更好阅读,请移步这里
聊之前
最近暑期实习招聘已经开始,个人目前参加了阿里的内推及腾讯和百度的实习生招聘,在此总结一下
一是备忘、总结提升,二是希望给大家一些参考
其他面试及基础相关可以参考其他博文:
- Questions of FE
- Web basis summary
- FE knowledge fragment
每位面试官的面试时间基本都在 40-80 分钟,下面先简要介绍各个面试流程,问题详情见具体公司分类
腾讯内推&校招 offer got
首先腾讯分为三面,都为技术面:
- 初试一个面试官
复试两个面试官,包括电话远程 online coding
(我也不知道为什么几天内三个面试官面我,只算两个面试过程 ヾ(´A`)ノ゚)终面一位面试官
这位应该是大 boss ,他说并不是前端开发的,面试的问题也不会很深入,主要看个人对这个领域的想法以及对常见问题在前端领域的解决思路,不按套路出牌,emmm 感觉回答的不理想
类似这种问题:- 说说最能体现你能力的工作
网络安全的实现
如何检测恶意脚本
如何屏蔽
...
腾讯二面 & online coding
腾讯的远程 online coding 时间较长,大概一个多小时,不仅要按要求编程,也要口述思路以及关键点,过程类似压力面,面试官说完题目要求会给你思考及coding 时间,他可以远程看到面试者的 coding 状态,主要考察应变能力,思维活跃度,编码习惯,调试能力,以及测试方法,本人在此过程中没有太注意测试过程,导致对于特殊情况考虑不全面,测试样例不完善,望小伙伴们注意 ヾ(´A`)ノ゚,不过,在口述代码时发现也可以自己提出来需要完善的地方。
coding 为一到两题,后续问题都是围绕它结合实际应用进行拓展,主要考察是否能灵活运用以及相似的思路转换,当时面试时间太长以及基础知识较差,进制转换,存储那些个基础被小学老师收回,一连串的炮轰简直爽歪歪,个人表示此过程自己的表现较差,也要重视基础基础啊老铁们 ( ̄_ ̄ )
经历了腾讯云的四个面试官,以及其他部门一个面试官的酱油面,腾讯的技术面试官普遍语速较快,思路转换很快,要跟上面试官的节奏,聊到自己比较熟悉的可以多说几句,他们也会顺着你回答的内容进行深入,也会引导面试者的回答方向,如果不太熟尽量坦白一些,不懂装懂很容易 gg
才接到通知另加两轮面试委员会现场技术面,简直爽歪歪 ヾ(´A`)ノ
腾讯校招现场
一面
面试官很 nice,基本看着简历问的,话题围绕项目(项目隔得时间太久,内心宁愿粗暴的技术面),基本为大致的了解,包括平时的学习习惯和关注的技术发展- 问到了 ES5 ES6 ES7 甚至 ES8
- 项目中用过vue, 就问了 react vue 相关
- 实习中的工作方式,如何处理设计师的设计稿,回答了包括考虑响应式布局的常用方案
sass--定义function,使用rem
问是否有其他负面作用
想到了页面闪烁,由于初始化时需要计算页面尺寸,可能有缩放
如何避免:
doc.addEventListener('DOMContentLoaded‘', function(e) { }, false);媒体查询
- 移动端和pc端的工作
二面
面试官不是前端的,所以没有问很深入的问题,主要模拟实际场景考察实现思路以及前后端的方案,后端没说出什么,基本上只是就前端层面进行了描述,包括实现思路、需要注意的问题、以及性能和安全方面的考虑- 前端安全
- 场景考察
- 直播弹幕处理
- 后端返回大量数据且包含运算,如何实时显示
- 。。。记不清了
- HR 面
- 介绍经历
- 家庭情况
- 职业规划
- 对腾讯的认识及与其他实习单位对比
- 对比实习过的企业
- 是否还报了其他企业
- 男朋友工作找的怎么样了
阿里内推 二面 卒
我投的是蚂蚁金服的前端开发,投过简历硬生生排队等了12天,还被内推人提前告知蚂蚁的前端很严格 ( ̄_ ̄ )
阿里分为在线测试,初试 ......
首先是在线测试
投完简历后官网会有相关在线测试题
阿里前端的在线测试只有一道coding 题,限时 30 分,由于初次在线答题,看着倒计时紧张的思路不通,未能准确理解题意,但实际题目并不难,考察使用原生 js 实现类似css 的层级选择器的功能,具体题目记不太清,将仅存的记忆写了下来并附上个人实现,详情见本文后部分- 一面
- 二面
挂掉了。。。
baidu offer got
百度投的是核心搜索部门,但一面后估计不合适,没有了消息,后简历转到百度金融
一面
面试官语速很快,一般不给太多思考时间--------感觉自己说话都打着节拍 ( ̄_ ̄ )
二面
面试官很和蔼,是唯一一个认真看了我博客的面试官,很荣幸,也很紧张
基本偏向基础
但由于没安排好时间,面试时在户外,听不太清面试官的问题,在此提醒各位小伙伴提前选好面试场地,避免环境影响三面
同样和蔼的面试官,开始考察基础知识,编译原理,网络协议等基础,后面考察个人素质,后续更注重个人经历,包括如何学习,找实习,实习中遇到的问题及如何解决,最骄傲的事情等等
关于结尾
百度 & 阿里面试结束后都有问:你觉得在面试过程中有什么没问到,但自己掌握比较好的技能么
面阿里时,头脑发晕,回答:没有,我感觉您面的很专业,问的知识点都是比较核心的 ( ̄_ ̄ )
百度经验: 回答自己掌握还比较好的知识后,面试官真的会问很多问题(菜鸟可以参考以上做法),如果面试官面试的较偏,倒可以补充- 有什么要问的
腾讯二面教训
我:是否有导师带,实习的大致安排以及部门业务等
效果 差
面试官曰:
你那么关系有没有导师的问题,但学习中最重要的是靠自己,导师并不是负责回答你所有问题的百度经验
我:部门是否有定期交流分享的机会;工作中是按照职位还是业务部门划分,如何交流;偏向页面还是业务逻辑
个人在自学过程中发现前端体系太大,不知对于前端学习,您有什么建议么
面试官:很多前端初学者都有类似的困惑,你最好自己从头开始做一个项目,不管是自己瞎想的还是模仿的,在项目过程中去发现需要学习什么技术,在遇到问题的时候才知道去哪个方向发展和思考,只有在项目中才能持续的学习和提高,前端知识很碎,没有项目很难有一连串的经历
总体
总体来说,面试中有按照面试题出的,也有直接聊的,一般也会结合实际工作中会遇到的场景以及技术中的一些坑,回答时结合自己的项目经验会更好,大厂的面试官更侧重于面试者对深层原理的理解,对于实习生来说一般面基础,如果有深查原理的习惯,个人的可塑造性也会较高
三厂体验对比:
- 腾讯阿里面试官一面开始都比较侧重实践,如果简历上有过实践项目和实习经历,会问更实际的问题,构造场景让解答
协议都会问到
相对来说,百度更多基础知识点,更多考察对更基本的知识掌握,不限于前端,还包括组成原理和编译原理的一些知识,当然前端偏多(比如选取一个class 标签元素有几种方式等小细节的问题来考察,细到要把每个表达说完整,把每个单词拼出来)
阿里腾讯更侧重应用中的注意事项(如:IE 和其他浏览器中的事件处理机制)不太揪细节
三厂都有问到算法,腾讯相对更注重对算法和逻辑,对面试者基础知识要求较高,甚至涉及更底层的。
另两厂对算法,数据结构的要求都是了解阶段
以下为面试中的一些知识点以及个人的一些补充,敲黑板啦啦啦
1. Tencent
1.1. js 的事件机制
事件阶段
一般的,事件分为三个阶段:捕获阶段、目标阶段和冒泡阶段。
捕获阶段(Capture Phase)
- 事件的第一个阶段是捕获阶段。事件从文档的根节点流向目标对象节点。途中经过各个层次的DOM节点,并在各节点上触发捕获事件,直到到达事件的目标节点。捕获阶段的主要任务是建立传播路径,在冒泡阶段,事件会通过这个路径回溯到文档跟节点。
或这样描述:
任何事件产生时,如点击一个按钮,将从最顶端的容器开始(一般是html的根节点)。浏览器会向下遍历DOM树直到找到触发事件的元素,一旦浏览器找到该元素,事件流就进入事件目标阶段
目标阶段(Target Phase)
- 当事件到达目标节点的,事件就进入了目标阶段。事件在目标节点上被触发,然后会逆向回流,直到传播至最外层的文档节点。
- 冒泡阶段(Bubble Phase)
- 事件在目标元素上触发后,并不在这个元素上终止。它会随着DOM树一层层向上冒泡,回溯到根节点。
- 冒泡过程非常有用。它将我们从对特定元素的事件监听中释放出来,如果没有事件冒泡,我们需要监听很多不同的元素来确保捕获到想要的事件
事件处理程序
DOM0 级事件处理程序
var btn5 = document.getElementById('btn5'); btn5.onclick=function(){ console.log(this.id);//btn5 };基于 DOM0 的事件,对于同一个 dom 节点而言,只能注册一个,后边注册的 同种事件 会覆盖之前注册的。
利用这个原理我们可以解除事件,btn5.onclick=null;其中this就是绑定事件的那个元素;以这种方式添加的事件处理程序会在事件流的冒泡阶段被处理;
- DOM2 级事件处理程序
- DOM2支持同一dom元素注册多个同种事件,事件发生的顺序按照添加的顺序依次触发(IE是相反的)。
DOM2事件通过
addEventListener和removeEventListener管理// addEventListener(eventName,handlers,boolean);removeEventListener() // 两个方法都一样接收三个参数,第一个是要处理的事件名,第二个是事件处理程序, // 第三个值为false时表示在事件冒泡阶段调用事件处理程序,一般建议在冒泡阶段使用, // 特殊情况才在捕获阶段; // 注意:通过addEventListener()添加的事件处理程序只能用removeEventListener()来移除 // 并且移除时传入的参数必须与添加时传入的参数一样;比如 var btn2 = document.getElementById('btn2'); var handlers = function () { console.log(this.id); }; btn2.addEventListener('click',handlers,false); btn2.removeEventListener('click',handlers.false);ie 事件处理程序
//IE事件处理程序(IE和Opera支持) /* IE用了attachEvent(),detachEvent(),接收两个参数,事件名称和事件处理程序, * 通过attachEvent()添加的事件处理程序都会被添加到冒泡阶段,所以平时为了兼容更多的浏览器最好将事件添加到事件冒泡阶段,IE8及以前只支持事件冒泡; */ var btn3 = document.getElementById('btn3'); var handlers2=function(){ console.log(this===window); // true,注意attachEvent()添加的事件处理程序运行在全局作用域; }; btn3.attachEvent('onclick',handlers2);
---ie 与其他浏览器的区别
总结
DOM事件模型中的事件对象常用属性:
- type用于获取事件类型
- target获取事件目标
- stopPropagation()阻止事件冒泡
- preventDefault()阻止事件默认行为
- 判断加载状态 —— onload 事件
IE事件模型中的事件对象常用属性:
- type用于获取事件类型
- srcElement获取事件目标
- cancelBubble 阻止事件冒泡
- returnValue 阻止事件默认行为
通过 readystate 属性值判断何时方法下载完毕可用
readystate共有以下几个值:- uninitialized: 对象存在但未初始化;
