成了许多个子空间。
4.1 k-d树的建立
先通过实例来直观的介绍下k-d树,假设有6个二维数据点{(2,3),(4,7),(5,4),(7,2),(8,1),(9,6)},接下来,就需要对数据点所在的二维平面区域惊醒划分,那么这个区域是按照什么原则划分的呢,k-d树就是要确定这些分割线的,本实例是在平面空间中,所以区域分割是通过线划分,如果在多维空间就应该用超平面进行分割。接下来我们看看,k_d树是如何确定这些分割线的。
在构建以上实例k-d树之前,我们首先看看k-d树的源码:
| 算法:构建k-d树(createKDTree) |
| 输入:数据点集Data-set和其所在的空间Range |
| 输出:Kd,类型为k-d tree |
| 1.If Data-set为空,则返回空的k-d tree |
| 2.调用节点生成程序: (1)确定split域:对于所有描述子数据(特征矢量),统计它们在每个维上的数据方差。挑选出最大值,对应的维就是split域的值。数据方差大表明沿该坐标轴方向上的数据分散得比较开,在这个方向上进行数据分割有较好的分辨率; (2)确定Node-data域:数据点集Data-set按其第split域的值排序。位于正中间的那个数据点被选为Node-data。此时新的Data-set' = Data-set\Node-data(除去其中Node-data这一点)。 |
| 3.dataleft = {d属于Data-set' && d[split] ≤ Node-data[split]} Left_Range = {Range && dataleft}dataright = {d属于Data-set' && d[split] > Node-data[split]} Right_Range = {Range && dataright} |
| 4.left = 由(dataleft,Left_Range)建立的k-d tree,即递归调用createKDTree(dataleft,Left_ Range)。并设置left的parent域为Kd; right = 由(dataright,Right_Range)建立的k-d tree,即调用createKDTree(dataleft,Left_ Range)。并设置right的parent域为Kd。 |
6个二维数据点{(2,3),(4,7),(5,4),(7,2),(8,1),(9,6)},k-d树建立步骤:
(1)、首先需要确定split域。我们从上图中就可以看出,数据点在x轴方向上更加分散,也就是在x轴方向上有更大的数据方差,通过计算,我们可以得出x轴方向上的方差为:5.805;在y轴方向上的方差为:4.472。所以我们选择x轴方向作为split域值。
(2)、接下来我们需要确定Node-data域。在x轴方向上的数值为2,4,5,7,8,9,我们选择中值7对应的数据点也就是(7,2)作为Node-data。所以第一条分割线就是上图加粗黑色实线也就是x=7这条线。
(3)、确定左右子空间。分割线x=7将二维平面区域划分为了左右部分,如下图所示。左子空间有3个数据点{(2,3),(4,7),(5,4)},右子空间有2个数据点{(8,1),(9,6)}

k-d树的建立是一个递归的过程,我们再按照相同的方法分别对左右子空间区域进行分割。对于右子空间区域,很明显数据在y轴方向上的方差更大,所以split域值应该为y轴方向,因为此时只有两个数据点,所以Node-data取哪一个都可以,我们假设取(9,6)作为Node-data,那么用y=9对右区域分割如下图所示:

我们依次将空间和数据集进行细分,直到子空间只包含一个数据点,。通过不断的递归分割,最终特征空间被划分为如下形式:

根据划分,我们可以得到下面的这样的k-d树,(7,2)为根节点,(5,4)和(9,6)为左右子节点,同时也是左右子空间中的根节点。

最后k-d树的数据结构:

4.2 k-d树上的最邻近搜索
接下来我们还是以实例来直观的理解k-d数的最近邻搜索。
假设我们要查询搜索的点为(2.1,3.1),如下图中的红色四角星所示:

