《Attention is all you need》源码解析+算法详解
Attention is all you need 源码解析
最近学习Transformer模型的时候,并且好好读了一下Google的《Attention is all you need》论文。论文地址如下: Attention is All you need. 同时学习了一下其github的代码,代码地址如下:github code. 在网上查资料的过程中,还找到了一个好像也用的比较多的版本:Transformer demo.
在网上学习的过程中,我发现有一些csdn blog的源码解析内容主要是根据后一个的内容来进行的。在对比两个github code 的过程中,我感觉前一个的内容质量可能更好,代码也更完整一些而且不断有人在做更新,所以本次解析也主要以第一个github code 的版本来进行,同时也是希望在刚调通完代码后可以自己记录一些在学习代码过程中遇到的一些理解方面的问题,进行记录,也方便后续的回顾。
模型中某些理论方面的内容,可以参考我之前写的Transformer模型中Encoder和Decoder各结构的理解
prepro.py
该模块用于一开始的加载原始数据 -> 对数据进行处理 -> 对句子进行切分。
_prepro利用lambda的形式设计函数,第一个_prepro用于去除train.tags.de-en.de和train.tags.de-en.en文件中以<开始的sentence. 第二个_prepro利用了Python的re正则表达式模块,<[^>]+>,其中[^>]+表示包含除了右括号以外的其他字符。表示的意思是:选择以左括号开始,右括号结束的部分。
之后即是利用_write()将对应进行处理后的数据集写入到*iwslt2016/prepro/*目录下。
这里在讲一下sentencepiece模块。sentencepiece是一个Google开源的自然语言处理包,可以对分词结果进行训练的一个模块。我们知道,在不同的领域或不同的句子下,我们希望某些词的分词效果有所不同(包括该领域的特殊词汇). 例如,“抗精神病治疗”,我们希望在分词切分的时候可以以整体的形式出现,而不是被切分成“抗”,“精神病”,“治疗”。在现有的某些分词工具下,例如jieba分词,对于以上情况我们可以添加自定义词典的形式来加入一直词。但有个问题就是我们无法一开始获知所有的组合,即某些词汇组合我们可能是未知的,所以我们就希望机器能够自动学习经常出现的短语或词,Sentencepiece就是来解决这个问题的。我们可以用该领域内的大量文本进行训练,该模块可以根据样本训练的结果自动生成词表和分词模型。然后我们可以根据模型来对文本进行分词的工作。
有兴趣大家可以自己拿一个小文本作为一个小demo来尝试一些训练、加载模型和分词的过程。
更详细的内容可以参考以下链接内容:
自然语言处理之_SentencePiece分词
Unsupervised text tokenizer for Neural Network-based text generation.
SentencePiece Python Wrapper
loaddata.py
该模块用于构建数据集、对数据集根据词表进行转换等功能。
load_vocab()
函数即根据已构建的词表来构建idx2token和token2idx两个映射字典。
load_data()
函数即对输入文件(source file)和目标文件(target file)的sentence进行处理,只保留每行sentence的长度小于等于maxlen的句子。并以列表的形式进行保存每个满足条件的sentence.