- loading:对象正在加载;
- loaded:对象数据加载完毕;
- interactive:可以操作对象了,但还没加载完毕;
- complete:加载完毕。
注意上面5个值并不一定每个事件都全包含,并且不一定是什么顺序。
Document.readyState 属性
一个文档的 readyState 可以是以下之一:loading / 加载
document 仍在加载。interactive / 互动
文档已经完成加载,文档已被解析,但是诸如图像,样式表和框架之类的子资源仍在加载。complete / 完成
T文档和所有子资源已完成加载。状态表示 load 事件即将被触发。
当这个属性的值变化时,document 对象上的readystatechange 事件将被触发。
事件对象
IE
IE中事件对象是作为全局对象window.event存在的Firefox
Firefox中则是做为句柄( handler )的第一个参数传入通用
var evt = window.event || arguments[0];

事件监听
Chrome、FireFox、Opera、Safari、IE9.0及其以上版本
js addEventListener(eventName,handler,boolean); removeEventListener() /* 两个方法都一样接收三个参数, * 事件名 * 事件处理程序 * boolean false时表示在事件冒泡阶段调用事件处理程序,一般建议在冒泡阶段使用 */
IE8.0及其以下版本
js element.attachEvent(type, handler); element.detachEvent(type, handler); /* element 要绑定事件的对象,html 节点 * type 事件类型 +'on' 如: "onclick, onmouseover" * listener 事件处理程序(只写函数名,不带括号) */早期浏览器
obj['on' + type] = handler
阻止冒泡
event.stopPropagationevent.cancelBubble = true //IE
阻止默认事件
event.preventDefault()event.returnValue = false //IE
---通用的事件监听器
// event(事件)工具集,来源:github.com/markyun
markyun.Event = {
// 页面加载完成后
readyEvent: function (fn) {
if (fn == null) {
fn = document;
}
var oldonload = window.onload;
if (typeof window.onload != 'function') {
window.onload = fn;
} else {
window.onload = function () {
oldonload();
fn();
};
}
},
// 视能力分别使用dom0||dom2||IE方式 来绑定事件
// 参数: 操作的元素,事件名称 ,事件处理程序
addEvent: function (element, type, handler) {
if (element.addEventListener) {
//事件类型、需要执行的函数、是否捕捉
element.addEventListener(type, handler, false);
} else if (element.attachEvent) {
element.attachEvent('on' + type, function () {
handler.call(element);
});
} else {
element['on' + type] = handler;
}
},
// 移除事件
removeEvent: function (element, type, handler) {
if (element.removeEnentListener) {
element.removeEnentListener(type, handler, false);
} else if (element.detachEvent) {
element.detachEvent('on' + type, handler);
} else {
element['on' + type] = null;
}
},
// 阻止事件 (主要是事件冒泡,因为IE不支持事件捕获)
stopPropagation: function (ev) {
if (ev.stopPropagation) {
ev.stopPropagation();
} else {
ev.cancelBubble = true;
}
},
// 取消事件的默认行为
preventDefault: function (event) {
if (event.preventDefault) {
event.preventDefault();
} else {
event.returnValue = false;
}
},
// 获取事件目标
getTarget: function (event) {
return event.target || event.srcElement;
},
// 获取event对象的引用,取到事件的所有信息,确保随时能使用event;
getEvent: function (e) {
var ev = e || window.event;
if (!ev) {
var c = this.getEvent.caller;
while (c) {
ev = c.arguments[0];
if (ev && Event == ev.constructor) {
break;
}
c = c.caller;
}
}
return ev;
}
};1.2. vue
---Vue 生命周期
---双向绑定原理 & 如何实现
---vuex 原理
---vue 数据更新后执行
1.3. 跨域
什么叫跨域
方案
1.4. 安全 && 怎样预防
1.5. session & cookie
1.6. 本地存储
1.7. 浏览器缓存
1.8. 页面从输入URL 到加载过程
1.9. HTTP
---content-type
application/x-www-form-urlencoded
最常见的 POST 提交数据的方式了。浏览器的原生 form 表单,如果不设置 enctype 属性,那么最终就会以 application/x-www-form-urlencoded方式提交数据。
传递的key/val会经过URL转码,所以如果传递的参数存在中文或者特殊字符需要注意。
//例子 //b=曹,a=1 POST HTTP/1.1(CRLF) Host: www.example.com(CRLF) Content-Type: application/x-www-form-urlencoded(CRLF) Cache-Control: no-cache(CRLF) (CRLF) b=%E6%9B%B9&a=1(CRLF) //这里b参数的值"曹"因为URL转码变成其他的字符串了multipart/form-data
常见的 POST 数据提交的方式。我们使用表单上传文件时,必须让 form 的 enctyped 等于这个值
并且Http协议会使用boundary来分割上传的参数text/xml
POST http://www.example.com HTTP/1.1(CRLF) Content-Type: text/xml(CRLF) (CRLF)123 homeway 22 application/json
用来告诉服务端消息主体是序列化后的 JSON 字符串
//例子 //传递json POST HTTP/1.1(CRLF) Host: www.example.com(CRLF) Content-Type: application/json(CRLF) Cache-Control: no-cache(CRLF) Content-Length: 24(CRLF) (CRLF) { "a":1, "b":"hello" }
(CRLF)指 \r\n
参考: HTTP常见Content-Type比较
1.10. get & post
1.11. TCP & UDP & 握手
---TCP (Transmission Control Protocol)
两个序号和三个标志位:
- 序号:seq序号,占32位,用来标识从TCP源端向目的端发送的字节流,发起方发送数据时对此进行标记。
- 确认序号:ack序号,占32位,只有ACK标志位为1时,确认序号字段才有效,ack=seq+1。
标志位:共6个,即URG、ACK、PSH、RST、SYN、FIN等,具体含义如下:
- URG:紧急指针(urgent poin* 有效。
- ACK:acknowledgement 确认序号有效。
- PSH:接收方应该尽快将这个报文交给应用层。
- RST:reset 重置连接。
- SYN:synchronous 建立联机,发起一个新连接。
- FIN:finish 释放一个连接。
需要注意的是:
- 不要将确认序号ack与标志位中的ACK搞混了。
- 确认方ack=发起方req+1,两端配对。

- 第一次握手:
Client将标志位SYN置为1,随机产生一个值 seq=J,并将该数据包发送给Server
Client进入SYN_SENT状态,等待Server确认。 - 第二次握手:
Server收到数据包后由标志位SYN=1知道Client请求建立连接,Server将标志位SYN和ACK都置为1,ack=J+1,随机产生一个值seq=K,并将该数据包发送给Client以确认连接请求,Server进入SYN_RCVD状态。 - 第三次握手:
Client收到确认后,检查ack是否为J+1,ACK是否为1,如果正确则将标志位ACK置为1,ack=K+1,并将该数据包发送给Server,Server检查ack是否为K+1,ACK是否为1,如果正确则连接建立成功,Client和Server进入ESTABLISHED状态,完成三次握手,随后Client与Server之间可以开始传输数据了
为什么需要确认

---四次挥手
由于TCP连接时全双工的,因此,每个方向都必须要单独进行关闭,这一原则是当一方完成数据发送任务后,发送一个FIN来终止这一方向的连接,收到一个FIN只是意味着这一方向上没有数据流动了,即不会再收到数据了,但是在这个TCP连接上仍然能够发送数据,直到这一方向也发送了FIN
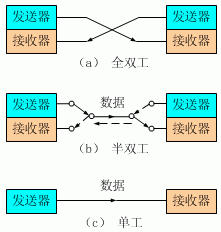

首先进行关闭的一方将执行主动关闭,而另一方则执行被动关闭,上图描述的即是如此。
- 第一次挥手:
Client发送一个FIN,用来关闭Client到Server的数据传送,Client进入FIN_WAIT_1状态。 - 第二次挥手:
Server收到FIN后,发送一个ACK给Client,确认序号为收到序号+1(与SYN相同,一个FIN占用一个序号),Server进入CLOSE_WAIT状态。 - 第三次挥手:
Server发送一个FIN,用来关闭Server到Client的数据传送,Server进入LAST_ACK状态。 - 第四次挥手:
Client收到FIN后,Client进入TIME_WAIT状态,接着发送一个ACK给Server,确认序号为收到序号+1,Server进入CLOSED状态,完成四次挥手。
为什么TIME_WAIT状态需要经过2MSL(最大报文段生存时间)才能返回到CLOSE状态?
