大数据项目
项目说明 :
利用scrapy爬取中华英才网和前程无忧上面有关’数据分析师’, ‘大数据开发工程师’, '数据采集’的数据并保存到mongodb。然后再上传到hive中处理数据,再将处理好的数据保存到mysql,最后将保存的数据进行数据可视化。
注:如果有不会scrapy的可以参照我的这几个scrapy项目
1、利用scrapy爬取链家网小区数据
2、scrapy爬取京东图书的数据
3、scrapy crawl爬取我爱我家二手房的数据
4、scrapy 下载壁纸(图片)详细教程
5、scrapy 中的 crawl 模块 批量下载图片(详细教程)
1、利用scrapy爬取前程无忧上和中华英才网上面的数据

1.1编写items

1.2编写前程无忧的spider

1.3编写中华英才网的spider

1.4编写pipelines将数据保存到mongodb
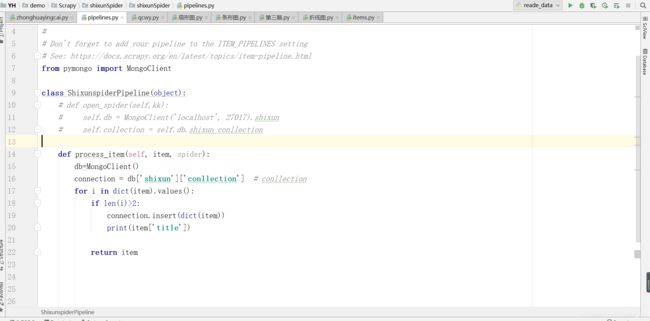
2、将数据上传并清洗
首先在pycharm中将数据格式统一。

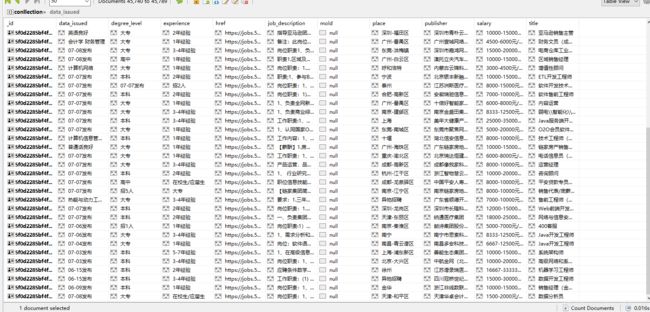
- 在hive里面创建数据库job_data; 然后再job_data里面创建一个datas的表里面用来存储所有mongodb中的数据,

上传数据
利用flume监听
在flume的conf下面编写hdfs.conf
a1.sources.r1.type=exec
a1.sources.r1.command=tail -F /usr/flume/data/datas.txt
a1.sources.r1.bind=0.0.0.0
a1.sources.r1.port=44444
a1.sinks.s1.type=HDFS
a1.sinks.s1.hdfs.path=hdfs://master:9000/usr/hive/warehouse/job_data.db/datas/datas.txt
a1.sinks.s1.hdfs.rollCount=0
a1.sinks.s1.hdfs.fileType=DataStream
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
a1.sources.r1.channels=c1
a1.sinks.s1.channel=c1
./flume-ng agent -c conf -f hdfs.conf -name a1 -Dflume.root.logger=DEBUG,console
创建一个mma 表里面用来储存**数据采集,数据分析,数据开发**这几个职业
的最高工资,最低工资,平均工资。
create table mma as select '数据开发' as name ,max(salary) as t_max,min(salary) as t_min, avg(salary) as t_avg from datas
where title like '%开发%';
insert into table mma select '数据分析' as name ,max(salary) as t_max,min(salary) as t_min, avg(salary) as t_avg from datas
where title like '%分析%';
insert into table mma select '数据采集' as name ,max(salary) as t_max,min(salary) as t_min, avg(salary) as t_avg from datas
where title like '%采集%';

