如约而至,Java 10 正式发布!
3 月 20 日,Oracle 宣布 Java 10 正式发布。
官方已提供下载:http://www.oracle.com/technetwork/java/javase/downloads/index.html 。
在 Java 9 之后,Java 采用了基于时间发布的策略,每 6 个月一个版本。这是采用新的发布策略之后的第一个版本。
Java 10 主要有 12 个新特性。

具体来看看。
JEP 286: Local-Variable Type Inference
局部变量的类型推导。
很多人都会吐槽 Java 代码写起来太过繁琐,特别是涉及泛型的时候。就像 C++,也基于 auto 关键字引入了类型推导功能。
Java 也计划引入类似特性,语法是这样的:
var list = new ArrayList(); // infers ArrayList
var stream = list.stream(); // infers Stream 该特性只能用于三种场景:
带有初始化信息的局部变量
增强 for 循环中的索引
传统 for 循环中的局部变量
看个复杂点的例子:

对该特性感兴趣的读者可以参考:https://developer.oracle.com/java/jdk-10-local-variable-type-inference 。
JEP 296: Consolidate the JDK Forest into a Single Repository
将 JDK 的多个代码仓库合并到一个代码仓库中。
看过 JDK 代码的应该知道,JDK 的不同功能分布在不同代码仓库中。以 JDK 9 为例,代码仓库有 8 个: root, corba, hotspot,jaxp, jaxws, jdk, langtools 和 nashorn。其中 hotspot 是虚拟机实现代码,jdk 是 Java 类库和相关工具,langtools 是 javac 等工具,nashorn 是 JavaScript 引擎。
JEP 304: Garbage Collector Interface
垃圾收集器接口。
在 hotspot/gc 代码实现方面,引入一个干净的垃圾收集器接口,改进不同垃圾收集器源代码的隔离性。这样添加新的或者删除旧的 GC,都会更容易。
JEP 307: Parallel Full GC for G1
为 G1 垃圾收集器引入并行 Full GC。
JEP 310: Application Class-Data Sharing
Java 之前就引入了类数据共享机制,Class data sharing (CDS) ,以减少 Java 程序的启动时间,降低内存占用。简单来说,Java 安装程序会把 rt.jar 中的核心类提前转化成内部表示,转储到一个共享的文件中(shared archive)。多个 Java 进程(或者说 JVM 实例)可以共享这部分数据。
现在,希望更近一步,支持应用类的数据共享。
JEP 312: Thread-Local Handshakes
修改安全点机制,使得部分回调操作只需要停掉单个线程,而不像以前那样,只能选择或者停掉所有线程,或者都不停止。
JEP 313: Remove the Native-Header Generation Tool (javah)
去掉 javah 工具。
从 JDK 8 开始,javah 的功能已经集成到了 javac 中。所以,javah 可以删掉了。
JEP 314: Additional Unicode Language-Tag Extensions
额外的 Unicode 语言标签扩展。
增强 java.util.Locale 和相关 API,实现 BCP 47 语言标签中额外的 Unicode 扩展。
JEP 316: Heap Allocation on Alternative Memory Devices
在可选内存设备上分配堆内存。
支持将 Java 对象堆分配到 NV-DIMM 等内存设备上。随着 NV-DIMM 越来越便宜,未来的系统可能会搭载异构内存架构。
JEP 317: Experimental Java-Based JIT Compiler
实验性的基于 Java 的 JIT 编译器。
支持基于 Java 的 JIT 编译器。相关工作主要基于 Graal。Graal 也是 Java 9 中引入的 AOT 编译器的基础。
JEP 319: Root Certificates
根证书。
在 JDK 中提供一组默认的根证书。
JEP 322: Time-Based Release Versioning
基于时间的版本字符串。修改 Java SE 平台和 JDK 版本字符串机制。考虑和之前版本号的兼容等问题,新的版本命名机制是: $FEATURE.$INTERIM.$UPDATE.$PATCH
$FEATURE,每次版本发布加 1,不考虑具体的版本内容。(之前的主版本号部分)2018 年 3 月的版本是 JDK 10,9 月的版本是 JDK 11,依此类推。
$INTERIM,中间版本号,在大版本中间发布的,包含问题修复和增强的版本,不会引入非兼容性修改。
Spring+SpringMVC+MyBatis+easyUI整合进阶篇(十四)Redis缓存正确的使用姿势
作者:13
GitHub:https://github.com/ZHENFENG13
版权声明:本文为原创文章,未经允许不得转载。
简介
这是一篇关于Redis使用的总结类型文章,会先简单的谈一下缓存的应用场景、缓存的使用逻辑及注意事项,然后是Redis缓存与数据库间结合以进行系统优化,当然文章的最后也会给出具体的代码实现,不至于看到文章的你一头雾水,理论要讲,项目代码也要分享,这是我写博客的基本出发点。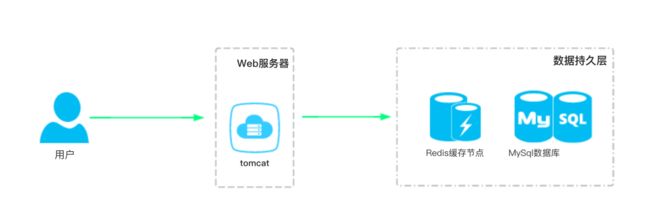
应用场景
Redis能做什么呢?