- 可靠的实现 TCP 全双工连接的终止
- 允许老的重复分节在网络中消失

MSL是Maximum Segment Lifetime英文的缩写,中文可以译为“报文最大生存时间”,他是任何报文在网络上存在的最长时间,超过这个时间报文将被丢弃,RFC 793中规定MSL为2分钟,实际应用中常用的是30秒,1分钟和2分钟等。2MSL即两倍的MSL,TCP的TIME_WAIT状态也称为2MSL等待状态
为什么连接的时候是三次握手,关闭的时候却是四次握手?
- 因为当Server端收到Client端的SYN连接请求报文后,可以直接发送SYN+ACK报文。其中ACK报文是用来应答的,SYN报文是用来同步的。但是关闭连接时
- 当Server端收到FIN报文时,很可能并不会立即关闭SOCKET,所以只能先回复一个ACK报文,告诉Client端,"你发的FIN报文我收到了"。只有等到我Server端所有的报文都发送完了,我才能发送FIN报文,因此不能一起发送。故需要四步握手。
参考: TCP三次握手详解及释放连接过程
1.12. HTTP 加密
---加密对象
对于HTTP协议来说,加密的对象有以下两个:
- 对通信的加密:
HTTP中没有加密功能,但是可以通过和SSL(Secure Socket Layer,安全套接层)组合使用,加密通信内容。使用SSL建立安全通信线路后,就可以在这条线路上进行HTTP通信了。与SSL组合使用的HTTP被称为HTTPS(HTTP Secure,超文本传输安全协议)。 - 对通信内容本身进行加密
即对HTTP报文里所包含的内容进行加密。这样,首先客户端要先对报文进行加密,然后再发给服务器。服务器在接受到请求时,需要对报文进行解密,再处理报文。该方式不同于SSL将整个通信线路进行加密处理,所以内容仍然有被篡改的风险。- A、任何人都可以发起请求
HTTP协议中,并未有确认通信方这一步骤,所以,任何人都可以发送请求,而服务器在接受到任何请求时,都会做出相应的响应。解决方案:
查明对手的证书
虽然HTTP不能确认通信方,但SSL是可以的。SSL不仅提供了加密处理,还使用了"证书"的手段,可用于确认通信方。证书是由值得信赖的第三方机构颁布,可用于确定证明服务器和客户端是实际存在的。所以,只要能确认通信方持有的证书,即可判断通信方的真实意图。
B、无法判断报文是否完整(报文可能已遭篡改)
HTTP协议无法判断报文是否被篡改,在请求或者响应发出后,在对方接收之前,即使请求或者响应遭到篡改是无法得知的。防止篡改:
常用的,确定报文完整性方法:MD5、SHA-1 等 散列值校验方法,以及用来确认文件的数字签名方法。但是,使用这些方法,也无法百分百确保结果正确,因为MD5本身被修改的话,用户是没办法意识到得。
- A、任何人都可以发起请求
POST 用户安全登陆
在关系到用户隐私的时候,要时刻遵循两个原则:- 任何应用程序都不能在本地存储与安全相关的用户信息
- 任何应用程序在向服务器传递数据的时候,都不能直接传递与安全相关的用户信息。
要想让用户信息安全,就必须对其进行加密,让别人即便是拿到了安全信息,摆在眼前的也是一串乱码,没有半点用处
MD5是一种常用的加密方法,它是一种散列函数,利用MD5对用户信息进行加密,会增加用户信息安全性。
网上有关于MD5的第三方框架Category
利用这个第三方框架可以实现对密码进行MD5加密
+随机乱码字符防止被破解
---加密算法
对称加密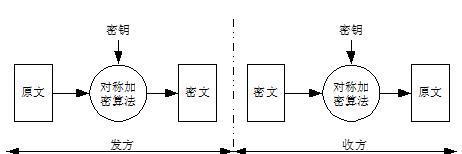
非对称加密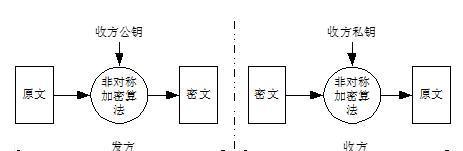
---HTTPS 加密原理
HTTPS简介
HTTPS其实是有两部分组成:HTTP + SSL / TLS,也就是在HTTP上又加了一层处理加密信息的模块。服务端和客户端的信息传输都会通过TLS进行加密,所以传输的数据都是加密后的数据
SSL协议是通过非对称密钥机制保证双方身份认证,并完成建立连接,在实际数据通信时通过对称密钥机制保障数据安全性
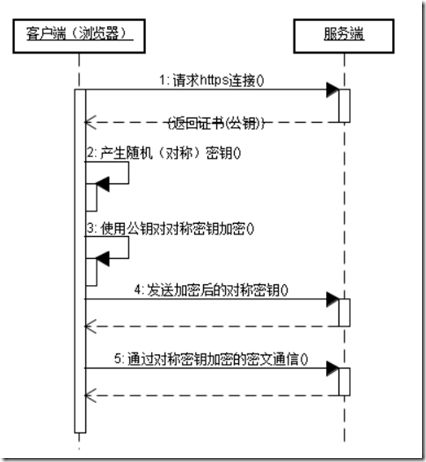
服务器 用RSA生成公钥和私钥
把公钥放在证书里发送给客户端,私钥自己保存
客户端首先向一个权威的服务器检查证书的合法性,如果证书合法,客户端产生一段随机数,这个随机数就作为通信的密钥,我们称之为对称密钥,用公钥加密这段随机数,然后发送到服务器
服务器用密钥解密获取对称密钥,然后,双方就已对称密钥进行加密解密通信了
HTTPS 在传输数据之前需要客户端(浏览器)与服务端(网站)之间进行一次握手,在握手过程中将确立双方加密传输数据的密码信息。TLS/SSL 协议不仅仅是一套加密传输的协议,更是一件经过艺术家精心设计的艺术品,TLS/SSL 中使用了非对称加密,对称加密以及 HASH 算法。握手过程的具体描述如下:
- 浏览器将自己支持的一套加密规则发送给网站。
- 网站从中选出一组加密算法与HASH算法,并将自己的身份信息以证书的形式发回给浏览器。证书里面包含了网站地址,加密公钥,以及证书的颁发机构等信息。
浏览器获得网站证书之后浏览器要做以下工作:
a) 验证证书的合法性(颁发证书的机构是否合法,证书中包含的网站地址是否与正在访问的地址一致等),如果证书受信任,则浏览器栏里面会显示一个小锁头,否则会给出证书不受信的提示。
b) 如果证书受信任,或者是用户接受了不受信的证书,浏览器会生成一串随机数的密码,并用证书中提供的公钥加密。
c) 使用约定好的HASH算法计算握手消息,并使用生成的随机数对消息进行加密,最后将之前生成的所有信息发送给网站。网站接收浏览器发来的数据之后要做以下的操作:
a) 使用自己的私钥将信息解密取出密码,使用密码解密浏览器发来的握手消息,并验证HASH是否与浏览器发来的一致。
b) 使用密码加密一段握手消息,发送给浏览器。浏览器解密并计算握手消息的HASH,如果与服务端发来的HASH一致,此时握手过程结束,之后所有的通信数据将由之前浏览器生成的随机密码并利用对称加密算法进行加密。
参考:图解HTTPS
如何保证 HTTP 传输安全性
重要的数据,要加密
比如用户名密码(如果简单的md5,是可以暴力破解),常见的是 md5(不可逆),aes(可逆),自由组合,还可以加一些特殊字符
举例:
username = aes(username), pwd = MD5(pwd + username)非重要数据,要签名
签名的目的是为了防止篡改,比如
http://www.xxx.com/getnews?id=1,获取id为1的新闻,如果不签名那么通过id=2,就可以获取2的内容等等。怎样签名呢?通常使用sign,比如原链接请求的时候加一个 sign 参数,sign=md5(id=1),服务器接受到请求,验证sign是否等于 md5(id=1) ,如果等于说明正常请求。
这会有个弊端,假如规则被发现,那么就会被伪造,所以适当复杂一些,还是能够提高安全性的。
登录态怎么做
http是无状态的,也就是服务器没法自己判断两个请求是否有联系,那么登录之后,以后的接口怎么判定是否登录呢
简单的做法,在数据库中存一个token字段(名字随意),当用户调用登陆接口成功的时候,就将该字段设一个值,(比如aes(过期时间)),同时返回给前端,以后每次前端请求带上该值,服务器首先校验是否过期,其次校验是否正确,不通过就让其登陆。(redis 做这个很方便哦,key有过期时间)
来自:如何保证http传输安全性
1.13. 排序:冒泡,选择,快速
1.14. 数据库
---触发器
一种特殊的存储过程,存储过程一般通过定义的名字直接调用,而触发器是通过增、删、改进行触发执行的。会在事件发生时自动强制执行
触发器是一种特殊的存储过程,主要是通过事件来触发而被执行的。它可以强化约束,来维护数据的完整性和一致性,可以跟踪数据库内的操作从而不允许未经许可的更新和变化。可以联级运算。如,某表上的触发器上包含对另一个表的数据操作,而该操作又会导致该表触发器被触发。
---事务 & 锁
事务
就是被绑定在一起作为一个逻辑工作单元的SQL语句分组,如果任何一个语句操作失败那么整个操作就被失败,以后操作就会回滚到操作前状态,或者是上有个节点。
为了确保要么执行,要么不执行,就可以使用事务。要将一组语句作为事务考虑,就需要通过ACID测试,即原子性,一致性,隔离性和持久性。锁:
在所有的DBMS中,锁是实现事务的关键,锁可以保证事务的完整性和并发性。与现实生活中锁一样,它可以使某些数据的拥有者,在某段时间内不能使用某些数据或数据结构。当然锁还分级别的。共享锁(只读不写)、排他锁(可读可写)
1.15. 软件设计模式
设计原则
- 对接口编程而不是对实现编程
- 优先使用对象组合而不是继承


---单例模式
单体是一个用来划分命名空间并将一批相关的属性和方法组织在一起的对象,如果他可以被实例化,那么他只能被实例化一次
// 对象字面量
var Singleton = {
attr1: 1,
attr2: 2,
method1: function(){
return this.attr1;
},
method2: function(){
return this.attr2;
}
};
// 上面的所有成员变量都是通过Singleton来访问的,但是它并不是单体模式;
// 因为单体模式还有一个更重要的特点,就是可以仅被实例化一次,上面的只是不能被实例化的一个类,因此不是单体模式;对象字面量是用来创建单体模式的方法之一;
/*要实现一个单体模式的话,我们无非就是使用一个变量来标识该类是否被实例化
如果未被实例化的话,那么我们可以实例化一次,否则的话,直接返回已经被实例化的对象
*/
// 单体模式
var Singleton = function(name){
this.name = name;
this.instance = null;
};
Singleton.prototype.getName = function(){
return this.name;
}
// 获取实例对象
function getInstance(name) {
if(!this.instance) {
this.instance = new Singleton(name);
}
return this.instance;
}
// 测试单体模式的实例
var a = getInstance("aa");
var b = getInstance("bb");
console.log(a === b) // true
console.log(a.getName()) // aa
console.log(b.getName()) // aa应用案例
弹窗