encode()
函数即根据idx2token和token2idx映射表,将每个单词转换成对应的idx表示。同时,这里对encode部分输入的sentence末尾加入了结束符,在decode部分的sentence开头加入表示解码结束。
generate_fn()
函数即以Python生成器的形式,生成training / evaluation data. yield (x, x_seqlen, sent1), (decoder_input, y, y_seqlen, sent2)包含编码器和解码器的数据两部分。第一部分包含三个元素:x代表由Idx表示的sentence,维度大小为(N,T1),N表示batch_size, T1表示句子的长度。x_seqlen表示句子的长度,维度为(N,),sent1表示原始由token表示的sentence,维度为(N,)。第二部分包含四个元素,其内容与编码器中的部分类似,只是decoder_inputs表示不包括结束符,y表示不包括开始符
input_fn()
函数中利用tf.data.Dataset.from_generator()函数来返回一个数据的生成器对象。自Tensorflow 1.x以来,逐步开发引入了tf.data.Dataset模块,使其数据读入的操作变得更为方便。tf.data.Data模块读入数据也有两种方式,一种是tf.data.Data.from_tensor_slices()另一种是tf.data.Data.from_generate().两种方法都是对x,y两部分数据沿第一个维度进行切分然后进行组合成tuple。
from_tensor_slices()是直接利用已存在的两组数据进行切分组合,每次分别从inputs和labels各取batch_size个大小的数据进行组合。在不加repeat()的情况下为不重复抽取,即只能迭代原数据集中batch大小 / batch_size大小的次数。如果想迭代任意次数,则需要加入.repeat()方法
from_generator()是按生成器对象,按batch_size大小逐batch读入数据。对每次生成的inputs,labels进行组合成一个tuple
from_tensor_slices()是当数据集已经生成好的时候比较适用,当数据集是需要动态生成过程中时,则可以使用from_generator()函数,每次动态的从生成器中生成指定大小的数据集.
详细内容可以参考:
使用TensorFlow Dataset读取数据
get_batch()
函数即获取training / evaluation mini-batch。利用input_fn()函数返回数据集生成器对象batches,并根据样本总数和batch_size的大小计算出所需要的batch数目num_batches,以及样本总数len(sents1)。
modules.py
该模块用于构建Transformer模型中的各部分的模型结构,即论文中的 3 Model Architecture部分,根据论文中模型的结构和参数来构建相应的模型结构。这一部分的代码即实现Transformer中的模型结构,所以会重点讲解这部分的代码内容。
layer_normalizaiton()
函数即是实现模型中的Layer Normalizaiton. 由layer normalizaiton的原理可知,我们需要计算的是在某一层上的mean和variance,比如在mulit-head attention之后的LN, LN函数的输入Inputs的维度为(N, T_q, d_model),则此时需要在d_model的维度上求mean和variance。所以这里mean, variance = tf.nn.moments(inputs, [-1], keep_dims=True)中 axis=-1。接下来的beta、gamma两个参数则是normalization的线性调整参数,可以让分布的曲线压缩或延长一点,左移或右移一点的进行调整:outputs = gamma * normalized + beta。最后返回经过标准化后的数据。
get_token_embeddings()
函数是初始化word embedding的部分。这里对embedding的数值利用了xavier_initializer()进行初始化。同时要注意一个zero_pad的参数,该参数是为了使queries / keys的mask更加方便。
scaled_dot_product_attention()
函数即模型的single self-attention结构。按照
的公式进行计算。其中causality参数即表示是否applies masking for future blinding. 该算法的每一步即是按照论文中的scaled Dot-Product Attention进行的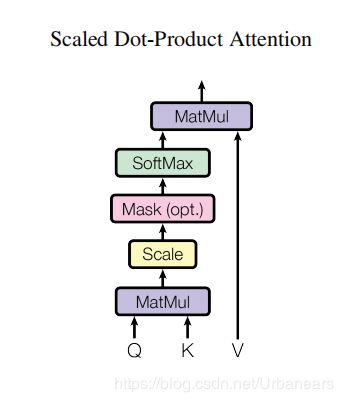
mask()
这里要重点分析一下mask的函数内容。函数中设置了三个判断条件,分别是要在keys有padding、queries有padding和是否mask for future blinding。这里对Keys和queries分情况讨论的原因是,因为在不是self-attention中,query和key的第二维可能会有不同(两者的句子长度可能会不同),即可能一个有pad一个没有pad,所以要分情况讨论。对于keys和queries两种情况,以keys的情况举例来说明:
这里tf.reduce_sum(tf.abs(keys))的目的是为了在keys的tensor中,查找出那些padding项。padding项由于一开始做pad时,其embedding设置为全0,所以对其embedding(d-model)维度进行求和,若是padding项,则其和只会为0.然后再又tf.sign进行二分,即最终结果只会出现0,1两项。padding项其求和恒为0,非padding项其求和>0则为1.