这是个好问题,不同的人可能会给出不同的答案,因为它的应用场景真的很多,作为一个优秀的nosql数据库可以结合其他产品做很多事情,比如:tomcat集群的session同步、与nginx和lua结合做限流工具、基于Redis的分布式锁实现、分布式系统唯一主键生成策略、秒杀场景中也会看到它、它还能够作为一个消息队列.....
Redis的应用场景很多很多,以上也只是列举了一部分而已,由于本文是围绕我的开源项目perfect-ssm来写的,所以在本文的场景就是一个缓存中间层,对于读多写少的应用场景,我们经常使用缓存来进行优化以提高系统性能。
我曾经写过一篇《一次线上Mysql数据库崩溃事故的记录》的文章,里面记录了Web请求是如何毫不留情的摧垮mysql数据库,进而导致网站应用无法正常运转。当时的情况就是数据库读请求太多,事故的主要原因也是这个,后续的解决方案也就是在项目中添加缓存层,使得热点数据得以存入缓存,不会重复的去读取mysql,将大部分请求压力转移至Redis缓存中以减轻mysql的负担。
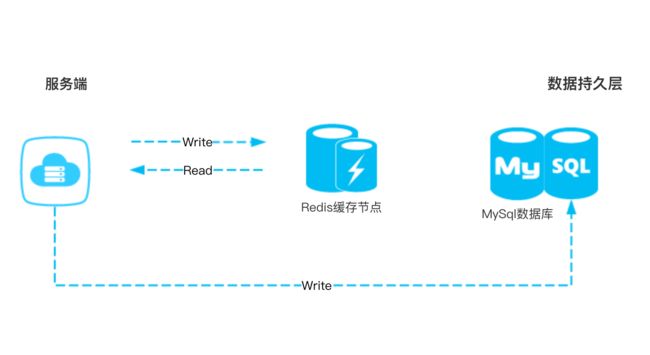
接入缓存后的处理逻辑
请求过来后,首先判断Redis里面有没有,有数据则直接返回Redis中的数据给用户,没有则查询数据库,如果数据库中也没有则返回空或者提醒语句即可。
当然,针对不同的操作,对于Redis和mysql的操作也是不同的:
添加操作
如果是需要放入缓存的数据,那么在向mysql数据库中插入成功后,生成对应的key至,并存入Redis中。
修改操作
向mysql数据库中修改成功后,修改Redis中的数据,但是Redis并没有更新语句,所以只能先删除,再添加完成更新操作。
需要注意的是,考虑到程序对于Redis的操作可能会失败,这时mysql中的数据已经修改,但是Redis中的数据依然是上一次的数据,导致数据不一致的问题,所以是先操作Redis还是先操作mysql需要慎重考虑。
删除操作
与修改操作相同,先删除数据,再更新缓存,但是同样会有出现数据不一致问题的可能性需要注意,如果数据库中的数据删除了,但是Redis中的数据没删除,又会出现业务问题。
查询操作
首先通过Redis查询,如果缓存中已经存在数据则直接返回即可,此时就不再需要通过mysql数据库来获取数据,减少对mysql的请求,如果缓存中不存在数据,则依然通过mysql数据库查询,查询到数据后,存入Redis缓存中。
本项目中的代码是先操作mysql,再操作Redis,有概率会出现上文中提到的数据库与缓存数据不一致的情况,所以需要注意,本文的代码只做参考,用到实际项目中还是需要根据具体的业务逻辑进行合理的修改。
使用缓存的建议
缓存存储策略:
可以缓存的数据的特征基本上是以下几点:
- 热点数据
- 实时性要求不高的数据
- 业务逻辑简单的数据
至于什么数据,不同的系统、不同的项目要求肯定不同,这里不做过多讨论,只简单的说一下自己的想法,结合以上的特征总结如下:
- 1.首页数据、分类数据这些数据属于热点数据,首页数据更是热得发烫,而且这类数据一般实时性不高,不会频繁的去操作,比较适合放入缓存。
- 2.详情数据,比如文章详情、商品详情、广告详情、个人信息详情,这些数据库中单条的的数据可以以其id生成不同的key保存到Redis,操作比较简单明了,在更新或者删除的时候需要同步更新Redis中的数据,这类数据也适合放入缓存中。
- 3.列表数据不是特别推荐,除非是实时性和改变频率真的很低的情况下,因为列表往往牵涉的数据和操作很多,处理起来比较复杂,如果对实时性要求低的话、或者部分字段更新频率低的话,可以换成这部分数据。
缓存存储策略的制定说难也难,说容易也容易,主要是根据具体的业务场景合理的操作即可,以上只是做了一个简单的总结。
缓存失效策略:
失效策略一定要做好,血的教训。
- 定时删除
含义:在设置key的过期时间的同时,为该key创建一个定时器,让定时器在key的过期时间来临时,对key进行删除
优点:保证内存被尽快释放
缺点:
若过期key很多,删除这些key会占用很多的CPU时间,在CPU时间紧张的情况下,CPU不能把所有的时间用来做要紧的事儿,还需要去花时间删除这些key
