nifi 爬虫初尝试 网络抓取数据存入mysql数据库
从指定的网站读取内容,将内容转为json,将json转为sql,然后插入到数据库
1、读取网站内容, ExecuteScript 处理器,脚本语言 grrovy,jsoup做解析网页信息,提取公司门户网站的所有的新闻
/usr/nifi/jars/jsoup-1.12.1.jar,
脚本代码如下:
import groovy.json.JsonBuilder
import org.jsoup.Jsoup
import org.jsoup.nodes.Document
import org.jsoup.nodes.Element
import org.jsoup.select.Elements
final String WEB_URL = "http://.." //注释掉网站地址信息
Document doc = Jsoup.connect(WEB_URL+"/html/cn/cn_newcenter/cn_newcenter_gsxw/index.html").get();
//println(doc.title());
Elements eltes = doc.select(".leftsidebar > .tit > a");
eltes.each {Element element -> println(element.text())}
for (Element headline : eltes) {
//获取新闻的二级页面
String url = headline.attr("href");
//打开新闻二级页面
Document doc1 = Jsoup.connect(WEB_URL+url).get();
//println("二级页面地址"+WEB_URL+url)
Elements pageElets = doc1.select(".page > script");
if (pageElets!=null && !pageElets.isEmpty()){
def pageStr = pageElets.get(0).html()
def match = "\\d,\\d"
def results = (pageStr =~ /$match/)[0].toString()
if (results.find()){
def pagenumber = results.split(",")
for(int i=Integer.parseInt(pagenumber[1]);i<=Integer.parseInt(pagenumber[0]);i++){
String pageHtml = 'index_';
if(i!=1){
pageHtml+=i
}
pageHtml+='.html'
def pageUrl
if(i!=1){
pageUrl = (WEB_URL+url).replace('index.html',pageHtml);
}else{
pageUrl = WEB_URL+url
}
//读取每页新闻的连接 读取内容
Document doc3 = Jsoup.connect(pageUrl).get();
Elements eles3 = doc3.select(".newribox >ul > li > a")
eles3.each {Element e ->
def title = e.text();
def contentUrl = WEB_URL+e.attr("href")
//println('连接'+e.attr("href"))
//println('标题'+e.text())
//读取文章类容
try{
Document doc4 = Jsoup.connect(contentUrl).get();
Elements elements = doc4.select(".newsmore");
def content = elements.text();
def date = doc4.select(".sumain > .newsdiv >p").get(0).text();
//println("文章内容:"+content)
// def map = [title:title,url:contentUrl,content:content,date:date]
def ruuid = UUID.randomUUID().toString()
def jsonstr = '{"title":"'+title+'",' +'"url":"'+contentUrl+'",'+'"id":"'+ruuid+'",'+'"content":"'+content+'",'+'"date":"'+date+'"}'
flowFile = session.create()
flowFile = session.write(flowFile,
{ inputStream, outputStream ->
// Select/project cols
outputStream.write(jsonstr.getBytes('UTF-8'))
} as StreamCallback)
session.transfer(flowFile, REL_SUCCESS)
}catch (Exception exception){
}
Thread.sleep(1000)
}
}
}
}
}News newa = new News(title:title,url:contentUrl,content:content,date:date)
flowFile = session.create()
session.putAttribute(flowFile, 'filename',title)
session.putAttribute(flowFile,'data',new JsonBuilder(newa).toPrettyString())
session.putAttribute(flowFile, 'myAttr', 'myValue')
之前的写法,导致属性一直没有生效,flowFile 引用的还是老对象,看nifi的原代码如下,所以用putAttribute 必须要重新引用
nifi对与putAttribute代码如下:
public MockFlowFile putAttribute(FlowFile flowFile, String attrName, String attrValue) {
FlowFile flowFile = this.validateState(flowFile);
if(attrName != null && attrValue != null && flowFile != null) {
if(!(flowFile instanceof MockFlowFile)) {
throw new IllegalArgumentException("Cannot update attributes of a flow file that I did not create");
} else {
if("uuid".equals(attrName)) {
Assert.fail("Should not be attempting to set FlowFile UUID via putAttribute. This will be ignored in production");
}
MockFlowFile mock = (MockFlowFile)flowFile;
MockFlowFile newFlowFile = new MockFlowFile(mock.getId(), flowFile);
this.currentVersions.put(Long.valueOf(newFlowFile.getId()), newFlowFile);
Map attrs = new HashMap();
attrs.put(attrName, attrValue);
newFlowFile.putAttributes(attrs);
return newFlowFile;
}
} else {
throw new IllegalArgumentException("argument cannot be null");
}
}
ExecuteScript 配置:

4、调用组件将json转sql,用到组件 ConvertJSONToSQL

5.putsql,将sql插入到数据库
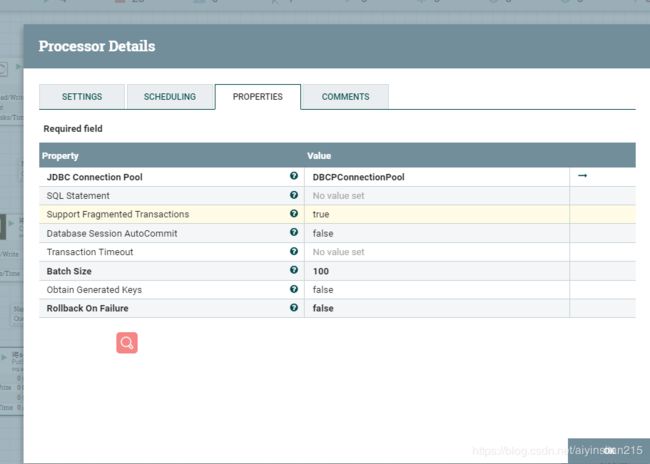
6、流程图如下
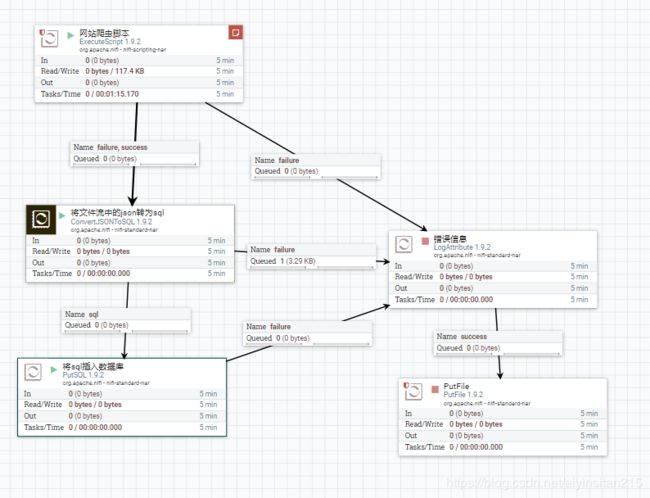
实现了爬虫的企业网站信息数据,存入了mysql数据库,基本上无需代码编写
