关于JavaScript 如何工作的,由以下这几个概念
- JS Engline (JS引擎)
- Runtime(运行上下文)
- Call Stack (调用栈)
- Event Loop(事件循环)
- Callback (回调)
1. JS Engine
目前最流行的JS引擎非V8莫属了,Chrome浏览器和Node.js采用的引擎就是V8引擎。
目前最流行的JS引擎非V8莫属了,Chrome浏览器和Node.js采用的引擎就是V8引擎。引擎的结构可以简单由下图表示:
[图片上传失败...(image-e2ed5b-1577415600424)]
就如JVM虚拟机一样,JS引擎中也有堆(Memory Heap)和栈(Call Stack)的概念。
- 栈。用来存储方法调用的地方,以及基础数据类型(如var a = 1)也是存储在栈里面的,会随着方法调用结束而自动销毁掉(入栈-->方法调用后-->出栈)。
- 堆。JS引擎中给对象分配的内存空间是放在堆中的。如var foo = {name: 'foo'} 那么这个foo所指向的对象是存储在堆中的。
此外,JS中存在闭包的概念,对于基本类型变量如果存在与闭包当中,那么也将存储在堆中。
function foo () {
var x; // local variables
var y; // captured variable, bar中引用了y
function bar () {
// bar 中的context会capture变量y
use(y);
}
return bar;
}
如上述情况,变量y存在与bar()的闭包中,因此y是captured variable,是存储在堆中的。
2. RunTime
JS在浏览器中可以调用浏览器提供的API,如window对象,DOM相关API等。这些接口并不是由V8引擎提供的,是存在与浏览器当中的。因此简单来说,对于这些相关的外部接口,可以在运行时供JS调用,以及JS的事件循环(Event Loop)和事件队列(Callback Queue),把这些称为RunTime。有些地方也把JS所用到的core lib核心库也看作RunTime的一部分。
[图片上传失败...(image-d4fd49-1577415600424)]
同样,在Node.js中,可以把Node的各种库提供的API称为RunTime。所以可以这么理解,Chrome和Node.js都采用相同的V8引擎,但拥有不同的运行环境
3. Call Stack
JS被设计为单线程运行的,这是因为JS主要用来实现很多交互相关的操作,如DOM相关操作,如果是多线程会造成复杂的同步问题。因此JS自诞生以来就是单线程的,而且主线程都是用来进行界面相关的渲染操作
为什么说是主线程,因为HTML5 提供了Web Worker,独立的一个后台JS,用来处理一些耗时数据操作。因为不会修改相关DOM及页面元素,因此不影响页面性能
如果有阻塞产生会导致浏览器卡死。
如果一个递归调用没有终止条件,是一个死循环的话,会导致调用栈内存不够而溢出,如:
function foo() {
foo();
}
foo();
例子中foo函数循环调用其本身,且没有终止条件,浏览器控制台输出调用栈达到最大调用次数。
[图片上传失败...(image-9c7535-1577415600424)]
JS线程如果遇到比较耗时操作,如读取文件,AJAX请求操作怎么办?这里JS用到了Callback回调函数来处理。
对于Call Stack中的每个方法调用,都会形成它自己的一个执行上下文Execution Context
4.Event Loop & Callback
JS通过回调的方式,异步处理耗时的任务。一个简单的例子:
var result = ajax('...');
console.log(result);
此时并不会得到result的值,result是undefined。这是因为ajax的调用是异步的,当前线程并不会等到ajax请求到结果后才执行console.log语句。而是调用ajax后请求的操作交给回调函数,自己是立刻返回。正确的写法应该是:
ajax('...', function(result) {
console.log(result);
})
此时才能正确输出请求返回的结果。
JS引擎其实并不提供异步的支持,异步支持主要依赖于运行环境(浏览器或Node.js)。
所以什么是Event Loop?