此时,mask的维度由(N,T_k,d)降为(N,T_k).其中,T_k的维度中的0,1代表了哪些位置是padding哪些位置是word。由于我们后续在利用inputs对paddings进行替换的时候,tf.where(input,a,b)要求tensor a,b要有一样的尺寸,所以需要对maks的维度进行扩充。
这里对于为什么扩充重复的维度为tf.shape(queries)[1]可以这样理解为:
首先,inputs的维度为(N,T_q, T_k),代表的即是query对每个key下的attention score的分数矩阵。T_q代表每一个query,T_k代表每一个key。由以上mask的分析可知,mask得出的即是在T_k下有哪些是padding,哪些是word,那我们就要对T_k下为0所代表的列下的attention score进行替换。此时,通过tf.expand_dims(masks,1),mask的维度变为了(N,1,T_k), 相当于是只有在inputs分数矩阵中的第一行标明了哪些是word哪些是padding。(可以理解为mask维度中第二维代表的是在inputs矩阵中的行表示query,T_k代表的列表示key)由于要对inputs中的每一行中,key为Padding的位置都进行替换,所以第二维度要扩展query的个数(行数)。
接下来就是padding设置为和inputs一样的大小(因为要利用Inputs对padding进行替换)。其值设置为非常小,目的是为了减少padding位置的attention score值对后续value进行的影响。tf.equal()来判断mask中哪些位置为0,为0的变为1.(这里为1代表了padding的位置)。tf.where()表示以paddings为基准,对与mask中为False的位置(映射到paddings位置上),将inputs的对应位置的元素替换padding中对应位置的元素,得到的结果即为,保留了原始paddings中的极小值部分(这部分即为padding项),其他位置替换为inputs中的元素。
最后生成的维度和inputs一样为(N,T_q,T_k)的attention score矩阵。
masks = tf.sign(tf.reduce_sum(tf.abs(keys), axis = -1)) #(N, T_k)
masks = tf.expand_dims(masks, 1) #(N, 1, T_k)
masks = tf.tile(masks, [1, tf.shape(queries)[1], 1]) #(N, T_q, T_k)
#Apply masks to inputs
paddings = tf.ones_like(inputs) * padding_num
outputs = tf.where(tf.equal(masks, 0), paddings, inputs) #(N, T_Q, T_k)
queries的部分和keys的相同。接下来再分析一下mask for future blinding时的情况:
这里是对decoder中的Mask Multi-head attention. type表示是否要屏蔽未来的信息。
由于在解码器的部分,不像编码器一样可以直接并行运行,解码器由于需要翻译,仍然是序列化的进行。所以在decoder的Attention部分(这里其实也是self-Attention),某一时刻翻译出来的词只能跟它之前翻译出的词产生联系。即只能跟它之前的词计算Attention score.所以这里就用了一个下三角矩阵。
这样在计算Attention时,前面的word不会与在它后面的word产生联系。比如第一个word在计算Matmul(V)时,就只与它自己相关。(即不会有跟它后面的词的attention score)
diag_vals = tf.ones_like(inputs[0, :, :]) #(T_q, T_k)
tril = tf.linalg.LinearOperatorLowerTriangular(diag_vals).to_dense() #(T_q, T_k).生成一个下三角矩阵
masks = tf.tile(tf.expand_dims(tril, 0), [tf.shape(inputs)[0],1,1]) #(N, T_q, T_k)
paddings = tf.ones_like(masks) * padding_num
outputs = tf.where(tf.equal(masks, 0), paddings, inputs)
multihead_attention()
函数即是多头注意力机制的函数实现。
#Linear projections
Q = tf.layers.dense(queries, d_model, use_bias = False) #(N, T_q, d_model)
