pandas常用的操作1:读存,插入,删除,切片,转换,合并
pandas常用操作
1.读文件与写文件:
通常情况下,若使用pandas库对数据进行处理,文件较小的时候,可以使用read_csv()函数来进行读数据。
假设我们的原始数据文件:ad_info.csv,数据形式为:
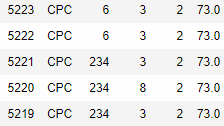
从上图,我们可以看出,数据没有header,并且也没有列名,如果想加入列名,可以在读取的时候,加入参数:names来指定列名,也可以采用先读入文件,再使用columns更改列名等方式。
例如:
import pandas as pd
### 读取文件,并设置列名,去掉header, sep设置以‘,’分割数据
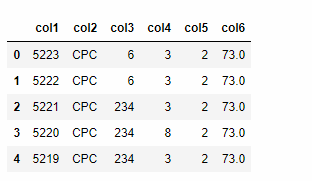
data = pd.read_csv('./dataset/ad_info.csv',sep=',',header=None, names=['col1', 'col2', 'col3', 'col4', 'col5', 'col6'])
### 查看data前五行数据
data.head()
out:
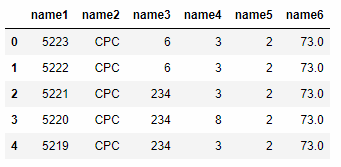
采用先读取再修改列名:
data.columns = ['name1', 'name2', 'name3', 'name4', 'name5', 'name6']
当文件较大的时候,直接将数据全部读入到内存中,可能并不是一个较为理想的做法。
可以采用在read_csv()函数中传入参数iterator=True,chunksize=100,此时pandas将会按迭代的方式每次从文件中读取100数据进行处理。
例如:
## 按chunk方式读取数据
train = pd.read_csv('./dataset/trainXXXXX.csv',header=None,
iterator=True,
chunksize=10000000,
names=['label', 'uId', 'adId', 'operTime', 'siteId', 'slotId', 'contentId', 'netType'])
for chunk in train:
# 在这里嵌入你的代码,来处理数据
# 按流式来保存处理后的文件
chunk.to_csv('./data.csv',mode='a', index=None)
直接保存文件是较为简单的,但是应该要注意的是index在保存文件的时候可以省略不保存。
## data导出csv文件
data.to_csv('./data.csv', index=None)
注意传入的参数 header, index, column =[]
2.查看数据与统计数据
2.1查看数据
我们将数据读入到dataframe中后,想要查看数据时,可以采用:
查看数据前几行:
## 查看前5行数据
data.head()
## 查看前10行数据
data.head(n=10)
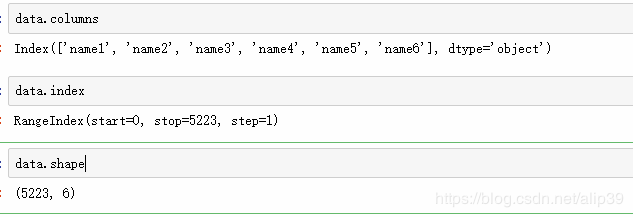
查看数据的列名,索引:
data.columns
data.index
data.shape
当然还有一些其它描述性的函数,例如data.info()函数来查看数据类型,data.describe()函数能看到每列的统计学数值,也是较为常用的函数。
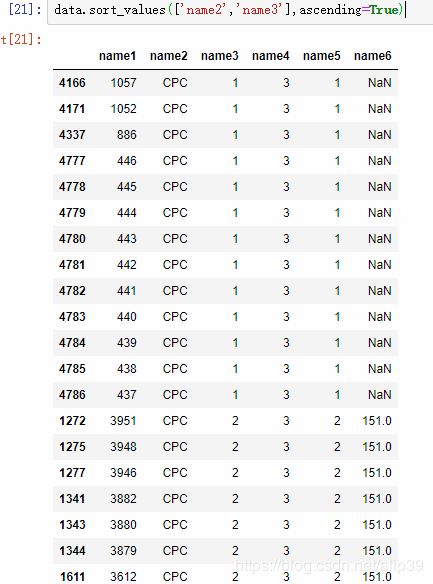
排序查看
若想要按照某个列顺序查看数据,或者对数据进行排序:
可以使用sort_values()函数。
例如:
## 单字段排序
data.sort_values(['name1'])
## 也可以多字段进行排序
data.sort_values(['name2','name3'],ascending=True)

3.统计数据
3.1聚合统计:
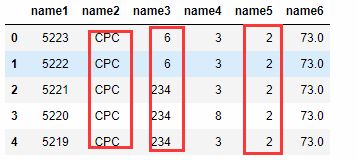
由上述数据可知,name2中包含了CPC和CPM两个字段,我们想求得CPC下name3的最大值为多少时,这时就需要groupby() 函数,来进行聚合操作,在进行统计。
例如:
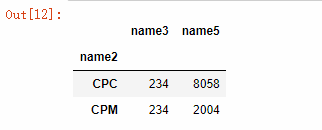
data.groupby(['name2']).agg({'name3':max, 'name5':sum})
注:对name3进行求最大值,对name5求和。
out:
一些常用的统计学函数:
求和:sum()
平均值:mean()
中位数:median()
方差:std()
最大值与最小值; max(),min()
自然,groupby函数与apply,agg等函数组合起来能做许多事情,日后再讲吧。
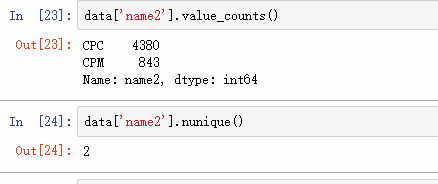
3.2 统计有多少的不同数据:
## 只显示数值
data['name2'].nunique()
## 显示全部
data['name2'].value_counts()
4.切片操作
4.1 选取某列
## 选取name1 name2
data_sub = data[['name1','name2']]
4.2 按某种条件切片
某列的值大于某值:
data_sub = data[data['name3']>6]
选取字母G开头的切片
data[data.Team.str.startswith('G')]
4.3 选取前几列操作(转换成索引形式):
data.iloc[: , 0:7]
5.删除某列
采用drop()函数来删除某一列或某些列数据
### 注意axis设置
data.drop(['name1', 'name2'], axis=1)
6.合并操作
6.1 按行的维度进行合并
## 将两个data1和data2合并起来,复制给data
data = pd.concat([data1, data2])
6.2 按列维度进行合并
data = pd.concat([data1, data2], axis = 1)
6.3 按id进行合并,mearge可实现合并,交集,并集
## merge操作可指定key合并
data = pd.merge(data1, data2, on='subject_id')
与此同时,numpy中也存在合并操作:
比如:stack()与hstack(),vstack()