传统创建:比如我点击一个元素需要创建一个div,我点击第二个元素又会创建一次div,我们频繁的点击某某元素,他们会频繁的创建div的元素,虽然当我们点击关闭的时候可以移除弹出代码,但是呢我们频繁的创建和删除并不好,特别对于性能会有很大的影响,对DOM频繁的操作会引起重绘等,从而影响性能;因此这是非常不好的习惯;我们现在可以使用单体模式来实现弹窗效果,我们只实例化一次就可以
编写通用的单体模式
我们使用一个参数fn传递进去,如果有result这个实例的话,直接返回,否则的话,当前的getInstance函数调用fn这个函数,是this指针指向与这个fn这个函数;之后返回被保存在result里面;现在我们可以传递一个函数进去,不管他是创建div也好,还是创建iframe也好,总之如果是这种的话,都可以使用getInstance来获取他们的实例对象;
// 创建div
var createWindow = function(){
var div = document.createElement("div");
div.innerHTML = "我是弹窗内容";
div.style.display = 'none';
document.body.appendChild(div);
return div;
};
// 创建iframe
var createIframe = function(){
var iframe = document.createElement("iframe");
document.body.appendChild(iframe);
return iframe;
};
// 获取实例的封装代码
var getInstance = function(fn) {
var result;
return function(){
return result || (result = fn.call(this,arguments));
}
};
// 测试创建div
var createSingleDiv = getInstance(createWindow);
document.getElementById("Id").onclick = function(){
var win = createSingleDiv();
win.style.display = "block";
};
// 测试创建iframe
var createSingleIframe = getInstance(createIframe);
document.getElementById("Id").onclick = function(){
var win = createSingleIframe();
win.src = "http://cnblogs.com";
};---以下为补充
---工厂模式
客户类和工厂类分开。消费者任何时候需要某种产品,只需向工厂请求即可。消费者无须修改就可以接纳新产品。
工厂模式是为了解决多个类似对象声明的问题;也就是为了解决实列化对象产生重复的问题。
- 优点:能解决多个相似的问题。
- 缺点:
- 不能知道对象识别的问题(对象的类型不知道)。
- 当产品修改时,工厂类也要做相应的修改。
function CreatePerson(name,age,sex) {
var obj = new Object();
obj.name = name;
obj.age = age;
obj.sex = sex;
obj.sayName = function(){
return this.name;
}
return obj;
}
var p1 = new CreatePerson("longen",'28','男');
var p2 = new CreatePerson("tugenhua",'27','女');---模块模式
模块模式的思路是为单体模式添加私有变量和私有方法能够减少全局变量的使用
prototype + constructor
---装饰者模式
装饰者(decorator)模式能够在不改变对象自身的基础上,在程序运行期间给对像动态的添加职责(方法或属性)。
与继承相比,装饰者是一种更轻便灵活的做法。
可以动态的给某个对象添加额外的职责,而不会影响从这个类中派生的其它对象。
// ES7装饰器
function isAnimal(target) {
target.isAnimal = true
return target
}
// 装饰器
@isAnimal
class Cat {
// ...
}
console.log(Cat.isAnimal) // true
// 作用于类属性的装饰器:
function readonly(target, name, descriptor) {
discriptor.writable = false
return discriptor
}
class Cat {
@readonly
say() {
console.log("meow ~")
}
}
var kitty = new Cat()
kitty.say = function() {
console.log("woof !")
}
kitty.say() // meow ~---观察者模式(发布-订阅)
发布---订阅模式又叫观察者模式,它定义了对象间的一种一对多的关系,让多个观察者对象同时监听某一个主题对象,当一个对象发生改变时,所有依赖于它的对象都将得到通知
发布订阅模式的流程如下:
- 确定谁是发布者(比如我的博客)。
- 然后给发布者添加一个缓存列表,用于存放回调函数来通知订阅者。
- 发布消息,发布者需要遍历这个缓存列表,依次触发里面存放的订阅者回调函数。
- 退订(比如不想再接收到这些订阅的信息了,就可以取消掉)
【实现事件模型】
即写一个类或是一个模块,有两个函数,一个bind一个trigger,分别实现绑定事件和触发事件,核心需求就是可以对某一个事件名称绑定多个事件响应函数,然后触发这个事件名称时,依次按绑定顺序触发相应的响应函数。
大致实现思路就是创建一个类或是匿名函数,在bind和trigger函数外层作用域创建一个字典对象,用于存储注册的事件及响应函数列表,bind时,如果字典没有则创建一个,key是事件名称,value是数组,里面放着当前注册的响应函数,如果字段中有,那么就直接push到数组即可。trigger时调出来依次触发事件响应函数即可
var Event = (function(){
var list = {},
listen,
trigger,
remove;
listen = function(key,fn){
if(!list[key]) {
list[key] = [];
}
list[key].push(fn);
};
trigger = function(){
var key = Array.prototype.shift.call(arguments),
fns = list[key];
if(!fns || fns.length === 0) {
return false;
}
for(var i = 0, fn; fn = fns[i++];) {
fn.apply(this,arguments);
}
};
remove = function(key,fn){
var fns = list[key];
if(!fns) {
return false;
}
if(!fn) {
fns && (fns.length = 0);
}else {
for(var i = fns.length - 1; i >= 0; i--){
var _fn = fns[i];
if(_fn === fn) {
fns.splice(i,1);
}
}
}
};
return {
listen: listen,
trigger: trigger,
remove: remove
}
})();
// 测试代码如下:
Event.listen("color",function(size) {
console.log("尺码为:"+size); // 打印出尺码为42
});
Event.trigger("color",42);---代理模式
代理是一个对象,它可以用来控制对本体对象的访问,它与本体对象实现了同样的接口,代理对象会把所有的调用方法传递给本体对象的
本地对象注重的去执行页面上的代码,代理则控制本地对象何时被实例化,何时被使用
优点:
- 代理对象可以代替本体被实例化,并使其可以被远程访问;
- 它还可以把本体实例化推迟到真正需要的时候;对于实例化比较费时的本体对象,或者因为尺寸比较大以至于不用时不适于保存在内存中的本体,我们可以推迟实例化该对象;
// 先申明一个奶茶妹对象
var TeaAndMilkGirl = function(name) {
this.name = name;
};
// 这是京东ceo先生
var Ceo = function(girl) {
this.girl = girl;
// 送结婚礼物 给奶茶妹
this.sendMarriageRing = function(ring) {
console.log("Hi " + this.girl.name + ", ceo送你一个礼物:" + ring);
}
};
// 京东ceo的经纪人是代理,来代替送
var ProxyObj = function(girl){
this.girl = girl;
// 经纪人代理送礼物给奶茶妹
this.sendGift = function(gift) {
// 代理模式负责本体对象实例化
(new Ceo(this.girl)).sendMarriageRing(gift);
}
};
// 初始化
var proxy = new ProxyObj(new TeaAndMilkGirl("奶茶妹"));
proxy.sendGift("结婚戒"); // Hi 奶茶妹, ceo送你一个礼物:结婚戒- TeaAndMilkGirl 是一个被送的对象(这里是奶茶妹);
- Ceo 是送礼物的对象,他保存了奶茶妹这个属性,及有一个自己的特权方法sendMarriageRing 就是送礼物给奶茶妹这么一个方法;
- 然后呢他是想通过他的经纪人去把这件事完成,于是需要创建一个经济人的代理模式,名字叫ProxyObj ;
- 他的主要做的事情是,把ceo交给他的礼物送给ceo的情人,因此该对象同样需要保存ceo情人的对象作为自己的属性,同时也需要一个特权方法sendGift ,该方法是送礼物,因此在该方法内可以实例化本体对象,这里的本体对象是ceo送花这件事情,因此需要实例化该本体对象后及调用本体对象的方法(sendMarriageRing).
