关于COVID-19新型冠状病毒,最新提出的人工智能在诊疗中的应用
关于COVID-19新型冠状病毒,最新提出的人工智能在诊疗中的应用论文
本文主要精选了对于COVID-19新型冠状病毒,最新提出的5篇AI技术应用前沿论文。其中前面2篇为采用神经网络模型去辅助医生对于CT图像的感染区域的分析;而后面2篇为采用机器学习结合不同的特征提取算法,去实现进行根据CT图像进行感染的分类预测;最后1篇则是从Computer Audition的场景应用可能性分析,提出通过声音技术对病人或者隔离人员的心理及生理的健康状态进行分析和预测。
文章目录
- 1.VB-Net:利用神经网络,加速对CT图像中的COVID-19肺部感染区域的定量描述
- VB-Net,用于在CT图像上分割肺野内的COVID-19感染区域的分割
- HITL,用于加速对CT图像中的COVID-19肺部感染区域定量的架构
- 2.COVIDX-Net:基于7种不同的DCNN架构提出的用于X-ray图像的冠状病毒(COVID-19)感染的分类预测
- COVIDX-Net的主要流程:
- 3.SVM:使用机器学习,基于CT图像对冠状病毒(COVID-19)感染的分类预测
- 研究过程的概要:
- 4.iSARF:使用感染区域大小感知分类方法,从社区获得性肺炎大规模筛查COVID-19
- CT图像的预处理(preprocess of Lung Infections and Fields):
- 提出的模型管道(Infection Size Distribution and Proposed Size-Aware Method):
- 特定位置的特征提取(Extraction of Location-Specific Features):
- 训练过程(Training Process):
- 5.Computer Audition:概述语音和声音分析在COVID-19临床治疗中可能性的应用
- 潜在的应用案例(Potential Use-cases)
- 风险评估(Risk Assessment)
- 诊断(Diagnosis)
- 病毒传播的可能性监控(Monitoring of Spread)
- 治疗和恢复的监测(Monitoring of Treatment and Recovery)
- 语音和声音的生成(Generation of Speech and Sound)
1.VB-Net:利用神经网络,加速对CT图像中的COVID-19肺部感染区域的定量描述
(Lung Infection Quantification of COVID-19 in CT Images with Deep Learning)
CT成像已成为筛查COVID-19患者和评估COVID-19严重程度的有效工具。 但是,放射科医生缺乏计算机工具来准确地量化COVID-19的严重程度,例如整个肺部的感染百分比。本文提出了一种用于在CT图像上分割肺野内的COVID-19感染区域分割的神经网络VB-Net以及相关的流程架构human-in-the-loop (HITL) , 为准确的细分提供了在整个治疗期间跟踪疾病进展和分析COVID-19的经度变化所必需的定量信息。

VB-Net,用于在CT图像上分割肺野内的COVID-19感染区域的分割
由于CT图像中感染区域的对比度较低,并且不同患者之间的形状和位置都有很大差异,因此从胸部CT扫描划定感染区域非常具有挑战性。 为此,我们开发了一个称为VB-Net的基于DL的网络。
它是将V-Net 14与瓶颈结构15结合在一起的改进型3-D卷积神经网络。 VB-Net包含两条路径(图1)。 第一个是收缩路径,包括下采样和卷积运算以提取全局图像特征。 第二个是扩展路径,包括上采样和卷积运算以集成细粒度图像特征。与V-Net 14相比,VB-Net的速度要快得多,因为瓶颈结构已集成在VB-Net中,如图1所示。瓶颈设计是3层堆叠结构。
这三层使用1×1×1、3×3×3和1×1×1卷积核,其中具有1×1×1核的第一层减少了通道数,并为常规3×3馈送了数据 ×3内核层处理,然后通过另一个1×1×1内核层恢复特征图的通道。 通过减少和组合特征图通道,不仅大大减少了模型尺寸和推断时间,而且通过卷积有效融合了跨通道特征,这使得VB-Net比传统的V-Net更适用于处理大型3D体积数据。