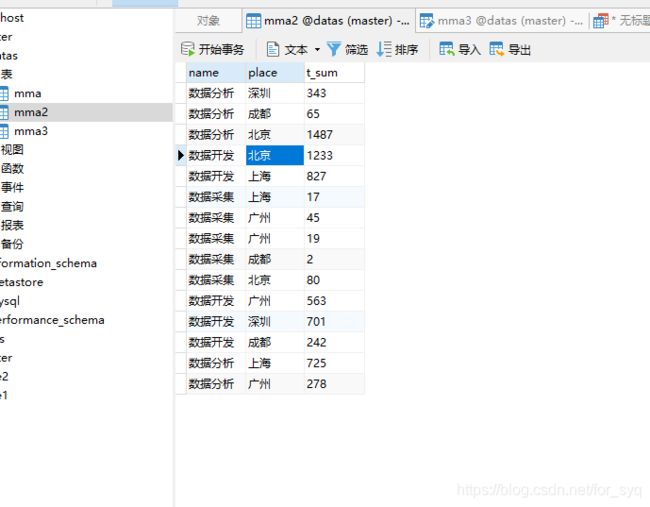
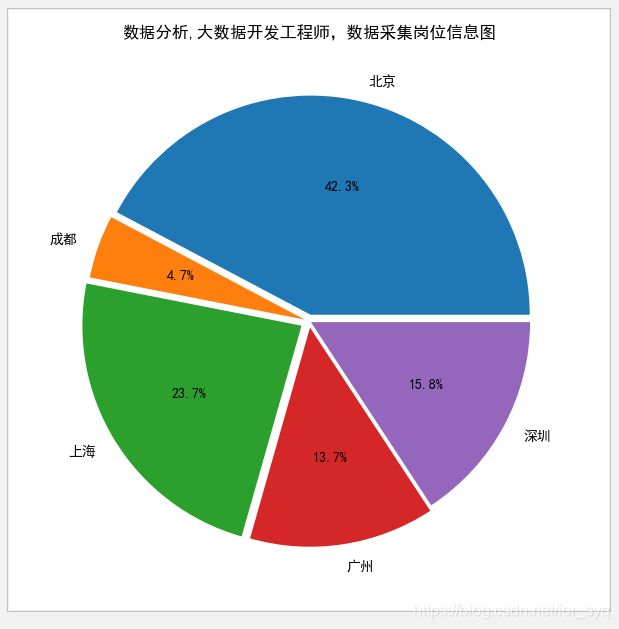
创建一个mma2的表用来储存数据采集,数据分析,数据开发这几个职业在成都,北京,上海,广州,深圳的岗位数。
create table mma2 as select '数据开发' as name ,'北京' as place,count(*) as t_sum from datas
where title like '%开发%' and place like '%北京%';
insert into table mma2 select '数据开发' as name ,'上海' as place,count(*) as t_sum from datas
where title like '%开发%' and place like '%上海%';
insert into table mma2 select '数据开发' as name ,'广州' as place,count(*) as t_sum from datas
where title like '%开发%' and place like '%广州%';
insert into table mma2 select '数据开发' as name ,'深圳' as place,count(*) as t_sum from datas
where title like '%开发%' and place like '%深圳%';
insert into table mma2 select '数据开发' as name ,'成都' as place,count(*) as t_sum from datas
where title like '%开发%' and place like '%成都%';
insert into table mma2 select '数据分析' as name ,'上海' as place,count(*) as t_sum from datas
where title like '%分析%' and place like '%上海%';
insert into table mma2 select '数据分析' as name ,'广州' as place,count(*) as t_sum from datas
where title like '%分析%' and place like '%广州%';
insert into table mma2 select '数据分析' as name ,'深圳' as place,count(*) as t_sum from datas
where title like '%分析%' and place like '%深圳%';
insert into table mma2 select '数据分析' as name ,'成都' as place,count(*) as t_sum from datas
where title like '%分析%' and place like '%成都%';
insert into table mma2 select '数据分析' as name ,'北京' as place,count(*) as t_sum from datas
where title like '%分析%' and place like '%北京%';
insert into table mma2 select '数据采集' as name ,'上海' as place,count(*) as t_sum from datas
where title like '%采集%' and place like '%上海%';
insert into table mma2 select '数据采集' as name ,'广州' as place,count(*) as t_sum from datas
where title like '%采集%' and place like '%广州%';
insert into table mma2 select '数据采集' as name ,'深圳' as place,count(*) as t_sum from datas
where title like '%采集%' and place like '%深圳%';
insert into table mma2 select '数据采集' as name ,'成都' as place,count(*) as t_sum from datas
where title like '%采集%' and place like '%成都%';
insert into table mma2 select '数据采集' as name ,'北京' as place,count(*) as t_sum from datas
where title like '%采集%' and place like '%北京%';