定时器的创建耗时,若为每一个设置过期时间的key创建一个定时器(将会有大量的定时器产生),性能影响严重
- 惰性删除
含义:key过期的时候不删除,每次从数据库获取key的时候去检查是否过期,若过期则删除,返回null。
优点:删除操作只发生在从数据库取出key的时候发生,而且只删除当前key,所以对CPU时间的占用是比较少的,而且此时的删除是已经到了非做不可的地步(如果此时还不删除的话,我们就会获取到了已经过期的key了)
缺点:若大量的key在超出超时时间后,很久一段时间内,都没有被获取过,那么可能发生内存泄露(无用的垃圾占用了大量的内存)
- 定期删除
含义:每隔一段时间执行一次删除过期key操作
优点:
通过限制删除操作的时长和频率,来减少删除操作对CPU时间的占用--处理"定时删除"的缺点
定期删除过期key--处理"惰性删除"的缺点
缺点
在内存友好方面,不如"定时删除"
在CPU时间友好方面,不如"惰性删除"
难点
合理设置删除操作的执行时长(每次删除执行多长时间)和执行频率(每隔多长时间做一次删除)(这个要根据服务器运行情况来定了)
参考《Redis设计与实现》
缓存操作顺序策略:
在上文中已经讲到了操作顺序的问题,是先操作mysql呢?还是先操作Redis呢?这个需要根据自己的业务逻辑来考量,尽量选择影响较小且结合友好的方案来做。
代码实现:
这里只贴出主要的逻辑代码,想要完整实现的可以到代码仓库去取。
//添加
@Override
public int addArticle(Article article) { if (articleDao.insertArticle(article) > 0) { log.info("insert article success,save article to Redis"); RedisUtil.put(Constants.ARTICLE_CACHE_KEY + article.getId(), article); return 1; } return 0; } //修改 @Override public int updateArticle(Article article) { if (article.getArticleTitle() == null || article.getArticleContent() == null || getTotalArticle(null) > 90 || article.getArticleContent().length() > 50000) { return 0; } if (articleDao.updArticle(article) > 0) { log.info("update article success,delete article in Redis and save again"); RedisUtil.del(Constants.ARTICLE_CACHE_KEY + article.getId()); RedisUtil.put(Constants.ARTICLE_CACHE_KEY + article.getId(), article); return 1; } return 0; } //删除 @Override public int deleteArticle(String id) { RedisUtil.del(Constants.ARTICLE_CACHE_KEY + id); return articleDao.delArticle(id); } //查询 @Override public Article findById(String id) { log.info("get article by id:" + id); Article article = (Article) RedisUtil.get(Constants.ARTICLE_CACHE_KEY + id, Article.class); if (article != null) { log.info("article in Redis"); return