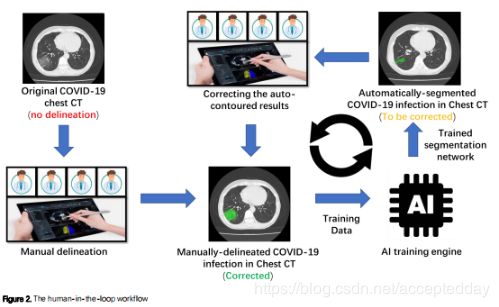
HITL,用于加速对CT图像中的COVID-19肺部感染区域定量的架构
提出的VB-Net需要训练样本,并详细描述每个感染区域。 但是,放射科医生要注释数百个COVID-19 CT扫描是一项劳动密集型工作。 因此,我们采用了HITL策略来迭代更新DL模型。
具体而言,将训练数据分为几批。首先,放射科医生手动绘制最小批次的CT数据。 然后,该批次将分割网络作为初始模型进行训练。 将该初始模型应用于下一批中的感染区域分割,放射科医生手动校正由分割网络提供的分割结果。 然后将这些校正后的分割结果作为新的训练数据输入,并且可以使用增加的训练数据集更新模型。 这样,我们迭代地增加了训练数据集并构建了最终的VB-Net。 在测试阶段,训练有素的分割网络通过神经网络的前向通过,在新的CT扫描上分割感染区域,并且HITL交互作用还为放射科医生在临床应用中提供了可能的干预和人机交互作用。
根据我们的经验,这种HITL训练策略在3〜4次迭代后收敛。 图2说明了提出的HITL培训策略的过程。
论文地址:https://arxiv.org/ftp/arxiv/papers/2003/2003.04655.pdf
2.COVIDX-Net:基于7种不同的DCNN架构提出的用于X-ray图像的冠状病毒(COVID-19)感染的分类预测
(COVIDX-Net: A Framework of Deep Learning Classifiers to Diagnose COVID-19 in X-Ray Images )
本文的目的是介绍一个新的深度学习框架。 即COVIDX-Net,以帮助放射科医生自动诊断X射线图像中的COVID-19。由于缺乏公开的COVID-19数据集,该研究在50例胸部X射线图像上得到了验证,其中25例确诊为阳性。COVIDX-Net包含七种不同的深度卷积神经网络模型体系结构(VGG19,DenseNet201,ResNetV2,InceptionV3,InceptionResNetV2, Xception,MobileNetV2),例如改良的视觉几何组网络(VGG19)和第二版的Google MobileNet。每个深层神经网络模型都能够分析X射线图像的归一化强度,以将患者状态分类为阴性还是阳性COVID-19病例。
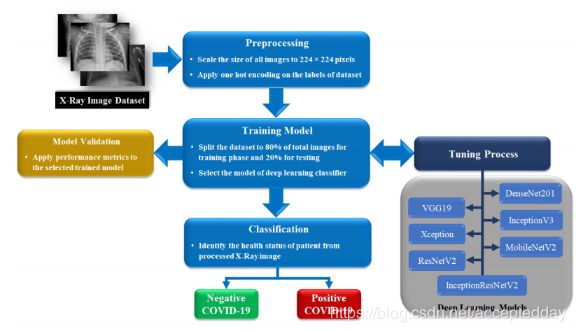
COVIDX-Net的主要流程:
Step#1: Preprocessing
所有X射线图像已收集到一个数据集中,并以224 X 224像素的固定大小进行缩放以适合深度学习pipeline中的进一步处理。 然后,将one-hot编码应用于图像数据的标签,以指示数据集中每个图像的正COVID-19为True或False的情况。
Step#2: Training Model and Validation
为了开始选择并调整七个深度学习模型之一的训练阶段,根据帕累托原理将预处理后的数据集拆分为训练集:验证集=0.8:0.2。再一次,分割80%的数据将用于构建相等的训练和验证集。对深度学习分类器的训练图像数据的随机选择进行子采样,然后应用评估指标以显示验证集上记录的性能。
Step#3: Classification
在提出的框架的最后一步中,将测试数据馈送到已调整的深度学习分类器,以将所有图像的patch分类为以下两种情况之一:确认为阳性COVID-19或正常情况(阴性COVID-19),如图所示。 图1.在工作流结束时,将基于下一部分中描述的指标评估每个深度学习分类器的整体性能分析。
小结:我看了那个github论文使用的数据集,仅有几十张图片,真正是COVID-19的X-ray图像实则更少,采用inception v3这种DCNN的大型神经网络模型,个人觉得这里的实验结果会产生很大的局限性,鲁棒性较差。论文里面给出的效果最好的是采用VGG-19网络作为骨干网络,而且这是完全从图像分类的角度,也不具有医学知识背景。所以这篇论文可以用来自己做做实验用,仅供参考。
论文地址:https://arxiv.org/ftp/arxiv/papers/2003/2003.11055.pdf