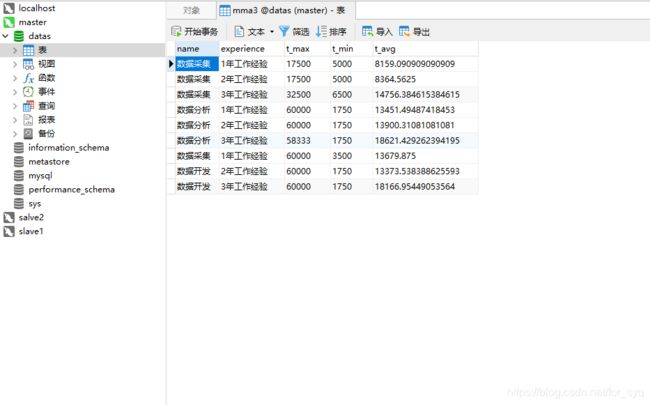
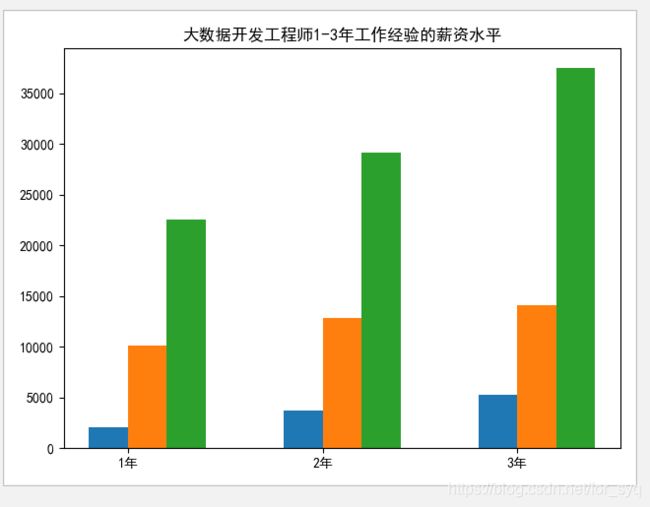
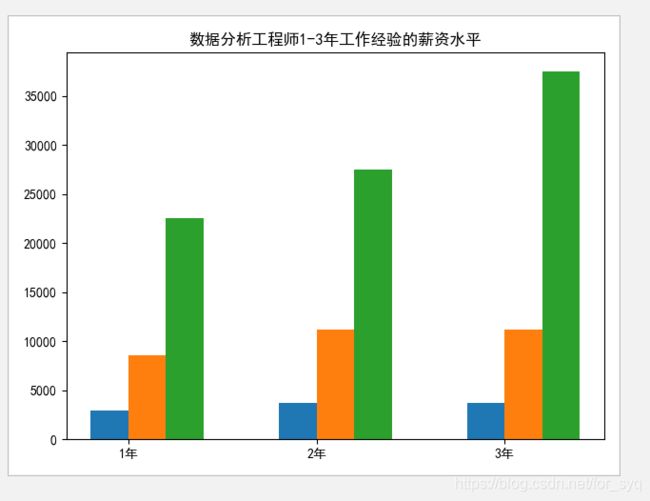
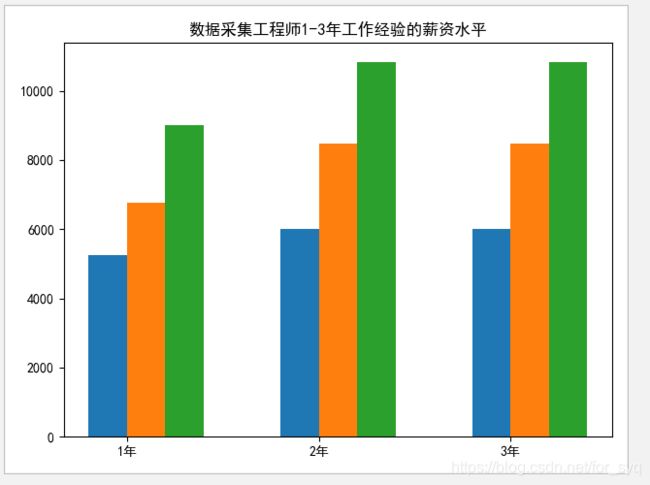
创建一个mma3的表用来储存数据采集,数据分析,数据开发这几个职业1-3年工作经验的薪资水平(最高工资,最低工资,平均工资)
create table mma3 as select '数据开发' as name ,'1年工作经验' as experience,max(salary) as t_max,min(salary) as t_min, avg(salary) as t_avg from datas
where title like '%开发%' and experience like '%1%';
insert into table mma3 select '数据开发' as name ,'2年工作经验' as experience,max(salary) as t_max,min(salary) as t_min, avg(salary) as t_avg from datas
where title like '%开发%' and experience like '%2%';
insert into table mma3 select '数据开发' as name ,'3年工作经验' as experience,max(salary) as t_max,min(salary) as t_min, avg(salary) as t_avg from datas
where title like '%开发%' and experience like '%3%';
insert into table mma3 select '数据分析' as name ,'1年工作经验' as experience,max(salary) as t_max,min(salary) as t_min, avg(salary) as t_avg from datas
where title like '%分析%' and experience like '%1%';
insert into table mma3 select '数据分析' as name ,'2年工作经验' as experience,max(salary) as t_max,min(salary) as t_min, avg(salary) as t_avg from datas
where title like '%分析%' and experience like '%2%';
insert into table mma3 select '数据分析' as name ,'3年工作经验' as experience,max(salary) as t_max,min(salary) as t_min, avg(salary) as t_avg from datas
where title like '%分析%' and experience like '%3%';
insert into table mma3 select '数据采集' as name ,'1年工作经验' as experience,max(salary) as t_max,min(salary) as t_min, avg(salary) as t_avg from datas
where title like '%采集%' and experience like '%1%';
insert into table mma3 select '数据采集' as name ,'2年工作经验' as experience,max(salary) as t_max,min(salary) as t_min, avg(salary) as t_avg from datas
where title like '%采集%' and experience like '%2%';
insert into table mma3 select '数据采集' as name ,'3年工作经验' as experience,max(salary) as t_max,min(salary) as t_min, avg(salary) as t_avg from datas
where title like '%采集%' and experience like '%3%';