article; } Article articleFromMysql = articleDao.getArticleById(id); if (articleFromMysql != null) { log.info("get article from mysql and save article to Redis"); RedisUtil.put(Constants.ARTICLE_CACHE_KEY + articleFromMysql.getId(), articleFromMysql); return articleFromMysql; } return null; }结语
首发于我的个人博客,新的项目演示地址:perfect-ssm,登录账号:admin,密码:123456
如果有问题或者有一些好的创意,欢迎给我留言,也感谢向我指出项目中存在问题的朋友。
如果你想继续了解该项目可以查看整个系列文章Spring+SpringMVC+MyBatis+easyUI整合系列文章,也可以到我的GitHub仓库或者开源中国代码仓库中查看源码及项目文档。
努力的孩子运气不会太差,跌宕的人生定当更加精彩
一直以来,我始终坚信这个理念,努力一定会有收获,如果没有收获或者收获很小的话,那就只能说明你不够努力。其实,只要在这个世界上生存的人,都需要为自己的人生,自己的事业,学业拼搏着,努力着,不努力就会在社会的激烈竞争中被淘汰,任何人都在为之努力奋斗着,谁敢说自己不曾努力呢。曾经有很多粉丝私信我说,你哪里来的这么多的时间去学这些东西。其实啊,你只要愿意去挤,时间总会有的。我只不过是把你们打游戏的时间拿来学习,把你们上课听讲的时间用到学其他领域上面,把你们放假的时间拿来加班,仅此而已。成功并非一蹴而就,需要经历时间的拷打与历练,做一行就要热爱一行,有一颗探索未知的好奇心很重要,找对方法,不懈奋斗,一直不断的坚持下去,你的人生一定会非常的独特与精彩。
曾经也看了@张善友的一篇文章,题为十年微软MVP路(如何成为一个MVP?),他是腾讯的大BOSS级别的人物,到现在为止连续十二年获得微软MVP,算是国内ASP.NET方向上的权威专家了,我们撇开他的成绩不谈,单从他的工作历程来看,十多年来始终坚守在.ASP.NET方向,一直在博客园里向国内的开发社区推广开源技术,没有考虑过换成其他的方向(客观原因是因为有个和他一直并肩作战的开发团队),无私的为这个圈子分享着自己的知识和经验,他荣获MVP头衔定当实至名归,这或许是我一直以来坚持继续写博客,分享自己知识的动力源泉吧。向比你优秀的人看齐,站在比你优秀的人一边,自然而然你也会变得更加优秀。
知识本就有个半衰期,特别是在新型的互联网行业,现在所学的知识,意味着毕业以后,我所学的一半的知识是毫无价值的。在这个行业里面,知道知识的半衰期实际上是件极好的事情,这使你永远不会变成沉舟病树。我们将被迫持续学习新东西,而这对于我们未来的工作和生活会因此收益匪浅。
行业上曾这么说过,说程序员一到40岁就会进入淘汰期。这个确实不假,如果我作为一个CEO,我宁愿是去招聘一些年轻的,薪水要求低的,有活力,创造力,学习能力强的程序员,而并非是需要像这种知识老化,思想固化,不愿去学习,薪水要求很高的老年人,即使他们的编程能力还不错。在这个行业里,仅靠一纸文凭,终将变得毫无价值,老板会把他们像用过的纸巾一样抛弃掉,千万不要变成这样的人。我们能做的就是不断的学习学习再学习,而最好的学习方式无疑是和你的同僚分享知识,经常讨论技术前沿,让你的思维长期处于活跃状态。
曾经也有粉丝私信我说,为什么付出和回报不成正比?原因很简单,有些东西不是光靠努力就能达得到的,个人天赋悟性也是极其的重要。不要总是去责怪老天爷的不公,多去思考自己到底为此付出了多少汗水?社会本来就是不公平的,从高考的那一刻起,多多少少就已经把能力不同的人用一个名叫大学的容器给区分开来。能力强的人被分到985,211的那个容器里面,能力弱的分到所谓的三流学校的容器里面。当录取通知书到来的那一刻起,你应该明白,你不是属于那个能力强的容器里面的人,你只是呆在一个普通的不能再普通的高等院校,为何总是期望予自己能力能够达到甚至超越他们呢?