K = tf.layers.dense(keys, d_model, use_bias = False) #(N, T_k, d_model)
V = tf.layers.dense(values, d_model, use_bias = False) #(N, T_k, d_model)
即先经过一个线性映射将queries、keys、values从d_k,d_v的维度映射到d_model的维度,接下来这里的多头注意力机制并不是分开的8个tensor,而是对原始的Q、K、V矩阵进行切分在进行拼接而成的。具体的过程如下:
首先对于d_model = 512,由于采用了num_heads = 8,则正如论文中所说的,在每一个head下,d_k = d_v = d_model / 8 = 64。所以一开始tf.split()函数的axis = 2,即沿d_model维度进行切分,切分成8片。然后对每片,沿第一个维度batch_size的维度进行拼接,即形成了维度为(h*N, T_q, d_model/h)的维度(针对矩阵Q而言)。该维度可以明显的看出,生成了h个大小为(N,,T_q,d_model/h)的矩阵Q_。对于矩阵K,V的分析则类似。
#这里axis所在维度的长度 / num_heads 应该能被整除。
Q_ = tf.concat(tf.split(Q, num_heads, axis = 2), axis = 0) #(h*N, T_q, d_model/h)
K_ = tf.concat(tf.split(K, num_heads, axis = 2), axis = 0) #(h*N, T_k, d_model/h)
V_ = tf.concat(tf.split(V, num_heads, axis = 2), axis = 0) #(h*N, T_k, d_model/h)
在对这h个Q_、K_、V_矩阵做scaled_dot_product_attention之后,再进行Reshape的操作,即做跟以上切分相反的操作:先按axis = 0第一个维度做切分,相当于生成h个维度大小为(N,T_q,d_model/h)的矩阵,然后再对这h个矩阵按axis = 2即按(d_model/h)的维度进行拼接,从而重新生成大小为(N,T_q,d_model)的矩阵。
outputs = tf.concat(tf.split(outputs, num_heads, axis = 0), axis = 2) #(N, T_q, d_model)
feed_forward()
函数即是实现全连接的前向神经网络的部分。代码中利用了tf.layers.dense()函数来实现全连接的网络,第一个代表的从输入层到第一隐层的过程,所以num_hiddens设置为num_units[0](论文中d_ff = 2048),第二个则是由第一隐层到输出层,所以num_hiddens设置为num_units[1](论文中为d_model = 512)。
Inner layer
outputs = tf.layers.dense(inputs, num_units[0], activation = tf.nn.relu)
#Outer layer
outputs = tf.layers.dense(outputs, num_units[1])
label_smoothing()
这部分就相当于是使矩阵中的数进行平滑处理。把0改成一个很小的数,把1改成一个比较接近于1的数。论文中说这虽然会使模型的学习更加不确定性,但是提高了准确率和BLEU score。(论文中的5.4部分)
position_embedding()
#Second part, apply the cosine to even columns and sin to odds
#list[start : end : step]
position_enc[:, 0::2] = np.sin(position_enc[:,0::2]) #dim 2i.取下标为偶数的
position_enc[:, 1::2] = np.cos(position_enc[:,1::2]) #dim 2i+1.取下标为奇数的
position_enc = tf.convert_to_tensor(position_enc, tf.float32) #(maxlen, E)
这里即按照论文中的,对于下标为偶数的则采用sin,对下标为奇数的则采用cos的方式。position_enc[:,0::2]中的0::2代表的意义即是从第一个元素开始(0)每隔2个位置进行遍历,即取了下标为偶数的位置。
#从position_enc 中 取position_ind对应索引位置的元素
outputs = tf.nn.embedding_lookup(position_enc, position_ind)