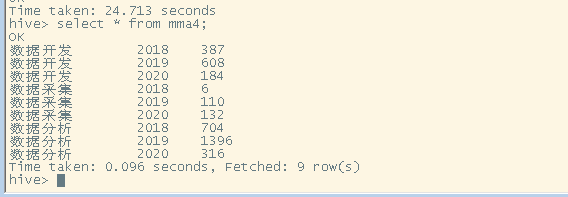
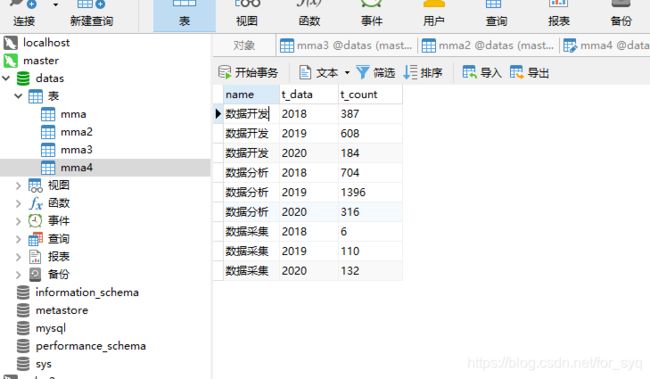
创建一个mma4的表用来储存数据采集,数据分析,数据开发这几个职业每年的需求,
create table mma4 as select '数据开发' as name , ‘2018’,count(*) as t_sum
from data
where title like '%开发%' and t_data like '%2018%';
insert into mma4 select '数据开发' as name ,'2019',count(*) as t_sum
from data
where title like '%开发%' and t_data like '%2019%';
insert into mma4 select '数据开发' as name ,'2020',count(*) as t_sum
from data
where title like '%开发%' and t_data like '%2020%' ;
insert into mma4 select '数据采集' as name ,'2018',count(*) as t_sum
from data
where title like '%采集%' and t_data like '%2018%';
insert into mma4 select '数据采集' as name ,'2019',count(*) as t_sum
from data
where title like '%采集%' and t_data like '%2019%';
insert into mma4 select '数据采集' as name ,'2020',count(*) as t_sum
from data
where title like '%采集%' and t_data like '%2020%';
insert into mma4 select '数据分析' as name ,'2018',count(*) as t_sum
from data
where title like '%分析%' and t_data like '%2018%';
insert into mma4 select '数据分析' as name ,'2019',count(*) as t_sum
from data
where title like '%分析%' and t_data like '%2019%';
insert into mma4 select '数据分析' as name ,'2020',count(*) as t_sum
from data
where title like '%分析%' and t_data like '%2020%';
3 利用sqoop将hive中的数据表导入mysql
在sqoop中执行
bin/sqoop export --connect jdbc:mysql://master:3306/datas --username root --password 你的mysql数据库密码 --table mma--export-dir /usr/hive/warehouse/job_data.db/mma--input-fields-terminated-by '\001'