理解使用虚拟代理实现图片的预加载
在网页开发中,图片的预加载是一种比较常用的技术,如果直接给img标签节点设置src属性的话,如果图片比较大的话,或者网速相对比较慢的话,那么在图片未加载完之前,图片会有一段时间是空白的场景,这样对于用户体验来讲并不好,那么这个时候我们可以在图片未加载完之前我们可以使用一个loading加载图片来作为一个占位符,来提示用户该图片正在加载,等图片加载完后我们可以对该图片直接进行赋值即可;下面我们先不用代理模式来实现图片的预加载的情况下代码如下:
// 不使用代理的预加载图片函数如下
var myImage = (function(){
var imgNode = document.createElement("img");
document.body.appendChild(imgNode);
var img = new Image();
img.onload = function(){
imgNode.src = this.src;
};
return {
setSrc: function(src) {
imgNode.src = "http://img.lanrentuku.com/img/allimg/1212/5-121204193Q9-50.gif";
img.src = src;
}
}
})();
// 调用方式
myImage.setSrc("https://img.alicdn.com/tps/i4/TB1b_neLXXXXXcoXFXXc8PZ9XXX-130-200.png");//利用代理模式来编写预加载图片
var myImage = (function(){
var imgNode = document.createElement("img");
document.body.appendChild(imgNode);
return {
setSrc: function(src) {
imgNode.src = src;
}
}
})();
// 代理模式
var ProxyImage = (function(){
var img = new Image();
img.onload = function(){
myImage.setSrc(this.src);
};
return {
setSrc: function(src) {
myImage.setSrc("http://img.lanrentuku.com/img/allimg/1212/5-121204193Q9-50.gif");
img.src = src;
}
}
})();
// 调用方式
ProxyImage.setSrc("https://img.alicdn.com/tps/i4/TB1b_neLXXXXXcoXFXXc8PZ9XXX-130-200.png");这种懒加载方法不用代理模式也是可以实现的,只是用代理模式。我们可以让 myImage 只做一件事,只负责将实际图片加入到页面中,而loading图片交给ProxyImage去做。从而降低代码的耦合度。因为当我不想用loading的时候,可以直接调用myImage 方法。也即是说假如我门不需要代理对象的话,直接可以换成本体对象调用该方法即可
对比
- 不代理:不满足单一职责原则,代码耦合度高
- myimage 函数只负责一件事,其他交给代理
优点
- 用户可以放心地请求代理,他们只关心是否能得到想要的结果。假如我门不需要代理对象的话,直接可以换成本体对象调用该方法即可。
- 在任何使用本体对象的地方都可以替换成使用代理。
参考:Javascript设计模式详解
1.2. Online Coding
js 实现两个超大数相加
基础:
- JS 中所有的数字类型,实际存储都是通过 8 字节 double 浮点型 表示的,并不是能够精确表示范围内的所有数
- 大整数存储(安全使用范围)
- 其他语言
2^63 - 1 - js
Math.pow(2, 53) - 1js //js 最大和最小安全值 Number.MAX_SAFE_INTEGER //9007199254740991 Number.MIN_SAFE_INTEGER //-9007199254740991
- 其他语言
var largeNumberAdd = function(num1, num2) {
var arr1 = num1.split(''),
arr2 = num2.split(''),
tem = '',
num3 = 0,
result = []
var longDiff = arr1.length - arr2.length
if (longDiff > 0) {
for (let i = 0; i < longDiff; i++) {
arr2.unshift('0')
}
}else if (longDiff < 0) {
for (let i = 0; i < Math.abs(longDiff); i++) {
arr1.unshift('0')
}
}
for (let i = arr1.length - 1; i >= 0; i--) {
tem = parseInt(arr1[i]) + parseInt(arr2[i]) + num3
// check if tem > 10
if (tem >= 10) {
num3 = 1
result.push((tem + '')[1])
}else {
num3 = 0
result.push(tem)
}
}
return result.reverse().join('')
}
// console.log(largeNumberAdd('11111','11111'))
console.log(largeNumberAdd('00000000000000000000011111','333331999'))
console.log(11111+333331999)
// console.log(largeNumberAdd('3333333333333333333333333333333311111111111111111111111111111111111111','333333333333333331111111111111111111111111111166666666666666'))js 每秒钟的计算量
js 如何解析后台返回的超大数据
前提:
js 用浮点数表示所有64位数字,所有达到 2^53 的可以被精确表示,更大的数字都会被裁剪,——如何表示64位数字
虽然js 能够解析进制数字表示64位数字,但底层的数字表示不支持 64 位
在浏览器中执行以下代码(2^50+1) - (2^50) =
(2^51+1) - (2^51) =
(2^52+1) - (2^52) =
(2^53+1) - (2^53) =
(2^54+1) - (2^54) =
在Firefox,Chrome和IE浏览器中,可以看到,如果能够存储64位数字,则以下减法结果皆为1。而结果相反,可以看到2 ^ 53 + 1和2 ^ 53 间的差异丢失
js (2 ^ 50 + 1) - (2 ^ 50)= 1 (2 ^ 51 + 1) - (2 ^ 51)= 1 (2 ^ 52 + 1) - (2 ^ 52)= 1 (2 ^ 53 + 1) - (2 ^ 53)= 0 (2 ^ 54 + 1) - (2 ^ 54)= 0位运算
因此,我们可以选择用两个 32 位的数字表示 64 位整数,然后进行按位与var a = [ 0x0000ffff, 0xffff0000 ]; var b = [ 0x00ffff00, 0x00ffff00 ]; var c = [ a[0] & b[0], a[1] & b[1] ]; document.body.innerHTML = c[0].toString(16) + ":" + c[1].toString(16); //结果 ff00:ff0000
网络安全
前端网络安全的实现
- 保证http传输安全性
如何检测恶意脚本
如何屏蔽
2. 阿里
一面
- 简单介绍一下自己
- 问题
- HTTP 相关
HTTP 与 HTTPS 区别,HTTPS 原理,如何加密 - 谈谈闭包
- 谈谈作用域链
- 常用的跨域方式
- vue
- 特点
- 生命周期
- vuex
实现原理(事件绑定)-如何实现 - 与 react 的不同
应用场景 - 如何实现双向绑定
- 如何通信
- HTTP 相关
- 其他
- 还会哪些语言
- 还有什么感觉没问到但掌握很好的
- 是否还有其他的问题
- 有什么问题想要问的
二面
- react
多次调用 setstate 为什么不马上渲染 - 解析 json ,手写 parse 函数
- csrf 举例
- 获取dom节点方式
- 将给定节点子元素第一个和最后一个元素替换
- 端口号的作用
端口
IP地址让网络上的两个节点之间可以建立点对点的连接
端口号则为端到端的连接提供了可能 (程序间通讯的接口)
IP协议是由TCP、UDP、ARP、ICMP等一系列子协议组成的。其中
TCP和UDP协议
主要用来做传输数据使用的
在TCP和UDP协议中,都有端口号的概念存在
端口号的作用
主要是区分服务类别和在同一时间进行多个会话服务类别
举例来说,有主机A需要对外提供FTP和WWW两种服务,如果没有端口号存在的话,这两种服务是无法区分的。
实际上,当网络上某主机B需要访问A的FTP服务时,就要指定目的端口号为21;
当需要访问A的WWW服务时,则需要将目的端口号设为80,这时A根据B访问的端口号,就可以区分B的两种不同请求
- 多个会话
- 主机A需要同时下载网络上某FTP服务器B上的两个文件,那么A需要 与B同时建立两个会话,而这两个传输会话就是靠源端口号来区分的。在这种情况下如果没有源端口号的概念,那么A就无法区分B传回的数据究竟是属于哪个会话,属于哪个文件
- 通信过程是,A使用本机的1025号端口请求B的21号端口上的文件1,同时又使用1026号端口请求文件2。对于返回的数据,发现是传回给1025号端口的,就认为是属于文件1;传回给1026号端口的,则认为是属于文件2。这就是端口号区分多个会话的作用。

在线编程——编写一个 css 层级选择器
根据一个给定的元素生成一个css 选择器,函数名为genCssSelector ,
点击某元素弹出该元素及其父元素,类似 querySelector
Document
23333
获取 dom 元素
JS获取DOM元素的方法(8种)
只获取到一个元素,没有找到返回nullgetElementByIdgetElementsByNamegetElementsByTagNamegetElementsByClassName
获取htmldocument.documentElement
获取bodydocument.body
获取一个元素querySelectorquerySelectorAll获取一组元素
获取子元素
- childNodes
dom.childNodes返回一个nodeList(元素的所有子元素)- nodeType
- 元素节点的nodeType属性值为1
- 属性节点的nodeType属性值为2
- 文本节点的nodeType属性值为3
nodeValue属性
获得和改变文本节点的值
- nodeType
- firstChild 第一个子元素
- lastChild
获取父、兄
parentNodenextSiblingpreviousSbiling
创建元素
创建一个dom片段createDocumentFragment
创建一个具体的元素createElementcreateTextNode创建一个文本节点
增删改元素
appendChildremoveChildreplaceChildinsertBefore
如何用 JS 实现 JSON.parse
---eval
直接调用eval
var json = '{"a":"1", "b":2}';
var obj = eval("(" + json + ")"); // obj 就是 json 反序列化之后得到的对象原理
JSON 脱胎于 JS,同时也是 JS 的子集,所以能够直接交给 eval 运行
加上圆括号的目的是迫使eval函数在处理JavaScript代码的时候强制将括号内的表达式(expression)转化为对象,而不是作为语句(statement)来执行
例如对象字面量{},如若不加外层的括号,那么eval会将大括号识别为JavaScript代码块的开始和结束标记,那么{}将会被认为是执行了一句空语句
缺点
XSS 漏洞
如:参数 json 并非真正的 JSON 数据,而是可执行的 JS 代码对参数 json 做校验,只有真正符合 JSON 格式,才能调用 eval
```js
// 1. 用 4 个正则表达式分为两个阶段解决(包容ie 和safari 的regexp 引擎)
