大数据项目之电商数仓离线计算
本次项目是基于企业大数据的电商经典案例项目(大数据日志以及网站数据分析),业务分析、技术选型、架构设计、集群规划、安装部署、整合继承与开发和web可视化交互设计。
1.系统数据流程设计
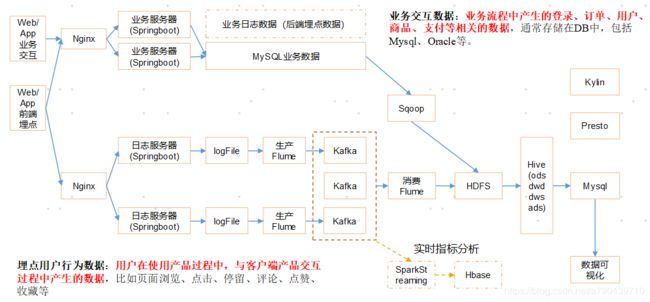
我这里主要分享下系统数据大致流通的过程。
电商数据来源为两部分:
第一部分是java以及前端等程序员在网站做的埋点,用户点击产生的日志数据,通过springboot以及nginx等将数据分发到日志服务器。这里我们直接写了一个java程序,模拟产生了大量数据,结果直接保存在服务器上。
第二部分是网站业务的数据,一般保存在mysql数据库上面。
数据传输流程:
日志数据通过flume收集,然后保存在kafka中。再通过flume传输到hdfs上。
业务数据直接通过sqoop导入到hdfs上。
数据处理流程:
编写hql以及脚本程序,并放在azakban上作为每日定时任务,将最后结果导入mysql数据库上面。
数据展示流程:
java及前端程序员编写,在页面上展示处理完成后放在mysql上的数据。
后期扩展:
kafka中保存的内容可以让spark streaming来消费,进行实时处理。hdfs上的数据也可以利用presto,druid进行近实时查询。
2.软件使用的版本如下:
注:大数据的软件为apache下的。
hadoop : 2.7.2
flume: 1.7.0
kafka:0.11.0.2
kafka manager:1.3.3.22
hive:1.2.1
sqoop:1.4.6
mysql:5.6.24
azkaban:2.5.0
java:1.8
zookeeper:3.4.10
presto:0.189
3.集群服务器部署:
| 服务名称 |
子服务 |
服务器 hadoop102 |
服务器 hadoop103 |
服务器 hadoop104 |
| HDFS |
NameNode |
√ |
|
|
| DataNode |
√ |
√ |
√ |
|
| SecondaryNameNode |
|
|
√ |
|
| Yarn |
NodeManager |
√ |
√ |
√ |
| Resourcemanager |
|
√ |
|
|
| Zookeeper |
Zookeeper Server |
√ |
√ |
√ |
| Flume(采集日志) |
Flume |
√ |
√ |
|
| Kafka |
Kafka |
√ |
√ |
√ |
| Flume(消费Kafka) |
Flume |
|
|
√ |
| Hive |
Hive |
√ |
|
|
| MySQL |
MySQL |
√ |
|
|
| Sqoop |
Sqoop |
√ |
|
|
| Presto |
Coordinator |
√ |
|
|
| Worker |
|
√ |
√ |
|
| Azkaban |
AzkabanWebServer |
√ |
|
|
| AzkabanExecutorServer |
√ |
|
|
|
| Druid |
Druid |
√ |
√ |
√ |
| 服务数总计 |
|
13 |
8 |
9 |
4.技术点大致解析:
flume采集日志:
1.flume采用的1.7.0版本,此版本的source更新了一个Taildir Source。这个source相比exec source和spooling directory source的优点在于:
Taildir Source支持断点续传,多目录。因为会有一个文件专门记录读取的文件内容到哪里了。
2.自定义了ETL拦截器和分类型拦截器。
ETL拦截器实现了简单的数据过滤和清洗。注意复杂的清洗还是在hive中清洗,flume只适合做一些最简单的清洗,因为它在复杂的数据清洗上性能并不是很好。
分类型拦截器主要是对数据进行分发到kafka不同的topic中去,所以需要配置不同通道的selector。
3.flume采集日志的channel并不是file channel或者memory channel而是kafka channel,配置了kafka channel之后并不需要配置sink。