bin/sqoop export --connect jdbc:mysql://master:3306/datas --username root --password 你的密码 --table mma2 --export-dir /usr/hive/warehouse/job_data.db/mma2 --input-fields-terminated-by '\001'
bin/sqoop export --connect jdbc:mysql://master:3306/datas --username root --password 你的密码 --table mma3 --export-dir /usr/hive/warehouse/job_data.db/mma3 --input-fields-terminated-by '\001'
bin/sqoop export --connect jdbc:mysql://master:3306/datas --username root --password 你的密码 --table mma4 --export-dir /usr/hive/warehouse/job_data.db/mma4 --input-fields-terminated-by '\001'
4,将mysql中的数据可视化
1、分析“数据分析”、“大数据开发工程师”、“数据采集”等岗位的平均工资、最高工资、最低工资,并作条形图将结果展示出来;
2,分析“数据分析”、“大数据开发工程师”、“数据采集”等大数据相关岗位在成都、北京、上海、广州、深圳的岗位数,并做饼图将结果展示出来
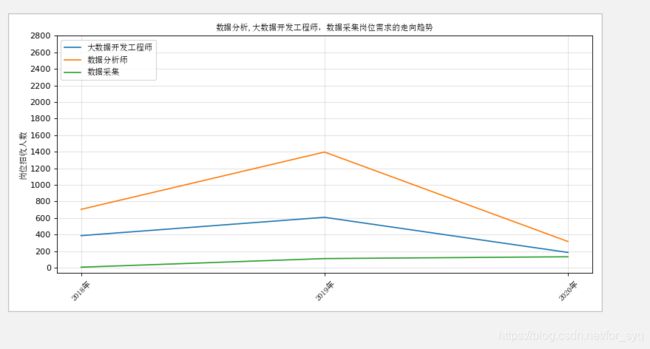
3、分析大数据相关岗位1-3年工作经验的薪资水平(平均工资、最高工资、最低工资),并做出条形图展示出来;
分析大数据相关岗位几年需求的走向趋势,并做出折线图展示出来;