Tensorflow-keras实战(一)
目录
理论部分
1.Tensorflow-keras简介
2.分类问题、回归问题、损失函数
3.神经网络、激活函数、批归一化、Dropout
4.Wide & deep 模型
5.超参数搜索
实战部分
1.Keras搭建分类模型
2.keras回调函数
3.keras搭建回归模型
4.keras搭建深度神经网络
5.keras实现wide&deep模型
6.keras与scikit-learn实现超参数搜索
理论部分
1.keras是什么?

Tensorflow-keras是什么

Tf-keras和keras联系

Tf-keras和keras区别


如何选择?

2.分类问题与回归问题

为什么需要目标函数

分类问题

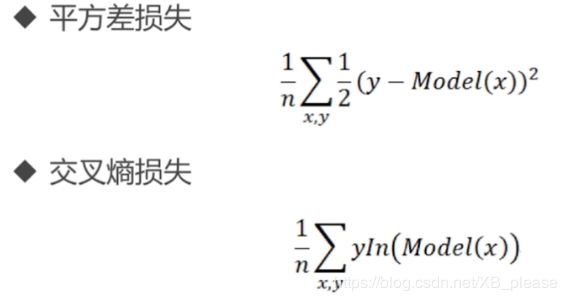
 回归问题
回归问题

目标函数
![]() 实战
实战
1.Keras搭建分类模型
2.keras回调函数
1.keras搭建分类模型
import matplotlib as mpl
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
import pandas as pd
import os
import sklearn
import sys
import time
import tensorflow as tf
from tensorflow import keras
print(tf.__version__)
print(sys.version_info)
for module in mpl,np,pd,sklearn,tf,keras:
print(module.__name__, module.__version__)
fashion_mnist = keras.datasets.fashion_mnist
(x_train_all,y_train_all),(x_test,y_test) = fashion_mnist.load_data()
x_valid, x_train = x_train_all[:5000],x_train_all[5000:]
y_valid, y_train = y_train_all[:5000],y_train_all[5000:]
print(x_valid.shape, y_valid.shape)
print(x_train.shape, y_train.shape)
print(x_test.shape, y_test.shape)
def show_single_image(img_arr):
plt.imshow(img_arr,cmap = "binary")
plt.show()
show_single_image(x_train[0])
def show_imgs(n_rows, n_cols, x_data, y_data, class_names):
assert len(x_data) == len(y_data)
assert n_rows * n_cols < len(x_data)
plt.figure(figsize = (n_cols * 1.4, n_rows * 1.6))
for row in range(n_rows):
for col in range(n_cols):
index = n_cols * row + col
plt.subplot(n_rows, n_cols, index+1)
plt.imshow(x_data[index], cmap="binary",
interpolation = 'nearest')
plt.axis('off')
plt.title(class_names[y_data[index]])
plt.show()
class_names = ['T-shirt','Trouser','Pullover','Dress',
'Coat','Sandal','Shirt','Sneaker',
'Bag','Ankle boot']
show_imgs(3, 5, x_train, y_train, class_names)
#tf.keras.models.Sequential()
"""
通过向 tf.keras.models.Sequential() 提供一个层的列表,就能快速地建立一个 tf.keras.Model 模型并返回
model = keras.models.Sequential()
model.add(keras.layers.Flatten(input_shape=[28,28]))
model.add(keras.layers.Dense(300,activation='relu'))
model.add(keras.layers.Dense(100,activation='relu'))
model.add(keras.layers.Dense(10,activation='softmax'))
"""
model = keras.models.Sequential([
keras.layers.Flatten(input_shape=[28,28]),
keras.layers.Dense(300,activation='relu'),
keras.layers.Dense(100,activation='relu'),
keras.layers.Dense(10,activation='softmax')
])
# relu: y = max(0,x)
#softmax: 将向量变成概率分布。x = [x1,x2,x3],
# y = [e^x1/sum,e^x2/sum,e^x3/sum],sum = e^x1+e^x2+e^x3
#reason for sparse: y->index. y->one_hot->[]
model.compile(loss = "sparse_categorical_crossentropy",
optimizer = 'sgd',
metrics = ['accuracy'])
model.layers
model.summary()
#[None,784]*w+b->[None,300] w.shape [784,300],b=[300]
history = model.fit(x_train,y_train,epochs=10,
validation_data=(x_valid,y_valid))
history.history
def plot_learning_curves(history):
pd.DataFrame(history.history).plot(figsize=(8,5))
plt.grid(True)
plt.gca().set_ylim(0,1)
plt.show()
plot_learning_curves(history)
2.标准化归一化
# x = (x-u)/ std
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
# x_train: [none,28,28]->[none,784]
x_train_scaled = scaler.fit_transform(
x_train.astype(np.float32).reshape(-1,1)).reshape(-1,28,28)
x_valid_scaled = scaler.transform(
x_valid.astype(np.float32).reshape(-1,1)).reshape(-1,28,28)
x_test_scaled = scaler.transform(
x_test.astype(np.float32).reshape(-1,1)).reshape(-1,28,28)
3.实现回调函数
# TensorBoard, earlystopping, ModelCheckpoint
logdir = './callbacks'
if not os.path.exists(logdir):
os.mkdir(logdir)
output_model_file = os.path.join(logdir,
"fashion_mnist_model.h5")
callbacks = [
keras.callbacks.TensorBoard(logdir),
keras.callbacks.ModelCheckpoint(output_model_file,
save_best_only = True),
keras.callbacks.EarlyStopping(patience = 5,min_delta = 1e-3),
]
history = model.fit(x_train_scaled,y_train,epochs=10,
validation_data=(x_valid_scaled,y_valid),
callbacks = callbacks)