ddd的战术篇: aggregate的设计策略
上一篇文章讲了repository的实现。结合前面的文章基本把ddd战术篇中的登场人物都介绍了一遍。依次是如下几个角色。
首先是位于domain层的domain objects
- aggregate
- entity
- value object
- domain service
- repository
- specification
- factory
另外有还有两种service。application service, infrastructure service.
当我们分析业务,实际建模时,最重要的当然是aggregate, entity与value object。
我们会将业务逻辑尽量写进entity与value object。
而aggregate还有确保数据完整性的责任。entity,value object也最终隶属于某个aggregate。(value object如果不需要永久化的话,那它可以独立于aggregate)
因此aggregate的设计是十分重要的,这篇文章就来谈谈aggregate的设计策略。
尽量设计小aggregate?
什么是小aggregate?
那我们先看看什么是大的吧~
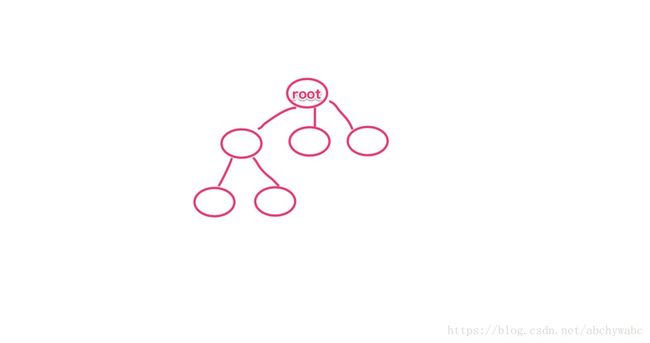
如果所示,root entity直接引用了很多的entity。
我们用例子来说明一下。假设我们对处理一个教室物品管理的问题。教室里有椅子,桌子和黑板这些物品,为了解释数据完整性的问题,假设一个教室里不能有超过50样物品。另一个需求是假设这些物品需要维护,要记录各个物品是在何时维护的。
大概是这么一个关系
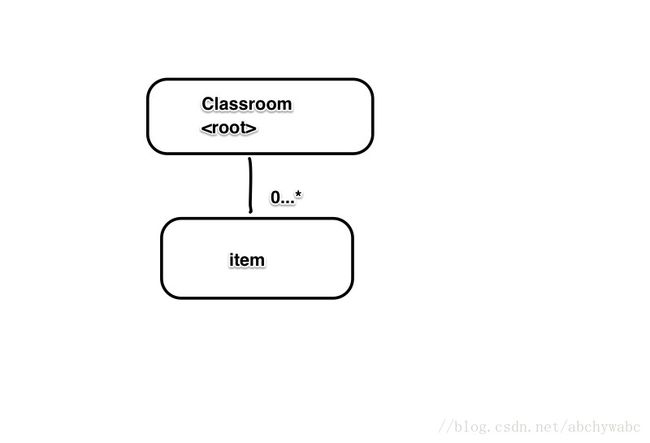
比较直观的方案当然是把教室当作一个aggregate,里边有它的物品。
首先是教室类,他是一个entity
public class Classroom {
private ClassroomId classroomId;
private String classRoomNo; // eg: 402
private List- items;
public Item add(Item item) throws ItemLimitExceededException {
if(items.size() == 50) {
throw new ItemLimitExceededException();
}
item.add(item);
}
public Item findItem(ItemId itemId){
items.toStream().filter(item -> item.getItemId() == itemId).findFirst().getOrElse( null );
}
}
通过在add()方法中增加检验来保证数据完整性。
物品类(椅子,桌子,黑板什么的)
@Getter
public class Item {
private ItemId itemId;
private ItemType itemType;
private Date maintenanceDate;
public void maintain(){
maintenanceDate = DateUtils.now(); // 更新检测日
}
}
public enum ItemType {
Chair, Desk, Blackboard
}
需不需要具体的Desk,Chair,Blackboard类还是只要Item一个类就够了是可以讨论的问题,不过现在我们关注的不是这个,而是Classroom这个aggregate。当我们一这个方式实现时,我们获取Classroom的引用时,必然会把它所包含的物品一起获取。
想象一下ClassroomRepository的实现,获得某一个id的Classroom。不仅要读取classroom,我们不得不也把所有的物品items也一起读取。这个是个比较低效的做法的。
另外,按照这样的做法,如果你对某一个教室进行更新时,还会更新它所包含的物品。比如当你需要更改教室的名字,明明是和椅子,桌子无关的处理,但也必须去更新他们。这样的更新范围较大,当这个系统需要管理的东西变得十分庞大,并发处理很多时,容易导致锁问题的出现,造成更新的失败。(当然现实可能是这个系统永远不会变得那么大,难道这么一个管理系统会指望同时在线用户数亿?我承认这个例子是在是太不合适勒orz,不过意思能传达就好了…早知道该用论坛什么的做例子!)