Event Loop只做一件事情,负责监听Call Stack和Callback Queue。当Call Stack里面的调用栈运行完变成空了,Event Loop就把Callback Queue里面的第一条事件(其实就是回调函数)放到调用栈中并执行它,后续不断循环执行这个操作。
console.log('Hi');
setTimeout(function cb1() {
console.log('cb1');
}, 5000);
console.log('Bye');
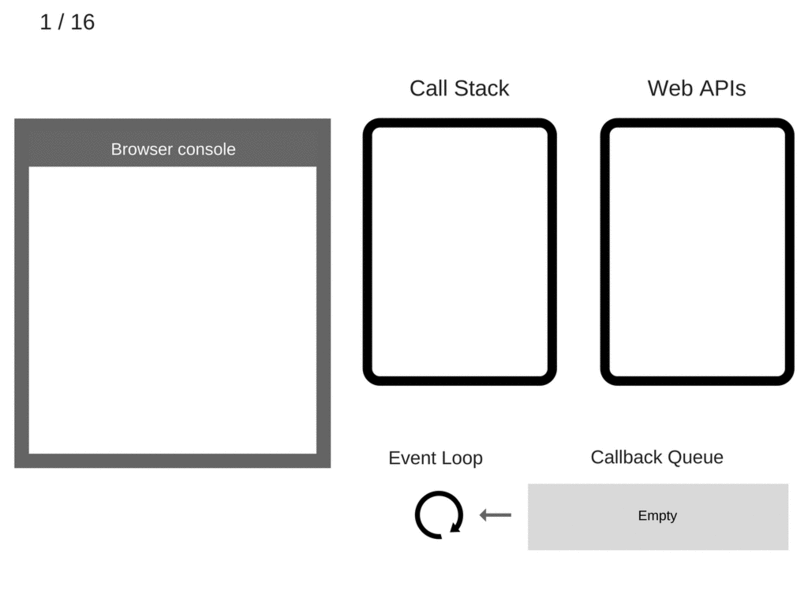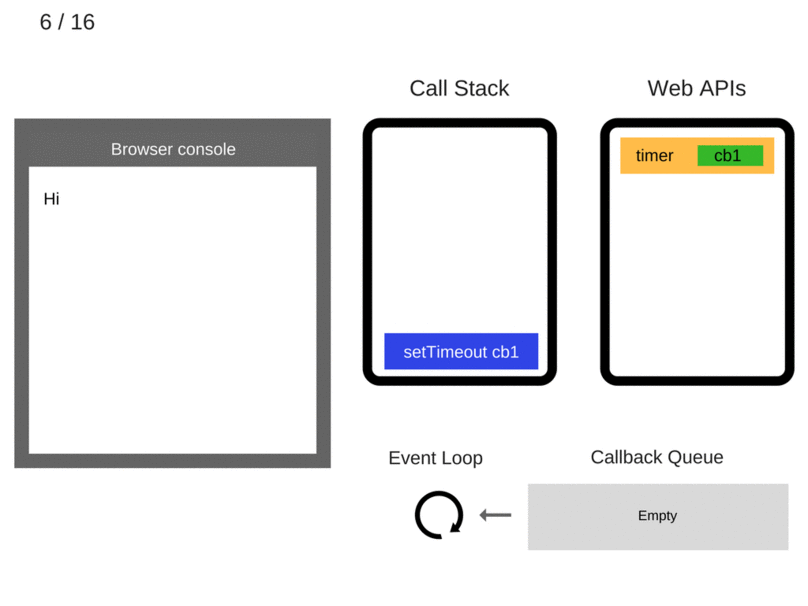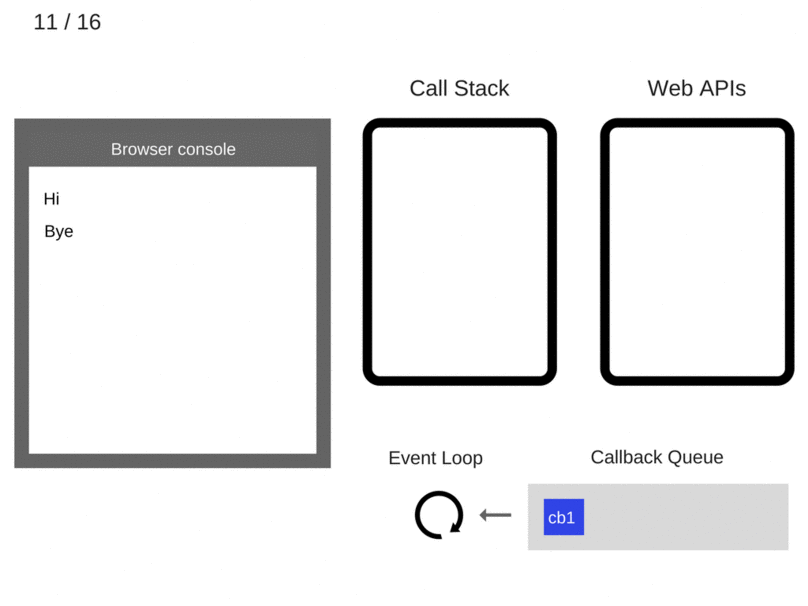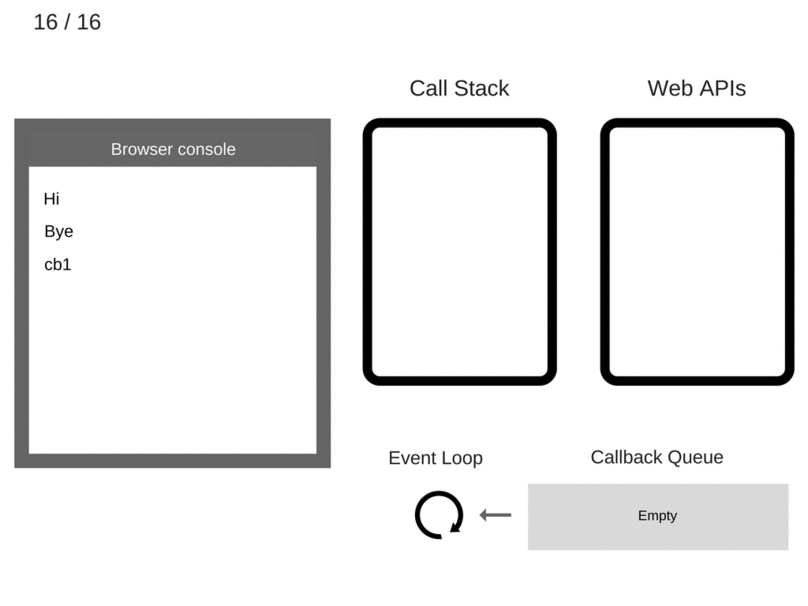
setTimeout有个要注意的地方,如上述例子延迟5s执行,不是严格意义上的5s,正确来说是至少5s以后会执行。因为Web API会设定一个5s的定时器,时间到期后将回调函数加到队列中,此时该回调函数还不一定会马上运行,因为队列中可能还有之前加入的其他回调函数,而且还必须等到Call Stack空了之后才会从队列中取一个回调执行。
所以常见的setTimeout(callback, 0) 的做法就是为了在常规的调用介绍后马上运行回调函数
console.log('Hi');