// 2. 将 json 反斜杠替换为 '@' (non-json字符)
// 3. 用 ']' 替换所有简单标记
// 4. 删除所有跟随冒号,逗号或文本开始的方括号
// 5. 如果只剩下 '] , { }' 则是安全的var rx_one = /^[],:{}\s]$/;
var rx_two = /\(?:["\/bfnrt]|u[0-9a-fA-F]{4})/g;
var rx_three = /"[^"\\\n\r]"|true|false|null|-?\d+(?:.\d)?(?:[eE][+-]?\d+)?/g;
var rx_four = /(?:^|:|,)(?:\s[)+/g;if (
rx_one.test(
json
.replace(rx_two, "@")
.replace(rx_three, "]")
.replace(rx_four, "")
)
) {
var obj = eval("(" +json + ")");
}
```
---递归
第一种 eval 的方法,相当于一股脑儿把 JSON 字符串塞进去。
其实我们还可以手动逐个字符地扫描,然后进行判断,这就是第二种方法:递归
// 所谓递归,就是重复调用value 函数
value = function () {
// Parse a JSON value. It could be an object, an array, a string, a number,
// or a word.
white();
// 根据当前字符是什么,我们便能推导出后面应该接的是什么类型
switch (ch) {
case "{":
return object();
case "[":
return array();
case "\"":
return string();
case "-":
return number();
default:
return (ch >= "0" && ch <= "9")
? number()
: word();
}
};
// 调用核心的 next 函数,逐个读取字符
var next = function (c) {
// If a c parameter is provided, verify that it matches the current character.
if (c && c !== ch) {
error("Expected '" + c + "' instead of '" + ch + "'");
}
// Get the next character. When there are no more characters,
// return the empty string.
ch = text.charAt(at);
at += 1;
return ch;
};- 对于常量token
false true null进行匹配,不匹配返回错误
以 {"a":"1", "b":2} 为例
程序大致逻辑是:启动 → 首次调用 value() → 发现是 { → 原来是对象,走 object() → 通过 string() 得到 key 值为 "a" → 读取到冒号,哦,后面可能是对象、数组、布尔值等等,具体是什么,还得再次调用 value() 才知道 → ……
xml 解析
close tag
使用一个 nodeStack 栈,在 opentag 时推入节点,close tag 时检查当前节点是否和栈尾节点是否匹配,匹配则推出末尾节点comment
参考:JSON.parse 三种实现方式
react setState
setState 不保证同步
- 可能会为了性能收益批量执行
setState()不会立刻改变this.state,而是创建一个即将处理的 state 转变。在调用该方法之后访问this.state可能会返回现有的值。
使用回调函数
setState 方法接收一个 function 作为回调函数。这个回掉函数会在 setState 完成以后直接调用,这样就可以获取最新的 state
js this.setState({ selection: value }, this.fireOnSelect)setTimeout
在 setState 使用 setTimeout 来让 setState 先完成以后再执行里面内容js this.setState({ selection: value }); setTimeout(this.fireOnSelect, 0);
- 造成不必要的渲染
shouldComponentUpdate解决setState()将总是触发一次重绘,除非在shouldComponentUpdate()中实现了条件渲染逻辑和渲染无关的状态尽量不要放在 state 中来管理
通常 state 中只来管理和渲染有关的状态 ,从而保证 setState 改变的状态都是和渲染有关的状态。这样子就可以避免不必要的重复渲染。其他和渲染无关的状态,可以直接以属性的形式保存在组件中,在需要的时候调用和改变,不会造成渲染。
不能很有效的管理所有的组件状态
参考:浅谈使用React.setState需要注意的三点
3. 百度
一面
jsonp cors
css
- 分栏布局哪些方式
- 详细说下flex
js & jq
- 如何获取一个元素(js jq)
- 异步事件是如何发送的,常用机制
- 有哪些接收后台数据的方法
- ajax
- fetch
- jsonp
- websocket
- SSE
- event loop
- 喜欢 es6 的哪些属性
- 箭头函数与普通函数的不同
- 闭包
- 简述
- 应用
- 在循环中如何用其他方式代替闭包
vue
- 和 react 区别
- 如何向服务器传递数据
操作系统
- 线程 && 进程
计算机网络
- 除了tcp 还用到哪些
- http 与 tcp 分别属于第几层
数据结构
- 有哪些线性存储空间(array 栈)
二面
如何做一个 css 选择器
见本文 阿里-在线编程给定一组dom 节点,和一个css样式表,找出不含有样式的dom
面试官很耐心的解释了,还是没听明白题目- 链表操作
- 单向链表反转
居中问题
没有详细问,我分了两个方面分别回答- 水平居中
- 垂直水平
get & post
回答了大多数应聘者的 “标准答案”, 但经面试官指点,顿悟,大概这就叫高手吧
三面
数字的存储
- 正负数在计算机中是如何存储的
无符号与有符号二进制存储
理解有符号数和无符号数负数
- 前端的编码问题
- 种类
- 乱码如何处理
- 有哪些协议,分别有什么作用
- 关于实习经历,找实习的过程,项目中的二三事及解决方案
- 大学中最有成就感的事
闲聊了一下,关于保研等等,总共 四十分钟
分栏布局
---等分布局
- float
原理:增大父框的实际宽度后,使用CSS3属性box-sizing进行布局的辅助。
用法:先将父框设置为
margin-left: -*px,再设置子框float: left、width: 25%、padding-left、box-sizing: border-box.parent{ margin-left: -20px; } .column{ float: left; width: 25%; padding-left: 20px; box-sizing: border-box; /*包含padding区域 w+g*/ }
- table
原理:通过增加一个父框的修正框,增大其宽度,并将父框转换为 table,将子框转换为 tabel-cell 进行布局。
用法:先将父框的修正框设置为
margin-left: -*px,再设置父框display: table、width:100%、table-layout: fixed,设置子框display: table-cell、padding-left.parent-fix{ margin-left: -20px; } .parent{ display: table; width:100%; table-layout: fixed; } .column{ display: table-cell; padding-left: 20px; }
- flex
原理:通过设置CSS3布局利器flex中的flex属性以达到等分布局。
用法:将父框设置为display: flex,再设置子框flex: 1,最后设置子框与子框的间距margin-left。
如何获取一个class
// 直接获取---需要高版本浏览器支持
document.querySelectorAll("div.aa")
// 类似属性选择器的写法
document.querySelectorAll("div[class='aa']")
// 补充一下还可以not选择器
document.querySelectorAll(".aa:not(ul)")
document.getElementsByClassName('cls')
// jq
$('.className')Event Loop
js 单线程:
用途决定,操作 DOM
任务队列
排队原因:计算量大的同步执行,IO设备(输入输出设备)很慢(比如Ajax操作从网络读取数据)异步。
异步任务指的是,不进入主线程、而进入"任务队列"(task queue)的任务,只有"任务队列"通知主线程,某个异步任务可以执行了,该任务才会进入主线程执行
"任务队列"中的事件,除了IO设备的事件以外,还包括一些用户产生的事件(比如鼠标点击、页面滚动等等)。只要指定过回调函数,这些事件发生时就会进入"任务队列",等待主线程读取。
所有同步任务都在主线程上执行,形成一个执行栈(execution context stack)。
主线程之外,还存在一个"任务队列"(task queue)。只要异步任务有了运行结果,就在"任务队列"之中放置一个事件。
一旦"执行栈"中的所有同步任务执行完毕,系统就会读取"任务队列",看看里面有哪些事件。那些对应的异步任务,于是结束等待状态,进入执行栈,开始执行。
主线程不断重复上面的第三步。
只要主线程空了,就去检查异步的任务队列,如果异步事件触发,则将其加到主线程的执行栈
深入了解定时器
零延迟
零延迟并不是意味着回调函数立刻执行。它取决于主线程当前是否空闲与“任务队列”里其前面正在等待的任务。setTimeout(func, 0)调用setTimeout()之后,该方法会返回一直数值ID,表示超时调用。这个超时调用ID是计划执行代码的唯一标识符,可以通过它来取消超时调用
超时调用的代码都是在全局作用域中执行的,因此函数中this的值在非严格模式下指向window对象,严格模式下是undefined。
Event Loop
异步与event loop没有太直接的关系,准确的来讲event loop 只是实现异步的一种机制
主任务 ——> micro task ——> 渲染视图 ——> macro task
主线程从"任务队列"中读取事件,这个过程是循环不断的,所以整个的这种运行机制又称为Event Loop(事件循环)
Javascript 中的事件循环是以任务为单位的,将很多个待执行的任务串联在一起就形成了队列 Task Queue,很多的队列先后按顺序执行任务就形成了 Event Loop
一个事件循环(EventLoop)中会有一个正在执行的任务(Task),而这个任务就是从 macrotask 队列中来的。
当这个 macrotask 执行结束后,所有可用的 microtask 将会在同一个事件循环中执行
当这些 microtask 执行结束后还能继续添加 microtask 一直到真个 microtask 队列执行结束。
一个事件循环(event loop)会有一个或多个任务队列(task queue)
task queue 就是 macrotask queue- 每一个 event loop 都有一个 microtask queue
- task queue == macrotask queue != microtask queue
- 一个任务 task 可以放入 macrotask queue 也可以放入 microtask queue 中
当一个 task 被放入队列 queue(macro或micro) 那这个 task 就可以被立即执行了
Micro Task
当我们想以同步的方式来处理异步任务时候就用 microtask(比如我们需要直接在某段代码后就去执行某个任务,就像Promise一样)
- process.nextTick
- promise
- Object.observe
- MutationObserver
Macro Task
- setTimeout
- setInterval
- setImmediate
- I/O
任务队列中,在每一次事件循环中,从 macrotask 队列开始执行,macrotask只会提取一个执行,而microtask会一直提取,直到microsoft队列为空为止。