3.SVM:使用机器学习,基于CT图像对冠状病毒(COVID-19)感染的分类预测
(Coronavirus (COVID-19) Classification using CT Images by Machine Learning Methods )
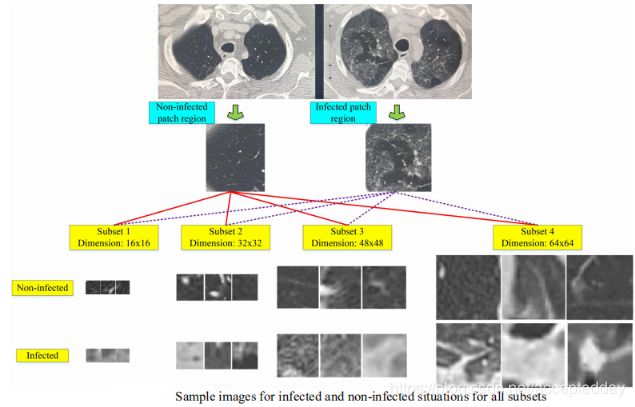
这项研究提出了通过机器学习方法对冠状病毒(COVID-19)进行早期检测的方法, 检测过程在腹部计算机断层扫描(CT)图像上进行。 放射线专家从CT图像中检测到COVID-19表现出与其他病毒性肺炎不同的行为,为了检测COVID-19,本文主要研究了从不同空间尺度(16x16、32x32、48x48、64x64)上以及不同的特征提取算法(灰度共现矩阵(GLCM),局部方向图(LDP),灰度游程长度矩阵(GLRLM),灰度大小区域矩阵(GLSZM)和离散小波变换(DWT)算法)对CT图像的分类。
研究过程的概要:
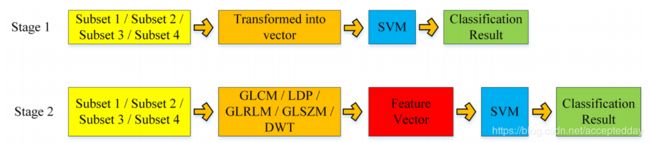
这项研究分两个阶段进行冠状病毒分类。 在第一阶段,分类过程是在四个不同的子集上实施的,而没有特征提取过程。 将子集转换为向量并通过SVM分类。 在第二阶段,五种不同的特征提取方法,例如灰度共生矩阵(GLCM),局部方向性图案(LDP),灰度游程长度矩阵(GLRLM),灰度 级别大小区域矩阵(GLSZM)和离散小波变换(DWT)提取了特征,并通过SVM对特征进行了分类。
在分类过程中,使用了2倍,5倍和10倍交叉验证方法。 获得交叉验证后的平均分类结果。 如图显示了分类过程的两个阶段。
如图所示,CT图像分为32x32大小的色块,GLSZM方法提取CT图像的特征并形成特征向量,该向量通过在训练阶段获得的五个不同的SVM结构进行分类,获得最优的平均分类性能。

论文地址:https://arxiv.org/ftp/arxiv/papers/2003/2003.09424.pdf
4.iSARF:使用感染区域大小感知分类方法,从社区获得性肺炎大规模筛查COVID-19
(Large-Scale Screening of COVID-19 from Community Acquired Pneumonia using Infection Size-Aware Classification )
作为肺炎的一种形式,感染引起一个或两个肺中气囊的炎症,并充满液体或脓液,使患者难以呼吸。因此,从社区获得性肺炎(CAP)中筛查COVID-19对于患者分类,治疗方案设计和随访评估很重要。 在这项研究中,总共1658例COVID-19患者和1027例CAP患者接受了薄层CT检查。
对所有图像进行预处理,以获得感染和肺野的分割,用于提取特定位置的特征。 提出了一种感染大小感知随机森林方法(iSARF),其中将受试者自动分类为具有不同范围感染病变大小的组,然后在每组中随机森林进行分类。实验结果表明,该方法在五重交叉验证下的灵敏度为0.907,特异性为0.833,准确度为0.879。 特别是对于感染范围在0.01%到10%中等范围的病例,相对于比较方法,可以获得较大的性能优势。 Radiomics功能的进一步包含显示出一些改进。 可以预期,我们提出的框架可以帮助临床决策。
CT图像的预处理(preprocess of Lung Infections and Fields):
我们提出,利用疾病特征(即感染部位和传播方式)提取手工特征。 为此,我们自动将感染的肺区域和肺野进行了双边分割。 受感染的肺区域主要与肺炎的表现有关,例如镶嵌体征,GGO,病变相关征象(空气支气管造影)和小叶间隔增厚。 产生的肺野包括左右肺,五个肺叶和十八个肺段。具体来说,采用了基于深度学习的网络VB-Net进行图像分割。 区域分割,如图为例:
VB-Net是一种经过修改的网络,将V-Net与瓶颈层结合在一起,以减少和组合特征图通道。 该网络包括用于提取全局图像特征的收缩路径和用于集成细粒度图像特征的扩展路径。 网络中集成了瓶颈结构,以减少特征图通道的数量,从而加快空间卷积。 如果给出适当的注释作为训练数据,则VB-Net能够对感染的病变和肺野进行分段。 该软件已经在感染和肺野的分割中进行了评估,自动和手动分割之间的Dice相似系数达到92%。 在这项工作中,我们直接使用该软件对受感染的病变和肺野进行分割。