flume消费kafka中数据:
这里了为什么会增加一层kafka和一层flume而不是直接由flume采集日志直接到hdfs上了?因为考虑到后期采集的日期数据可能会重复利用,比如做实时计算。难道需要又重新搭建flume来采集吗?显然既耗时又浪费集群资源。所以统一保存在kafka中,其他业务有需求直接从kafka中取数据就行了。现在就是用flume从kafka中取得数据保存在hdfs上。
数据仓库的理论:
数据仓库一般分为4层。
ods:原始数据层。数据收集后直接保存在hdfs上,未做任何处理。
dwd:数据明细层。数据经过了etl清洗。
dws:服务数据层。数据经过一些分类聚合,轻度汇总。
ads:数据应用层。提供各种分析的报表结果进行展示。
数仓建模:事实表,维度表,事务型事实表,周期型事务表,星型模型。
hadoop安装配置:
支持lzo,snappy压缩,一般hive表配置为外部表,snappy压缩,orc格式。
hive的搭建:
hive这里主要想说明的是hql其实就是mapreduce,如果hql复杂,启动几个mapreduce的时候,中间结果会保存在磁盘,然后再从磁盘上读取结果进行下一个mapreduce计算,这样太浪费时间了。所以将hive的计算引擎从mapreduce换成了tez,tez是基于内存来计算的,所以中间结果直接保存在内存中,计算效率大大增加。
hive自定义函数:
hive自定义函数有三种。
udf:一对一。输入一个值输出一个值。
udtf:一对多或者多对多。输入一个值或多个值输出多个值,配合later view炸裂数据。
udaf:多对一。输入多个值输出一个值。
自定义函数主要是针对有些复杂的字符串,比如json更方便解析。
拉链表:
这个重点讲解一下。
拉链表记录每天信息的生命周期,一旦一条信息的生命周期结束,就重新开始一条新的纪录,并把当前日期放入生效开始日期。
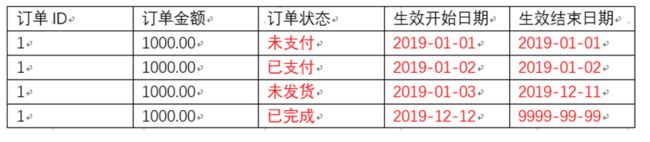
举个例子,比如某一条订单,可能客户2019.01.01下单了,但是他当天没支付,订单就是未支付状态。这条数据同步到数据仓库后就保存下来了,这条数据(订单状态:未支付)的生效开始日期是2019.01.01,结束日期也是9999.99.99,因为不知道什么时候它的状态改变,所以给与一个最大值。第二天,用户支付了,同步到数据仓库后,第一天未支付的订单的状态是未支付就过期了,这条数据也就失效了,所以这条数据(订单状态:未支付)的生效开始日期是2019.01.01,结束日期也是2019.01.01。同时新增一条数据(订单状态:已支付)的生效开始日期是2019.01.02,结束日期也是9999.99.99。第三天,商家收到订单后准备发货但是还没有发货,同步到数据仓库后,第二天未支付的订单的状态是已支付就过期了,这条数据也就失效了,所以这条数据(订单状态:已支付)的生效开始日期是2019.01.02,结束日期也是2019.01.02。同时新增一条数据(订单状态:未发货)的生效开始日期是2019.01.03,结束日期也是9999.99.99。接下来一直到2019年12月12日,商家才发货,此时和前面逻辑一样修改状态为未支付的订单数据,同时新增状态为已完成的数据。
为什么要这么做了?每条数据都给与一个生效开始时间,生效结束时间?原因一,保存在数仓中的数据是不能更改的,也就是说订单状态是不能修改的,所以必须记录这条数据在什么时间段内有效。原因二,像刚才所说的,如果商家拖了12个月才发货,难道每天都记录一条未发货的订单数据了,没有必要,造成以后的数据分析会有大量冗余垃圾数据,还要去清洗。所以只需要记录一下未支付从哪天开始有效,哪天无效就行了。至于拉链表如何实现了,这里我就不多说了,但是肯定需要一张临时表来配合。
spark streaming:这部分可以看我另一篇博文https://blog.csdn.net/a790439710/article/details/103173099
sqoop:没什么好说的。
azkaban:没什么好说的。