此外,因为ddd的aggregate思想的一些限制,位于某一个aggregate内的entity,你必须通过它的root entity才能获取的。在这个例子中即你要获得一张Chair的引用,你必须先获得它所在Classroom的引用才行。Chair不是root aggregate,它没有repository,所以也不存在跳过Classroom的作弊方式。那这会有什么问题呢。假设我们需要维修了一张Chair。记录他的维护时间。
chair.maintain();大概会是相面这个样子
Classroom classroom = classroomRepository.findOne(new ClassroomSpecificationById(classroomId);
Item chair = classroom.findItem(chairId);
chair.maintain();
为了调用一张Item椅子的方法,我们必须把Classroom读取出,连带一群我们根本不在意的Desk,Chair。这样的做法超级低效,在高并发情况下,会有更新失败就更容易发生(这样用户体验会很差哦!如果你这么干,你就等着和产品经理或者设计师单挑吧!或者你是被群殴的那位!)
那如果不把所有object都扔进一个aggregate,怎么办。那就拆分成好几个aggregate。把物品Item也作为aggregate。
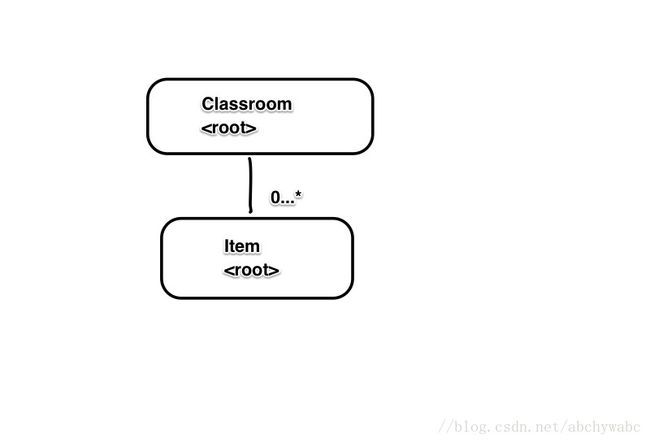
@Getter
public class Item {
private ItemId itemId;
private ItemType itemType;
private Date maintenanceDate;
public void maintain(){
maintenanceDate = DateUtils.now(); // 更新检测日
}
}其实Item本身的实现没有什么变化啦~
接着是教室类
public class Classroom {
private ClassroomId classroomId;
private String classRoomNo; // eg: 402
private List itemIds;
public Item add(ItemId itemId) throws ItemLimitExceededException {
if(itemIds.size() == 50) {
throw new ItemLimitExceededException();
}
itemIds.add(itemId);
}
} aggregate之间的引用,在ddd中是通过id引用的。例子中Classroom这个aggregate是持有的Item的root aggregate的id(好绕口)来表示Classroom与Item的包含关系的。
按照这样的设计,Item可以有自己的repository,你可以不通过Classroom对某个Item进行操作。
Item item = itemRepository.find(new ItemSpecification(itemId));
item.maintain();当然你也必须放弃一个功能,便是从Classroom这个aggregate中直接获取某个Item引用的功能。findItem()这个方法就实现不了啦。
* 我见过一些里类似于在entity 中放入repository的做法。比如像下面这样。
public class Classroom {
private ItemRespository itemRepository;
public Item findItem(ItemId itemId) {
return itemRepository.findOne(new ItemSpecificationById(itemId));
}
}个人不是很推荐这种做法。因为entity依赖于外部的repository。另外repository是无状态的,和entity不太般配~
归纳一下
大aggregate的缺点。
1. 从aggregate的角度来说,每次获得一个aggregate的引用会读取过多的数据
2. 从aggregate的子entity的角度来说,所有的操作都必须经过root entity,如果对子entity的操作可能影响数据完整性,这种方式是可行的。反之,这样的方式便是很笨拙的。
3. 在高并发情况下,容易出现锁问题。
大aggregate的优点
1. 更好的维护数据完整性
大aggregate的用处
前面总结了大aggregate在维护数据完整性上是有优势的。但上面例子中的数据完整性即Classroom最多有50个物品,我们可以用小aggregate的方式来实现,所以我们倾向使用小aggregate。
如果我们的系统需求是不一样的,比如我们要记录教室中的物品位置,同时要保证相同位置上不能有两个物品(数据完整性!)。那么我们的模型就会发生变化。
@Getter
public class Item {
private ItemId itemId;
private ItemType itemType;
private Position position;
private maintenanceDate;
public void maintain(){
maintenanceDate = DateUtils.now(); // 更新检测日
}
}@Value
public class Position {
private Integer x;
private Integer y;
}当我们要向教室里加物品时,小aggregate的设计就满足不了需求了,于是我们可能不得不启用大aggregate的设计。
public class Classroom {
private ClassroomId classroomId;
private String classRoomNo; // eg: 402
private List- items;
public Item add(Item item) throws ItemLimitExceededException, PositionOccupiedException {
if(items.size() == 50) {
throw new ItemLimitExceededException();
}
if(isOccupied(item.getPosition())) {
throw new PositionOccupiedException();
}
item.add(item);
}
private boolean isOccupied(Position position) {
return items.toStream().map(Item::getPosition)
.anyMatch(p -> p.equals(position));
}
public Item findItem(ItemId itemId){
items.toStream().filter(item -> item.getItemId() == itemId).findFirst().getOrElse( null );
}
}
总结
这次我们讲了一下aggregate的设计策略。讨论了大aggregate的优与劣。这部分的理论主要参考《实践ddd》,作者是提倡使用小aggregate的。个人认为,选择哪个策略归根到底会是两个问题。
1. 权衡数据完整性和抗并发的问题
2. aggregate的非root子entity是否拥有相当多的独立业务逻辑
根据上边的原则可以帮助我们决定aggregate的设计。