查询步骤:
(1)、二叉树搜索。先从根节点(7,2),随后到达叶子节点(5,4),最后到达点叶子节点(2,3)。这时候生成的搜索路径为<(7,2),(5,4),(2,3)>。我们以(2,3)为当前最邻近点,计算得出(2.1,3.1)到(2,3)的距离为0.1414。但是实际上最近邻节点不一定就是(2,3),我们还需要进行“回溯”查找。
(2)、回溯查找。所谓回溯,就是按照其搜索路径反向查找,首先回溯到其父节点(5,4),并判断在该父节点的其他子节点空间中是否有距离查询点更近的数据点。以(2.1,3.1)为圆心,0.1414为半径画一个圆形区域。如下图所示。
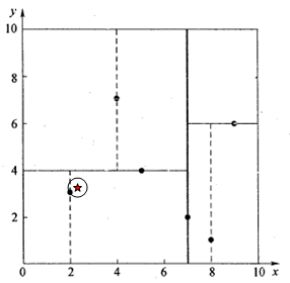
我们可以看到,圆形区域与父节点(5,4)的分割线y = 4没有交点,所以不用进入(5,4)右子空间进行搜索。继续回溯到根节点(7,2),同样的圆形区域也没有与根节点(7,2)的分割线x = 7相交,所以也不用进入(7,2)的右子空间进行搜索。回溯搜索完毕。返回最近邻点(2,3)和最近邻点和查询点的距离0.1414。
若要查询的点为其他的点,同样的步骤可以实现k-d树的最近邻搜索,这里就不再举例说明了。
如果实例点是随机分布的,kd数搜索的平均计算复杂度是O(logN),这里N是训练实例数。kd数更适用于训练实例数远大于空间维数时的k近邻搜索。
5、kNN的优缺点及改进方法
优点:
①算法简单直观,易于实现;
②不需要产生额外的数据来描述规则,它的规则就是训练数据(样本)本身, 并不是要求数据的一致性问题,即可以存在噪音;
③KNN方法虽然从原理上也依赖于极限定理,但在类别决策时,只与极少量的 相邻样本有关。因此,采用这种方法可以较好地避免样本数量的不平衡问题
④从分类过程来看,KNN方法最直接地利用了样本之间的关系,减少了类别特 征选择不当对分类结果造成的不利影响,可以最大程度地减少分类过程中的误差 项。对于一些类别特征不明显的类别而言,KNN法更能体现出其分类规则独立性 的优势,使得分类自学习的实现成为可能。
缺点:
①分类速度慢 最近邻分类器是基于实例学习的懒惰学习方法,因为它是根据所给训练样本 构造的分类器,是将所有训练样本首先存储起来,当要进行分类时,就临时进行 计算处理。需要计算待分样本与训练样本库中每一个样本的相似度,才能求得与 其最近的K个样本。对于高维样本或样本集规模较大的情况,其时间和空间复杂 度较高,时间代价为O (mn),其中m为向量空间模型空间特征维数,n为训练样本集大小。
②样本库容量依赖性较强 对KNN算法在实际应用中的限制较大:有不少类别无法提供足够的训练样本, 使得KNN算法所需要的相对均匀的特征空间条件无法得到满足,使得识别的误差 较大。
③特征作用相同 与决策树归纳方法和神经网络方法相比,传统最近邻分类器认为每个属性的 作用都是相同的(赋予相同权重)。样本的距离是根据样本的所有特征(属性)计 算的。在这些特征中,有些特征与分类是强相关的,有些特征与分类是弱相关的, 还有一些特征(可能是大部分)与分类不相关。这样,如果在计算相似度的时候, 按所有特征作用相同来计算样本相似度就会误导分类过程。
④K值的确定 KNN算法必须指定K值,K值选择不当则分类精度不能保证。
改进方法:
对于改进我们只需要针对算法的缺点进行改进即可。
对于KNN分类算法的改进方法主要可以分为加快分类速度、对训练样本库的 维护、相似度的距离公式优化和K值确定四种类型。
①加快KNN算法的分类速度 就学习而言,懒惰学习方法比积极学习方法要快,就计算量而言,它要比积 极学习方法慢许多。因为懒惰学习方法在进行分类时,需要进行大量的计算。针 对这一问题,到目前为止绝大多数解决方法都是基于减少样本量和加快搜索K个 最近邻速度两个方面考虑的:
1)浓缩训练样本 当训练样本集中样本数量较大时,为了减小计算开销,可以对训练样本集进 行编辑处理,即从原始训练样本集中选择最优的参考子集进行K最近邻寻找,从 而减少训练样本的存储量和提高计算效率。这类方法主要包括Condensing算法 、WilSon的Editing算法 和Devijver的MultiEdit算法 , Kuncheva使用遗传算法在这方面也进行了一些研究 。
2)加快K个最近邻的搜索速度 这类方法是通过快速搜索算法,在较短时间内找到待分类样本的K个最近邻。 在具体进行搜索时,不要使用盲目的搜索方法,而是要采用一定的方法加快搜索 速度或减小搜索范围,例如可以构造交叉索引表,利用匹配成功与否的历史来修 改样本库的结构,使用样本和概念来构造层次或网络来组织训练样本。
②相似度的距离公式的优化 为了改变传统KNN算法中特征作用相同的缺陷,可在相似度的距离公式中给 特征赋予不同权重,例如在欧氏距离公式中给不同特征赋予不同权重。特征的权重一般根据各个特征在分类中的作用设定,可根据特征在整个训练 样本库中的所起的作用大小来确定权重,也可根据在训练样本的局部样本 (靠近待测试样本的样本集合)中的分类作用确定权重。
③对训练样本库的维护 对训练样本库进行维护以满足KNN算法的需要,包括对训练样本库中的样本 进行添加或删除。对样本库的维护并不是简单的增加删除样本,而是可采用适当 的办法来保证空间的大小,如符合某种条件的样本可以加入数据库中,同时可以 对数据库库中已有符合某种条件的样本进行删除。从而保证训练样本库中的样本 提供KNN算法所需要的相对均匀的特征空间。
④K值选择 K值的选择原则一般为:
1)K的选择往往通过大量独立的测试数据、多个模型来验证最佳的选择;
2)K值一般事先确定,也可以使用动态的,例如采用固定的距离指标,只对 小于该指标的样本进行分析。
参考文献:
1、从K近邻算法、距离度量谈到KD树、SIFT+BBF算法 https://blog.csdn.net/v_july_v/article/details/8203674
2、一文搞懂k近邻(k-NN)算法(一) https://zhuanlan.zhihu.com/p/25994179
3、KNN Algorithm - How KNN Algorithm Works With Example | Data Science For Beginners | Simplilearn
https://www.youtube.com/watch?v=4HKqjENq9OU
4、欧氏距离与马氏距离 https://blog.csdn.net/u010167269/article/details/51627338
5、《机器学习 》 周志华著
6、一只兔子帮你理解kNN https://www.joinquant.com/post/2227?f=zh&%3Bm=23028465
7、《机器学习实战》