model.py
该部分模块即利用上文已经构建的各组件,来构建整体的Transformer模型结构。
这里代码中也标明了xs,ys所代表的意义。也是看上文中load_data.py文件中的generate_fn()函数的数据生成器部分。
__init__
首先__init__函数为Transformer包含了一个hyperparams的超参数对象,来生成token2idx和idx2token的映射,以及word embedding 矩阵。
encode()
encode()函数即Transformer模型的编码器部分,按照论文中的模型结构来进行搭建。首先是word embedding + position embedding来形成输入数据。接下来是一个循环num_blocks次的Multi-Head Attention部分。利用modules.py模块中的multihead_attention()函数来进行搭建,其中causality参数=False代表只是mask和不是mask for future blinding。multi-head attention之后再接一个Feed Forward的前向网络,由这两个sub_layers构成一个block。
decode()
decode()函数即Transformer模型的解码器部分,按照论文中的模型结构来进行搭建。首先仍然是一个embedding来构建输入数据的部分,接下来是一个循环num_blocks次的部分。blocks中的第一个是一个Mask Multi-Head Attention,所以需要在multihead_attention()函数中将causality设置为True。又因为该Attention是self-Attention,所以输入的queries、keys、values都是dec本身。
接下来仍然是一个Multi-Head Attention,这里的keys、values由encoder的输出提供,所以输入的参数与上面的不同。这里causality参数设置为False。然后是一个同样的Feed Forward的前向网络
最后是一个decoder解码器的输出部分。这里linear projection的权重矩阵由embedding矩阵的转置得到,因为最终输出要生成的是一个vocab_size大小的向量,表示输出的各个单词的概率。这里Multi-Head Attention的输出与权重矩阵的乘法,没有使用tf.matmul()的矩阵乘法,因为这里两个矩阵的维度大小不相同。Multi-Head Attention的输出维度大小为(N,T2,d_model),而weights的维度大小为(d_model,vocab_size)。所以这里用了tf.einsum()函数,这里该函数的第一个参数:'ntd,dk->ntk’表示的意思是,->代表乘法操作,ntd,dk->ntk表示两个矩阵相乘后结果的维度为ntk。这样就实现了两个维度不同矩阵的乘法。
liner projuction的输出logits的维度大小为(N,T2,vocab_size)。即代表了在当前T2的长度下,每个位置上的输出各个单词的概率。然后利用tf.argmax() 在axis = -1的维度下,求出概率最大的那个位置的词作为该位置上的输出单词。所以y_hat的维度大小为(N,T2)。
train()
该函数即是进行模型训练的部分。首先是调用encode()和decode()函数来获取各部分的输出结果。接下来就是模型训练的scheme.
利用one_hot表示每个词的索引在整个词表中的位置,相当于构建出了要训练的目标Label,这里就是要使logits的最终结果,即vocab_size大小的向量中,目标词汇所在位置(索引)的值尽可能的大,而使其他位置的值尽可能的小。构造出了输出和标签之后,就使用tf.nn.softmax_cross_entropy_with_logits()进行训练。
y_ = label_smoothing(tf.one_hot(y, depth = self.hp.vocab_size)) #(N, T2, vocab_size)
ce = tf.nn.softmax_cross_entropy_with_logits(logits = logits, labels = y_) #(N,T2)
在计算Loss之前,还要进行一定的处理。由于一开始对有些句子长度不够maxlen的进行了padding,所以在计算Loss的时候,将这些位置上的误差清0
nonpadding = tf.to_float(tf.not_equal(y, self.token2idx[''])) #0:
loss = tf.reduce_sum(ce * nonpadding) / (tf.reduce_sum(nonpadding) + 1e-7) #最终求得一个loss scalar进行优化.