也就是说如果某个microtask任务被推入到执行中,那么当主线程任务执行完成后,会循环调用该队列任务中的下一个任务来执行,直到该任务队列到最后一个任务为止。而事件循环每次只会入栈一个macrotask,主线程执行完成该任务后又会检查microtasks 队列并完成里面的所有任务后再执行macrotask的任务。
执行过程如下:
- 主线程空闲时首先执行 micro
- 之后从 macro 中提取一个 task 到主任务,完成后再次执行 micro queue(执行一个cycle)
- 反复过程2, 每个周期为一个事件循环
为啥要用 microtask?
- micro 执行总在 macro 之前
- micro 全部执行完毕后会更新 UI 和执行下一个macro
根据HTML Standard,在每个 task 运行完以后,UI 都会重渲染,那么在 microtask 中就完成数据更新,当前 task 结束就可以得到最新的 UI 了
// 验证
(function () {
const $test = document.getElementById('test')
let counter = 0
function func1() {
$test.innerText = ++counter
alert('func1')
}
function func2() {
$test.innerText = ++counter
alert('func2')
}
function func3() {
$test.innerText = ++counter
alert('func3')
}
function func4() {
$test.innerText = ++counter
alert('func4')
}
(function () {
// main task
func1()
// macro task
setTimeout(() => {
func2()
// micro task
Promise.resolve().then(func4)
}, 0);
// macro task
setTimeout(func1, 0);
// micro task
Promise.resolve().then(func3)
// main task
func4()
})()
// alert func1
// alert func4
// alert func3
// UI update ---> counter = 3
// alert func2
// alert func4
// UI update ---> counter = 5
// alert func1
// UI update ---> counter = 6
})()接收后台资源的方法(除了Ajax)
- Ajax
fetch
返回一个Promise对象, 根据 Promise Api 的特性, fetch可以方便地使用then方法将各个处理逻辑串起来mode
// fetch可以设置不同的模式使得请求有效 fetch(url, {mode: 'cors'});- same-origin
- cors
- cors-with-forced-preflight
- no-cors
推荐阅读: Fetch 进阶指南
Jsonp
- websocket
服务器推送技术之一
全双工 SSE(server-sent-events)
单向通道(服务器 -> 浏览器)
异步编程常用方法
ES 6以前:
- 回调函数
- 事件监听(事件发布/订阅)
- Promise对象
ES 6:
- Generator函数(协程coroutine)
ES 7:
- async和await
回调函数
一般是需要在一个耗时操作之后执行某个操作时可以使用回调函数
- 定时器
- 读取文件
问题:
在回调函数之外无法捕获到回调函数中的异常
var fs = require('fs');
try{
fs.readFile('not_exist_file', 'utf8', function(err, data){
console.log(data);
});
}
catch(e){
console.log("error caught: " + e);
}尝试读取一个不存在的文件,这当然会引发异常,但是最外层的try/catch语句却无法捕获这个异常。这是异步代码的执行机制导致的
为什么异步代码回调函数中的异常无法被最外层的try/catch语句捕获?
异步调用一般分为两个阶段,提交请求和处理结果,这两个阶段之间有事件循环的调用,它们属于两个不同的事件循环(tick),彼此没有关联。
异步调用一般以传入callback的方式来指定异步操作完成后要执行的动作。而异步调用本体和callback属于不同的事件循环。
try/catch语句只能捕获当次事件循环的异常,对callback无能为力。
事件监听(订阅-发布)
典型的逻辑分离方式,对代码解耦很有用处
把不变的部分封装在组件内部,供外部调用,需要自定义的部分暴露在外部处理。
从某种意义上说,事件的设计就是组件的接口设计。
//发布和订阅事件
var events = require('events');
var emitter = new events.EventEmitter();
emitter.on('event1', function(message){
console.log(message);
});
emitter.emit('event1', "message for you");Promise 对象
用同步操作的流程写法来表达异步操作,避免了层层嵌套的异步回调
Promise.prototype.then()
Promise构造函数的参数是一个函数,在这个函数中我们写异步操作的代码//原生Primose顺序嵌套回调示例 var fs = require('fs') var read = function (filename){ var promise = new Promise(function(resolve, reject){ fs.readFile(filename, 'utf8', function(err, data){ if (err){ reject(err); } resolve(data); }) }); return promise; } read('./text1.txt') .then(function(data){ console.log(data); return read('./text2.txt'); // 返回了一个新的Promise实例 }) .then(function(data){ console.log(data); });
在异步操作的回调中,根据err变量来选择是执行resolve方法还是reject方法- 一般来说调用resolve方法的参数是异步操作获取到的数据(如果有的话),但还可能是另一个Promise对象,表示异步操作的结果有可能是一个值
- 也有可能是另一个异步操作,调用reject方法的参数是异步回调用的err参数
调用read函数时,实际上返回的是一个Promise对象,通过在这个Promise对象上调用then方法并传入resolve方法和reject方法来指定异步操作成功和失败后的操作。
Promise.prototype.catch()用于指定发生错误时的回调函数
read('./text1.txt') .then(function(data){ console.log(data); return read('not_exist_file'); }) .then(function(data){ console.log(data); }) .catch(function(err){ console.log("error caught: " + err); }) .then(function(data){ console.log("completed"); })使用Promise对象的catch方法可以捕获异步调用链中callback的异常
Promise对象的catch方法返回的也是一个Promise对象,因此,在catch方法后还可以继续写异步调用方法- Promise异步并发
Promise.all()- 将多个Promise实例,包装成一个新的Promise实例
var p = Promise.all([p1,p2,p3]); - 接受一个数组作为参数,p1、p2、p3都是Promise对象实例
- 只有p1、p2、p3的状态都变成fulfilled,p的状态才会变成fulfilled,此时p1、p2、p3的返回值组成一个数组,传递给p的回调函数。
只要p1、p2、p3之中有一个被rejected,p的状态就变成rejected,此时第一个被reject的实例的返回值,会传递给p的回调函数。
Promise.all(promises)
```js
var promises = [1, 2].map(function(fileno){
return read('./text' + fileno + '.txt');
});
.then(function(contents){
console.log(contents);
})
.catch(function(err){
console.log("error caught: " + err);
})
```
- 将多个Promise实例,包装成一个新的Promise实例
Promise.race()- 将多个Promise实例,包装成一个新的Promise实例
var p = Promise.race([p1,p2,p3]); - p1、p2、p3只要有一个实例率先改变状态,p的状态就会跟着改变,那个率先改变的Promise实例的返回值,就传递给p的返回值。
- 如果Promise.all方法和Promise.race方法的参数不是Promise实例,就会先调用下面讲到的Promise.resolve方法,将参数转为Promise实例,再进一步处理
- 将多个Promise实例,包装成一个新的Promise实例
Promise.resolve()- 将现有对象转换成Promise对象
var p = Promise.resolve('Hello'); p.then(function (s){ console.log(s) });Promise.reject()- 返回一个新的Promise实例,该实例的状态为rejected。
Promise.reject方法的参数reason,会被传递给实例的回调函数。
var p = Promise.reject('出错了'); p.then(null, function (s){ console.log(s) });
- Generator函数
- 可以交出函数的执行权(暂停执行)
整个Generator函数就是一个封装的异步任务,或者说是异步任务的容器。异步操作需要暂停的地方,都用yield语句注明。
function* gen(x){ var y = yield x + 2; return y; } var g = gen(1); var r1 = g.next(); // { value: 3, done: false } console.log(r1); var r2 = g.next() // { value: undefined, done: true } console.log(r2);
**Generator函数的函数名前面有一个"*"**
- 调用Generator函数,会返回一个内部指针(即遍历器)g,这是Generator函数和一般函数不同的地方,调用它不会返回结果,而是一个指针对象。
- 调用指针g的next方法,会移动内部指针,指向第一个遇到的yield语句
- next方法的作用是分阶段执行Generator函数。每次调用next方法,会返回一个对象,表示当前阶段的信息(value属性和done属性)
- value属性是yield语句后面表达式的值,表示当前阶段的值;
- done属性是一个布尔值,表示Generator函数是否执行完毕,即是否还有下一个阶段
- Thunk 函数
Thunk 函数的含义和用法 ES 7中的async和await
- fetch
- 替代浏览器原生的XMLHttpRequest异步请求
来自深入解析Javascript异步编程
get & post 剖析
入门回答
区别:
- get
- 参数包含在 URL 中
- 大小有限制
- 使用Request.QueryString 获取变量的值
- 安全性差,直观显示
- post
- 通过 request body 传递参数
- 通过 Request.Form 获取变量的值
当我满心充满着自信和喜悦时,仿佛看到了面试官眉头一皱,So?
