Deep Attentive Tracking via Reciprocative Learning
2018-11-14 13:30:36
Paper: https://arxiv.org/abs/1810.03851
Project page: https://ybsong00.github.io/nips18_tracking/index
Code: https://github.com/shipubupt/NIPS2018
是的,我跟好多人一样,被标题中的 “Reciprocative Learning” 给弄懵逼了,听过 Meta-learning,Reinforcement Learning 等各种学习方法,这个 “Reciprocative” 还是第一次见到(T_T)。行吧,不多扯了,看正文。
本文基于 tracking-by-detection 框架提出一种新颖的 Attention 机制来复制跟踪,实现在跟踪过程中自动 attend target object regions。网络结构看起来也比较简单,如下所示:
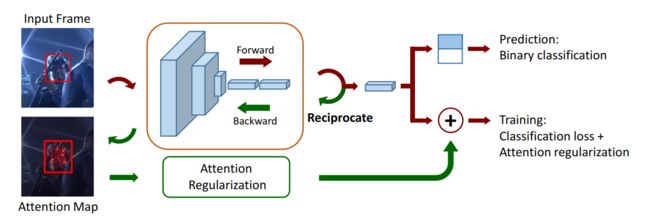
本文利用 attention map 来作为 “regularization terms” 来帮助分类器更加关注 target object,从而对 appearance change,更加鲁棒。在测试阶段,作者直接用 the classification score 来定位目标物体。
1. Attention Exploiting:
我们首先展示我们如何将 visual attention 结合到 tracking-by-detection framework 中。我们将输入记为 I,网络的输出是关于 score 的 向量(a vector of scores)。每一个元素得分代表了,I 有多像某一个预先设定的类别 c。给定一个特定的样本 I0,我们利用一级泰勒展开式来估计 score function $f_c (I)$ at a point $z_0$:

其中,point $z_0$ 属于 $I_0$ 删除的 $\in$-neighborhood 。公式(1)的估计对于任何的 $I_0$ 近邻的任何 point 都是成立的。所以,$f_c(I)$ 在 points $z_0$ 和 $I_0$ 的导数是相等的,因为这两个点是无限接近的。在公式(1)中,对应输入 I 在样本 $I_0$ 的导数是 Ac:

公式(1)表明类别 c 的输出得分是受到 Ac 的 element values 影响的。也就是说,Ac 的值表明了 I0 中对应像素的重要性,来产生类别得分。 如此,我们可以将 Ac 看做是一种 attention map。对于另一种特定输入图像 I1,我们再利用泰勒展开式在 point z1,来估计 $f_c (I)$。点 z1 属于删除的 I1 近邻。对于所有的 I1 近邻的所有点,这个估计都是成立的,所以,对于每一个 image sample 来说,the attention map Ac 都是特定的。
根据公式(2),我们计算网络的输出 $f_c (I)$ 对应 input I 的偏导。这个可以通过如下两个步骤来实现:
step-1,我们将输入样本 $I_0$ 输入到网络中,得到预测的 score $f_c (I_0)$ ;
step-2,我们得到 $f_c (I)$ 对 I 的偏导。根据链式法则,我们偏导可以通过反向传播进行计算。我们将第一层的输出,在反向传播过程中,当做是 attention map Ac。
我们仅仅选择是 positive values 的梯度,因为他们有对最终的分类有明显的贡献。所以,the attention map Ac 总是 positive 的,并且反映了网络是如何 attend 输入样本 $I_0$ 的。注意到,在反向传播过程中,我们将 网络的参数固定,不进行更新。
2. Attention Regularization:
Tracking-by-detection framework 通常定义 target object 为 positive class,背景物体作为 negative class 来进行二元分类器的训练。对于每一个 input sample $I_0$,我们得到两个 attention maps。一个是 the positive attention map,记为 Ap,另一个为 negative attention map,记为An。
对于一个正的训练样本来说,我们期望 Ap 中跟 target object 相关的物体尽可能的大。作为对比,An 的像素值尽可能的小。所以,the attention 正则化项应该定义为:

其中,$\mu$ and $\delta$ 是均值和标注差操作符。另一个方面,对于 negative training samples,我们构建对应的正则化项为:
利用公式(3)(4),我们添加这两项到原始的分类 loss 函数中,得到:
![]()
公式(5)表明了 attention map 是如何影响到 deep classifier 的训练。
For positive samples, we aim to increase the attention around the target object in two aspects. The first one is to increase the mean but decrease the standard deviation of A p so that the pixel intensity values are large and with small variance. The second one is to decrease the mean but increase the standard deviation of An so that the pixel intensity values are small and with large variance. These two aspects reflect that the classifier learns to increase the true positive rates while decreasing the false negative rates.
A similar intuition is shown in Eq. 4 where we decrease the false positive rates and increase the true negative rates of the classifier. As a result, the regularization terms help in increasing the classification accuracy by using the constraint from attention maps. This contributes to the classifier training process as the attention maps heavily influence the output class scores as shown in Eq. 1.
3. Reciprocative Learning:
通过将 正则化项结合到 loss function 中,我们借助于 BP算法以及链式法则来实现 Reciprocative Learning。
本文的算法仅仅在训练阶段使用,使得 classifier 选择性的对 target object 比较关注,而逐渐忽略 background 物体。上图展示了这个大致的过程。
4. Tracking Process:
4.1 Model Initialization:
根据 所提出的 training samples 与 GT 之间的 IoU 来决定 pos 和 neg samples 的划分(阈值设定为 0.5)。
4.2 Online Detection:
根据上一帧跟踪的结果,我们首先采样出 N2 个样本输入到 model 中,并且选择带有最大响应得分的 proposal。BBox regression 模型也被应用到 BBox 的调整中,以得到更加准确的结果。
4.3 Model Update:
每隔 T 帧更新一次模型,更新 fc layers H2 次。
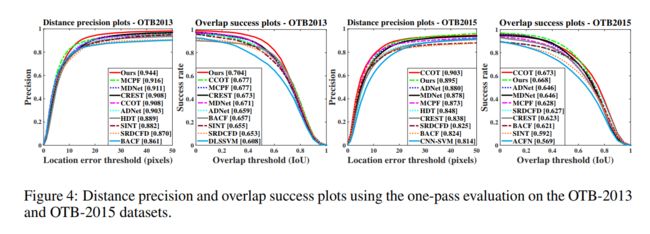
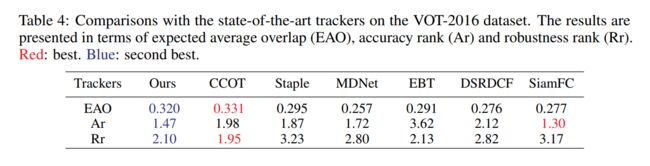
5. Experiments:
==