最后即是利用了AdadeltaOptimizer优化器对loss进行优化。tf.summary.scalar()函数即是以key-value的形式保存数值,用于TensorBoard中对数据的可视化展示。
eval()
该函数是对模型训练效果进行评估的模块。这里即是让解码器根据开始符
decoder_inputs = tf.ones((tf.shape(xs[0])[0],1), tf.int32) * self.token2idx['']
ys = (decoder_inputs, y, y_seqlen, sents2)
这里xs[0]表示取第一个tensor x。tf.shape(xs[0]) = [N,T], tf.shape([xs[0])[0] 即取batch_size大小,在evaluation部分,由于解码器的预测仍然是按序列式的进行(与train时候的不同),即是每一次解码过程预测一个目标词汇,所以在时刻t=0时解码器的输入维度应该是(N,1),即此时为一个batch输入,每个batch的开头为
for _ in tqdm(range(self.hp.maxlen2)):
logits, y_hat, y, sents2 = self.decode(ys, memory, False)
if tf.reduce_sum(y_hat, 1) == self.token2idx['']:break
_decoder_inputs = tf.concat((decoder_inputs, y_hat), 1)
ys = (_decoder_inputs, y, y_seqlen, sents2)
这里这一过程,即是不断的进行序列化的预测过程。循环次数为maxlen2次,表示是要翻译完一整个句子的长度,然后不断的将上一时刻的解码器的输出添加到下一时刻解码器的输入。
#monitor a random sample
n = tf.random_uniform((), 0, tf.shape(y_hat)[0]-1, tf.int32) #即从0,batch_size-1之间选择一个batch sample进行观察
sent1 = sents1[n] #input sentence
pred = convert_idx_to_token_tensor(y_hat[n], self.idx2token) #prediction sentence
sent2 = sents2[n] #output sentence
这里即是随机抽取一个batch来查看模型的结果。n代表从0,batch_size-1之间选择一个batch sample进行观察。sent1[n]表示原始的输入句子,pred即代表了decoder的预测翻译的输出句子,sents2[n]即表示正确的翻译输出句子。
train.py
该模块即是设计对模型进行训练的主方法。首先,即是调用get_batch()函数来生成训练和评估时候的数据。
#create a iterator of the correct shape and type
#A reinitializable iterator is defined by its structure.We could use the 'output_types' and 'output_shapes' properties of train_batches.
iter = tf.data.Iterator.from_structure(train_batches.output_types, train_batches.output_shapes)
xs, ys = iter.get_next()
#即利用已有的dataset对象,来初始化一个新的数据集生成器
train_init_op = iter.make_initializer(train_batches)
eval_init_op = iter.make_initializer(eval_batches)
这里iter利用了from_structure()方法来实现,该函数的参数即是生成数据的类型和大小,这里根据了train_batches的类型和大小。然后分别利用train_batches和eval_batches来初始化训练和评估的数据集生成器。
m = Transformer(hp)
loss, train_op, global_step, train_summaries = m.train(xs,ys)
y_hat, eval_summaries = m.eval(xs,ys)
这里即是加载模型,然后调用模型里的train()和eval()方法来进行训练和做评估。
接下来就是构建Tensorflow的Session来对整个模型进行训练和评估的过程:
ckpt = tf.train.latest_checkpoint(hp.logdir)用来查找到最近的检查点文件。
save_variable_specs(os.path.join(hp.logdir, "specs"))则是用来保存训练过程中的一些参数变量。
summary_writer = tf.summary.FileWriter(hp.logdir, sess.graph)即是要利用TensorBoard来进行数据可视化展示。
sess.run(train_init_op)来运行一次数据集生成器,即生成一次数据集。
total_steps = hp.num_epochs * num_train_batches这里即循环epochs次,每epoch次要对num_train_batches个batch进行训练,也就是每次epoch都要对所有的batch进行一次训练,以此来计算总的计算次数。
_, _gs, _summary = sess.run([train_op, global_step, train_summaries])这一步即是当一个epoch没有计算完时(即所有的batch还没有计算完时),不断的迭代去训练train_op。每运行一次该行代码,都会调用一次xs, ys = iter.get_next()来生成一个batch数据集。
if _gs and _gs % num_train_batches == 0:这里即是每次epoch全部训练完所有batch,则打印相应的信息,并对模型效果进行测试。
if语句以下的内容包括在评估中将预测输出由idx转化为对应的token,然后将结果写入到本地,计算bleu的得分,保存模型的检查点文件。
总结
比较重要的几个模块文件差不多就是上面的这几个模块。学习Transformer源代码的过程中,也让我对Tensorflow构建模型的过有了新的认识。如果有写的不对的地方还希望大家指正,希望能够与大家一起交流学习。