机器学习算法基础3---分类算法--k近邻算法
目录
分类算法-k近邻算法(KNN)
计算距离公式
测试集与训练集
sklearn k-近邻算法API
k近邻算法实例-预测入住位置
分类算法-k近邻算法(KNN)
定义:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。通过你的“邻居”来推断出你的类别,KNN算法最早是由Cover和Hart提出的一种分类算法。重要思想:相似的样本,特征之间的值都是相近的。
计算距离公式
两个样本的距离可以通过如下公式计算,又叫欧式距离,比如说,a(a1,a2,a3),b(b1,b2,b3)。
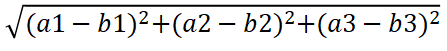
k_近邻算法:需要做标准化处理。
测试集与训练集
用(训练集)来拟合模型中的参数,进而预测测试集,预测值和实际值的差别就可以用来衡量模型的预测性能
sklearn k-近邻算法API
•sklearn.neighbors.KNeighborsClassifier(n_neighbors=5,algorithm='auto')
•
n_neighbors
:
int,
可选(默认
= 5
),
k_neighbors
查询默认使用的邻居数
•
•
algorithm
:
{‘auto’
,
‘
ball_tree
’
,
‘
kd_tree
’
,
‘brute’}
,可选用于计算最近邻居的算法:
‘
ball_tree
’
将会使用
BallTree
,
‘
kd_tree
’
将使用
KDTree
。
‘auto’
将尝试根据传递给
fit
方法的值来决定最合适的算法。
(
不同实现方式影响效率
)
k近邻算法实例-预测入住位置


def knncls():
"""
K-近邻预测用户签到位置
:return:None
"""
# 读取数据
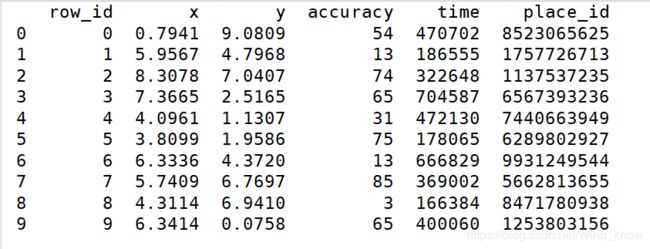
data = pd.read_csv("../data/FBlocation/train.csv")
print(data.head(10))x,y定位的坐标,time时间戳,place_id 目标值(需要减少目标值)。
# 处理数据
# 1、缩小数据,查询数据筛选
data = data.query("x > 1.0 & x < 1.25 & y > 2.5 & y < 2.75")
# 处理时间的数据 将time转化日期格式
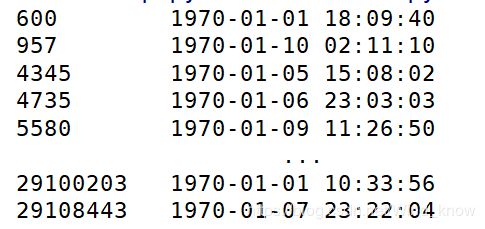
time_value = pd.to_datetime(data['time'], unit='s')
print(time_value)
把日期格式转换成 字典格式
DatetimeIndex # 把日期格式转换成 字典格式
time_value = pd.DatetimeIndex(time_value)
# 构造一些特征
data['day'] = time_value.day
data['hour'] = time_value.hour
data['weekday'] = time_value.weekday # 把时间戳特征删除 按列
data = data.drop(['time'], axis=1)
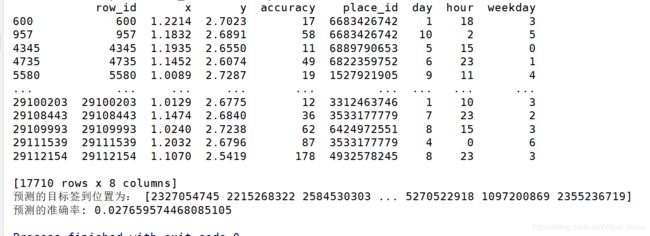
print(data)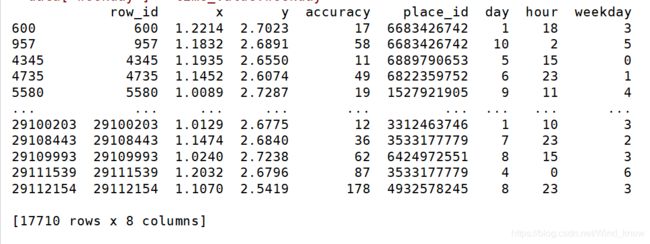
# 处理数据
# 1、缩小数据,查询数据筛选
data = data.query("x > 1.0 & x < 1.25 & y > 2.5 & y < 2.75")
# 处理时间的数据 将time转化日期格式
time_value = pd.to_datetime(data['time'], unit='s')
# print(time_value)
# 把日期格式转换成 字典格式
time_value = pd.DatetimeIndex(time_value)
# 构造一些特征
data['day'] = time_value.day
data['hour'] = time_value.hour
data['weekday'] = time_value.weekday
# 把时间戳特征删除
data = data.drop(['time'], axis=1)
print(data)
# 把签到数量少于n个目标位置删除
place_count = data.groupby('place_id').count()
tf = place_count[place_count.row_id > 3].reset_index()
data = data[data['place_id'].isin(tf.place_id)]
# 取出数据当中的特征值和目标值
y = data['place_id']
x = data.drop(['place_id'], axis=1)#删除place_id后剩下的为特征值
# 进行数据的分割训练集合测试集 x特征值,y目标值,test_size测试集的大小
#x_train,训练集的特征值 x_test,测试集的特征值 ,y_train,训练集的目标值 ,y_test,测试集的目标值。
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.25)
# # 特征工程(标准化)
# std = StandardScaler()
#
# # 对测试集和训练集的特征值进行标准化
# x_train = std.fit_transform(x_train)
#
# x_test = std.transform(x_test)
# 进行算法流程 # 超参数
knn = KNeighborsClassifier()#参数默认是5
# fit, predict,score
knn.fit(x_train, y_train)
# 得出预测结果
y_predict = knn.predict(x_test)#参数测试集的特征值
print("预测的目标签到位置为:", y_predict)
# 得出准确率
print("预测的准确率:", knn.score(x_test, y_test))
标准化
# 特征工程(标准化)
std = StandardScaler()
# 对测试集和训练集的特征值进行标准化
x_train = std.fit_transform(x_train)
x_test = std.transform(x_test)#不用fit计算得出规则,直接转换
由此可见,经过标准化后,预测的准确率提高了。k值取很小:容易受异常点影响。k值取很大:容易受最近数据太多导致比例变化。