“标准答案”
| aspect | GET | POST |
|---|---|---|
| 浏览器回退 | 无影响 | 回退会再次提交请求 |
| 地址标记 | 产生的 URL 地址可以被 Bookmark | 提交地址不被标记 |
| cache | 该请求会被浏览器主动 cache | 该请求不会被缓存 |
| 编码 | 只能进行url编码 | 支持多种编码方式 |
| 参数保留 | 请求参数会被完整保留在浏览器历史记录里 | POST中的参数不会被保留 |
| 长度限制 | 有(浏览器限制,IE-2083个字符) | 无(限制作用的是服务器的处理程序的处理能力) |
| 参数类型 | 只接受ASCII字符 | 没有限制 |
| 参数传递 | 通过URL传递 | 放在Request body中 |
裸奔剖析
99%的人都理解错了HTTP中GET与POST的区别
前端编码
| 字符 | 表示 | 补充 |
|---|---|---|
| 二进制 | 0/1 | 八个二进制位可以组合出256种状态,这被称为一个字节(byte) |
| 八进制 | 0~7 | |
| 十进制 | 0~9 | |
| 十六禁止 | 0~9 A~F |
- 8byte = 1bit
- 1024 字节 = 1k
- 1024k = 1M
- 1024M = 1G
- 1024G = 1T
| 编码 | 特征 | 补充 |
|---|---|---|
| 二十一进制码(BCD码) | 保留了十进制数的权,而数字则用二进制数码0和1的组合来表示 | 在需要高精度的计算中BCD编码比较常用(了解) |
| ASCII码 | 美国信息交换标准委员会制定的7位字符编码,用7位二进制码表示一个字符,第8 位用于确定附加的128 个特殊符号字符、外来语字母和图形符号 | |
| GB2312 | 为了保存非英文,使用127号之后的空位保存新的字母(一个8位的字节可以组合256种状态,ASCII只编到127号),一直编到最后一位255,而且不同国家表示的符号也不一样,也可以说GB2312是对ASCII的中文扩展 | 不够用,后来只要求只要第一个字节是大于127就固定表示这是一个汉字的开始,称之为GBK编码 |
| GB18030 / DBCS | 编码中又增加了几千个新的少数民族的字,GBK扩展成了GB18030统称它们叫做DBCS | |
| Unicode | ISO(国际标准化组织)废弃了所有地区性编码方案,做了一套包括了地球上所有文化、符号以及字母的编码;ISO规定:必须用两个字节,16位来统一表示所有的字符,无论是半角的英文字母,还是全角的汉字,它们都是统一的一个字符!也就是两个字节 | |
| UTF-8 | UTF-8 互联网上使用最广的一种 Unicode 的实现方式,每次以8个位为单位传输数据;UTF-16就是每次 16 个位 | UTF-8 最大的一个特点,就是它是一种变长的编码方式,Unicode一个中文字符占 2 个字节,而UTF-8一个中文字符占3个字节,UTF-8是Unicode的实现方式之一 |
进制转换
------十进制转其他-------
var a = 24;
a.toString(2);//11000
a.toString(8);//30
a.toString(16);//18
------其他转十进制-------
var b=11000,c=30,d=18;
console.log(parseInt(b, 2)); // 二进制转十进制
console.log(parseInt(c, 8)); // 八进制转十进制
console.log(parseInt(d, 16));// 十六进制转十进制前端编码问题
在使用nodeJS编写前端工具时,对文本文件的操作比较多,这就涉及到了文件的编码问题,常用的文本编码有UTF8和GBK两种,并且UTF8文件还可能带有BOM(字节顺序标记),在读取不同编码的文本文件时,需要将文件内容转换为JS使用的UTF8编码字符串后才能正常处理
移除 BOM
BOM用于标记一个文本文件使用Unicode编码,其本身是一个Unicode字符("\uFEFF"),位于文本文件头部以告诉其他编辑器以utf8来显示字符
但是在网页上并不需要添加BOM头识别,因为网页上可以使用 head头 指定charset=utf8告诉浏览器用utf8来解释.但是你用window自动的编辑器,编辑,然后有显示在网页上这样就会显示出0xEF 0xBB 0xBF这3个字符。这样网页上就需要去除0xEF 0xBB 0xBF- 可以使用editplus 选择不带BOM的编码,这样就可以去除了
js 去除
// 可以通过文件头的几个字节来判断文件是否包含BOM以及使用哪种Unicode,如果读取文件的时候不去掉BOM // 假如我们将几个JS文件合并成一个,如果文件中含有BOM字符,就会导致语法错误 // 所以我们用 nodeJS读取文件是一般先去掉BOM var bin = fs.readFileSync(pathname);//通过node 中fs模块同步读文件内容 //判断文件头的字节 if (bin[0] === 0xEF && bin[1] === 0xBB && bin[2] === 0xBF) { bin = bin.slice(3); }
GBK 转 UTF8
NodeJS支持在读取文本文件时,或者在Buffer转换为字符串时指定文本编码,但GBK编码不在NodeJS自身支持范围内,一般我们借助iconv-lite这个三方包来转换编码,首先使用npm下载这个第三方包,读取GBK文件函数如下:
var iconv = require('iconv-lite'); function readGBKText(pathname) { var myFs = fs.readFileSync(pathname); return iconv.decode(myFs, 'gbk'); }
数据结构
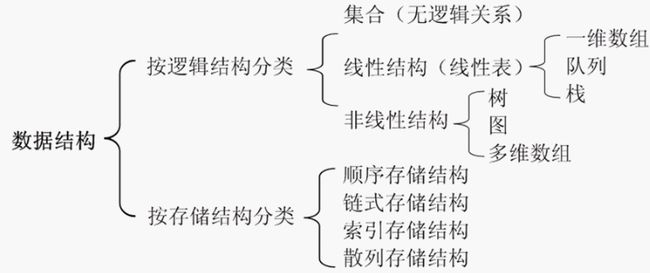
常用的线性结构有:线性表,栈,队列,循环队列,数组
线性表中包括顺序表、链表等,其中:
- 栈和队列只是属于逻辑上的概念,实际中不存在,仅仅是一种思想,一种理念;
- 线性表则是在内存中数据的一种组织、存储的方式。
常见的排序算法及其时间复杂度

参考:十大经典排序算法总结(JavaScript描述)
其他
- git 与 GitHub 有什么区别
- git 的一些指令
- Linux
计算机网络

**如有不足,欢迎交流,祝各位看官 offer 拿到手软 O(∩_∩)O**
我的博客即将搬运同步至腾讯云+社区,邀请大家一同入驻:https://cloud.tencent.com/developer/support-plan