setTimeout(function() {
console.log('callback');
}, 0);
console.log('Bye');
// 输出
// Hi
// Bye
// callback
在说一个容易犯错的栗子:
for (var i = 0; i < 5; i++) {
setTimeout(function() {
console.log(i);
}, 1000 * i);
}
// 输出:5 5 5 5 5
上面这个例子并不是输出0,1,2,3,4,第一反应觉得应该是这样。但梳理了JS的时间循环后,应该很容易明白。
调用栈先执行 ==for(var i = 0; i < 5; i++) {...}== 方法,里面的定时器会到时间后会直接把回调函数放到事件队列中,等for循环执行完在依次取出放进调用栈。当for循环执行完时,i的值已经变成5,所以最后输出全都是5
总结
- JS引擎主要负责把JS代码转为机器能执行的机器码,而JS代码中调用的一些WEB API则由运行环境提供,这里代指浏览器。
- JS是单线程,每次都从调用栈取出代码进行掉用。如果当前代码非常耗时,则会阻塞当前线程浏览器导致浏览器卡顿。
- 回调函数是通过加入到事件队列,等待Event Loop拿出并放到调用栈中进行调用。只有Event Loop监听到调用栈(Call Stack)为空时,才会从事件队列中从队头拿出回调函数放入调用栈里。