提出的模型管道(Infection Size Distribution and Proposed Size-Aware Method):
图B示出了示意图,其中在每一幅中对所有图像进行了预处理,并且训练了机器学习模型,包括特征提取,选择和疾病分类。 在测试阶段,将对新图像进行预处理,然后模型预测其成为COVID-19或CAP的可能性。
经过上述的训练,发现Volume特征的分类效果最好。本文中,我们提出了一种感染大小感知随机森林(iSARF)方法(图C)。
从所有特征来看,感染大小被用作三级随机森林中的唯一特征,在该森林中形成了决策树,并用于将数据分为4个大小组。 然后在训练过程中为每个大小组构建一组随机森林。在测试阶段,测试数据将通过决策树发送到适当的大小组,然后按以下(相应的)随机森林分类,以进行最终诊断。


特定位置的特征提取(Extraction of Location-Specific Features):
从感染和肺野的CT图像中通过VB-Net自动提取,这些特征由4个类别组成,包括体积,感染病变数,直方图分布和表面积。 详细的功能分配框架如图4所示。
- Volume Feature:我们提取了感染区域的总体积,并计算了整个肺部感染区域的百分比。由于有证据表明COVID-19更有可能在两个肺部发生,因此我们计算了感染的病变差异以及左右肺之间的百分比差异。
- Infected lesion number:COVID-19和CAP之间的另一个影像差异是,大多数COVID-19感染包括多灶性累及的双侧肺,COVID-19通常也集中了受感染的病灶,而CAP的体积小且分布斑驳。 因此,我们分别计算了双边肺,肺叶和肺段感染区域特征的总数。
- Histogram distribution:COVID-19的表现具有其自身的特征,与其他类型的肺炎(例如A型流感病毒性肺炎)不同。 胸部CT的主要发现表明,双侧和周围GGO和巩固是COVID-19的放射学标志。为了提取感染区域的CT强度分布,我们计算了感染区域的直方图特征。根据预设的强度值间隔,我们划分将间隔分成30个相等的bin,并计算每个bin处感染区域中强度级别的频率,以获得频率分布直方图特征。
- Surface area:与CAP相比,已发现COVID-19在后肺和外周肺中占主导地位,并且肺实质最终扩散到中部区域和双侧上叶。 因此,我们构造了感染表面以及肺边界表面。我们进一步计算了每个感染表面顶点到最近的肺边界表面的距离,并将它们分为5个范围,分别为3、6、9、12和15个体素(体素间距为1.5mm)。对于特征,计算到肺壁的每个距离范围内的感染表面顶点的数量。此外,还获得了在每个范围内的感染顶点数量相对于整个感染表面顶点数量的百分比。

训练过程(Training Process):
生成特征后,我们应用机器学习方法选择合适的特征,并从CAP患者中预测出COVID-19患者。 每个折叠的特征选择和预测过程详述如下。
在训练阶段,由于其提供可变的重要性和可解释性的能力,我们使用最小绝对收缩和选择算子(LASSO)来探索临床放射学特征的最佳子集进行分类。之后,将选定的特征分别输入到LR,SVM,NN和提出的方法中,以确定其用于疾病诊断的超参数。 对于LR,我们使用默认的惩罚参数L2(惩罚中使用的范数),将正则化C设置为1。对于SVM,我们使用径向基函数(RBF)核,其正则化C和伽玛参数通过内部确定 5倍网格搜索。 对于NN,我们使用MLP分类器,其隐藏层为100个节点,最大迭代次数为500。对于所提出的方法,每个大小组使用100棵随机森林树,树的最大深度为10,并使用Gini杂质 衡量分割的质量。 然后将这些训练有素的模型应用于新的测试图像,以预测它们在测试阶段针对CAP成为COVID-19的可能性。
为了评估性能,执行了接收器工作特性(ROC)分析。 敏感性评估正确识别的阳性病例与所有阳性病例的比率。 特异性衡量所有真实阴性中正确发现的阴性比率。 曲线下面积(AUC)展示了考虑灵敏度和特异性的分类器能力。 列出了权重最大的功能。 我们进一步研究了有关感染病变大小的结果指标。
论文地址:https://arxiv.org/ftp/arxiv/papers/2003/2003.09860.pdf