每每看到粉丝们找我求助、热切地想要改变自己命运的时候,我就想起了曾经的那个我。记得曾经聆听过刘媛媛关于寒门贵子的演说,感受最深的一句话是:命运给你一个比别人低的起点,是想告诉你,让你用你的一生去奋斗出一个绝地反击的故事。我出身寒门,没有哥哥姐姐弟弟妹妹,体弱多病。一直以来,我爸我妈为了供我读书看病,拼死拼活的在外面赚钱。我又何尝不去努力学习呢?小时候我也是非常羡慕别人家的孩子有父母接送,有爷爷奶奶的疼爱,每次放学的时候都是我一个人回家,一个人洗衣做饭,十几年一直是在这种风波摇曳中度过的,可这又有什么办法呢? 我一直也不会拿自己跟那些比如说家庭富裕的小孩做比较,说我们之间有什么不同,或者有什么不平等,但是我们必须要承认这个世界是有一些不平等的,他们有很多优越的条件我们都没有,他们有很多的捷径我们也没有,但是我们不能抱怨。每一个人的人生都不尽相同的,有些人出生就含着金钥匙,有些人出生连爸妈都没有,人生跟人生是没有可比性的,我们的人生是怎么样完全决定于自己的感受。你一辈子都在感受抱怨,那你的一生就是抱怨的一生;你一辈子都在感受感动,那你的一生就是感动的一生;你一辈子都立志于改变这个社会,那你的一生就是斗士的一生。
当我们遭遇失败的时候,我们不能把所有的原因都归结到出生上去,更不能抱怨自己的父母为什么不如别人的父母,因为家境不好,并没有斩断一个人他成功的所有的可能。当我在人生终于到很大的困难的时候,这时候我会去想,我真的是一无所依,我能依靠的只是我自己,我什么都没有,我现在能做的就是单枪匹马的,在这个社会上杀出一条路来,只有自己强大了才能真正的赢得别人的尊重。
我知道很多acmer的苦衷,把大学宝贵的四年时光投入到acm竞赛上,放弃了很多本该可以做的更好的事情上,学业成绩不景气,挂了很多科目,想退坑又不敢退,退了就真的一无所有了。acm是一件快乐的事情,快乐到上瘾;快乐到能够写题写一通宵而不觉得累;快乐到至今也无法忘记登上领奖台紧张到手抖的样子。,不是每个人都是有清北学生的潜质,有的话你也不会沦落至此。不要整天去幻想既要学习成绩优秀,又想在自己喜欢的领域取得优异的成绩,醒醒吧,骚年,现实一点。每个行业都有值得尊敬的地方,并不是有些人的片面观点说,有了acm就有了一切。不管哪个行业,你只要认真的尝试融入进去,你就会发现这个世界真的很大,大到自己都不敢相信。你会看到比自己强的人,他们比你还努力。我的很多朋友,有挂了近20科即将拿不到毕业证的,他们同样是拿到了金牌银牌的,取得了十分优异的成绩,最后同样去了BAT之类的大场子上班,就业前景一点都不比清北毕业的学生差。如果世界上有后悔药,如果老天爷再给你一次选择的机会,我相信大多数人都会选择认真学习。自己选择的路,跪着也要走完。
我不是一位作家,我只是一个在互联网行业爱分享的奋斗小青年。
时2018年5月17日作
优先队列详解(转载)

1 优先队列:顾名思义,首先它是一个队列,但是它强调了“优先”二字,所以,已经不能算是一般意义上的队列了,它的“优先”意指取队首元素时,有一定的选择性,即根据元素的属性选择某一项值最优的出队~
2 百度百科上这样描述的: 3 优先级队列 是不同于先进先出队列的另一种队列。每次从队列中取出的是具有最高优先权的元素 4 优先队列的类定义 5 优先队列是0个或多个元素的集合,每个元素都有一个优先权或值,对优先队列执行的操作有1) 查找;2) 插入一个新元素;3) 删除.在最小优先队列(min priorityq u e u e)中,查找操作用来搜索优先权最小的元素,删除操作用来删除该元素;对于最大优先队列(max priority queue),查找操作用来搜索优先权最大的元素,删除操作用来删除该元素.优先权队列中的元素可以有相同的优先权,查找与删除操作可根据任意优先权进行. 6 优先队列,其构造及具体实现我们可以先不用深究,我们现在只需要了解其特性,及在做题中的用法,相信,看过之后你会收获不少。 7 使用优先队列,首先要包函STL头文件"queue", 8 以一个例子来解释吧(呃,写完才发现,这个代码包函了几乎所有我们要用到的用法,仔细看看吧): 9 view plaincopy to clipboardprint? 10 /*优先队列的基本使用 2010/7/24 dooder*/ 11 #include 12 #include 13 #include 14 #include 15 using namespace std; 16 //定义结构,使用运算符重载,自定义优先级1 17 struct cmp1{ 18 bool operator ()(int &a,int &b){ 19 return a>b;//最小值优先 20 } 21 }; 22 struct cmp2{ 23 bool operator ()(int &a,int &b){ 24 return a<b;//最大值优先 25 } 26 }; 27 //定义结构,使用运算符重载,自定义优先级2 28 struct number1{ 29