5.Computer Audition:概述语音和声音分析在COVID-19临床治疗中可能性的应用
(COVID-19 and Computer Audition: An Overview on What Speech & Sound Analysis Could Contribute in the SARS-CoV-2 Corona Crisis)
在撰写本文时,自三个月前Corona病毒爆发以来,全世界人口正遭受着超过1万例登记的COVID-19疾病流行致死,现在正式称为SARS-CoV-2。在此贡献中,我们概述了计算机语音(CA)的潜力,我们首先调查可以从语音或声音中自动评估哪些类型的相关或上下文重要的现象。 这些包括自动识别和监视呼吸,干咳和湿咳嗽或打喷嚏的声音,感冒下的讲话,进食行为,嗜睡或疼痛等。然后,我们考虑潜在的利用案例。这些包括基于症状的症状及其随时间的发展进行风险评估和诊断,以及监测传播情况,社交距离及其影响,治疗和康复以及患者的健康状况。
潜在的应用案例(Potential Use-cases)
风险评估(Risk Assessment)
旨在通过个人风险评估来预防COVID-19传播。如上所示,可以从声音中自动评估说话者特征(如年龄,性别或健康状况),以提供对个人死亡风险水平的估计。 此外,一个人可以在讲话时监视自己或周围的其他人是否戴着口罩,对一个人周围的扬声器进行计数,并确定这些扬声器及其距离,以提供实时的环境风险评估和信息丰富的警告。
诊断(Diagnosis)
据作者所知,尚无研究调查来自COVID-19患者与高等对照组数据的音频,包括患有流感或感冒和健康个体的此类数据。 不幸的是,与“正常”患者相比,COVID-19患者的咳嗽和打喷嚏与人类的感知没有显着差异。因此总体而言,尚不清楚是否可以直接从患者的简短音频样本中进行诊断。
【表注:反映在音频信号中(参见上表),并对音频源进行“补偿”,即 例如,确定哪些症状来自哪个(人类)个体。 同样,AI可以提供公共空间,以检测潜在的危险环境,这些环境过于拥挤,个体之间的距离不足,并在人群中发现可能受COVID-19影响的对象,以及这些是否其他人在讲话时戴着防护口罩。】

我们认为,随着时间推移症状的直方图及其发作似乎很有希望。 表2通过从机器学习的角度对每种症状或“特征”进行粗略的三元量化,以定性的方式形象化了这个概念。 如上所述,表中的每个症状都可以(已经)通过智能音频传感器自动进行评估。 在诸如智能电话或智能手表,具有音频功能的智能家庭设备或通过电话服务等合适的个人应用程序中,随着时间的推移,人们可以收集症状的频率,并从产生的直方图区分出成功率很高 。通过适当的AI,可以为用户提供其症状代表COVID-19的可能性。
病毒传播的可能性监控(Monitoring of Spread)
除了使用基于智能手机的调查和AI方法来监视病毒传播的想法,人们还可以使用CA通过电话或其他口头交谈进行音频分析。如上表所示,人工智能可以监视口语对话并筛选感冒或其他症状下的语音。连同智能手机的GPS坐标或来自该小区的呼叫起源的知识边缘,人们可以建立实时分布图。
个人感觉这一条暂时不具有可行性,我们的手机不可能都配备CA软件,用于未知感染社会群体的语音监测根本不可行,这种情况暂时只适用于对潜在的隔离感染者实用监测。
治疗和恢复的监测(Monitoring of Treatment and Recovery)
在住院或其他形式的治疗和康复期间,CA可以监控进展情况,例如通过更新症状的直方图。 另外,可以如上所述在社会疏远情况下类似于单独监测的情况来监测患者的健康。 这可能包括对他们的情绪,饮食习惯,疲劳或疼痛的分析等。
语音和声音的生成(Generation of Speech and Sound)
到目前为止,虽然我们完全专注于音频分析,但仍然需要指出的是,在COVID-19场景中,AI可能还会有一些用例来生成音频。语音转换和合成可以例如帮助患有COVID-19症状的人减轻与他人的交谈。在这种情况下,AI算法可以填补由咳嗽声引起的间隙,增强遭受疼痛或疲劳感的声音,并进一步增强声音。例如,通过生成对抗网络。
论文地址:https://arxiv.org/pdf/2003.11117.pdf