外部排序算法相关:主要用到归并排序,堆排序,桶排序,重点是先分成不同的块,然后从每个块中找到最小值写入磁盘,分析过程可以看看http://blog.csdn.net/jeason29/article/details/50474772
hash值算法
1.题目描述
给定a、b两个文件,各存放50亿个url,每个url各占64字节,内存限制是4G,让你找出a、b文件共同的url?
2.思考过程
(1)首先我们最常想到的方法是读取文件a,建立哈希表(为什么要建立hash表?因为方便后面的查找),然后再读取文件b,遍历文件b中每个url,对于每个遍历,我们都执行查找hash表的操作,若hash表中搜索到了,则说明两文件共有,存入一个集合。
(2)但上述方法有一个明显问题,加载一个文件的数据需要50亿*64bytes = 320G远远大于4G内存,何况我们还需要分配哈希表数据结构所使用的空间,所以不可能一次性把文件中所有数据构建一个整体的hash表。
(3)针对上述问题,我们分治算法的思想。
step1:遍历文件a,对每个url求取hash(url)%1000,然后根据所取得的值将url分别存储到1000个小文件(记为a0,a1,...,a999,每个小文件约300M),为什么是1000?主要根据内存大小和要分治的文件大小来计算,我们就大致可以把320G大小分为1000份,每份大约300M(当然,到底能不能分布尽量均匀,得看hash函数的设计)
step2:遍历文件b,采取和a相同的方式将url分别存储到1000个小文件(记为b0,b1,...,b999)(为什么要这样做? 文件a的hash映射和文件b的hash映射函数要保持一致,这样的话相同的url就会保存在对应的小文件中,比如,如果a中有一个url记录data1被hash到了a99文件中,那么如果b中也有相同url,则一定被hash到了b99中)
所以现在问题转换成了:找出1000对小文件中每一对相同的url(不对应的小文件不可能有相同的url)
step3:因为每个hash大约300M,所以我们再可以采用(1)中的想法
http://blog.csdn.net/tiankong_/article/details/77234726
在所有具有性能优化的数据结构中,我想大家使用最多的就是hash表,是的,在具有定位查找上具有O(1)的常量时间,多么的简洁优美,
但是在特定的场合下:
①:对10亿个不重复的整数进行排序。
②:找出10亿个数字中重复的数字。
当然我只有普通的服务器,就算2G的内存吧,在这种场景下,我们该如何更好的挑选数据结构和算法呢?
问题分析
这年头,大牛们写的排序算法也就那么几个,首先我们算下放在内存中要多少G: (10亿 * 32)/(1024*1024*1024*8)=3.6G,可怜
的2G内存直接爆掉,所以各种神马的数据结构都玩不起来了,当然使用外排序还是可以解决问题的,由于要走IO所以暂时剔除,因为我们
要玩高性能,无望后我们想想可不可以在二进制位上做些手脚?
比如我要对{1,5,7,2}这四个byte类型的数字做排序,该怎么做呢?我们知道byte是占8个bit位,其实我们可以将数组中的值作为bit位的
key,value用”0,1“来标识该key是否出现过?下面看图:
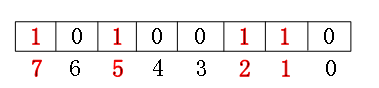
从图中我们精彩的看到,我们的数组值都已经作为byte中的key了,最后我只要遍历对应的bit位是否为1就可以了,那么自然就成有序数组了。
可能有人说,我增加一个13怎么办?很简单,一个字节可以存放8个数,那我只要两个byte就可以解决问题了。
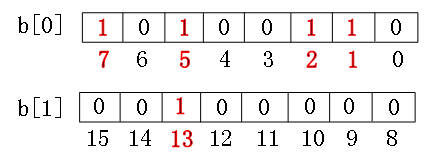
可以看出我将一个线性的数组变成了一个bit位的二维矩阵,最终我们需要的空间仅仅是:3.6G/32=0.1G即可,要注意的是bitmap排序不
是N的,而是取决于待排序数组中的最大值,在实际应用上关系也不大,比如我开10个线程去读byte数组,那么复杂度为:O(Max/10)。
(上面摘自http://www.cnblogs.com/huangxincheng/archive/2012/12/06/2804756.html,省去了代码部分,具体代码分析可见下文)
bitmap算法解释
一、bitmap算法思想
32位机器上,一个整形,比如int a; 在内存中占32bit位,可以用对应的32bit位对应十进制的0-31个数,bitmap算法利用这种思想处理大量数据的排序与查询.
优点:1.运算效率高,不许进行比较和移位;2.占用内存少,比如N=10000000;只需占用内存为N/8=1250000Byte=1.25M。
缺点:所有的数据不能重复。即不可对重复的数据进行排序和查找。
比如:
第一个4就是
00000000000000000000000000010000
而输入2的时候
00000000000000000000000000010100
输入3时候
00000000000000000000000000011100
输入1的时候
00000000000000000000000000011110
思想比较简单,关键是十进制和二进制bit位需要一个map图,把十进制的数映射到bit位。下面详细说明这个map映射表。
二、map映射表
假设需要排序或者查找的总数N=10000000,那么我们需要申请内存空间的大小为int a[1 + N/32],其中:a[0]在内存中占32为可以对应十进制数0-31,依次类推:
bitmap表为:
a[0]--------->0-31
a[1]--------->32-63
a[2]--------->64-95
a[3]--------->96-127
..........
那么十进制数如何转换为对应的bit位,下面介绍用位移将十进制数转换为对应的bit位。
三、位移转换
例如十进制0,对应在a[0]所占的bit为中的第一位:
00000000000000000000000000000001
0-31:对应在a[0]中
i =0 00000000000000000000000000000000
temp=0 00000000000000000000000000000000
answer=1 00000000000000000000000000000001
i =1 00000000000000000000000000000001
temp=1 00000000000000000000000000000001
answer=2 00000000000000000000000000000010
i =2 00000000000000000000000000000010
temp=2 00000000000000000000000000000010
answer=4 00000000000000000000000000000100
i =30 00000000000000000000000000011110
temp=30 00000000000000000000000000011110
answer=1073741824 01000000000000000000000000000000
i =31 00000000000000000000000000011111
temp=31 00000000000000000000000000011111
answer=-2147483648 10000000000000000000000000000000
32-63:对应在a[1]中
i =32 00000000000000000000000000100000
temp=0 00000000000000000000000000000000
answer=1 00000000000000000000000000000001
i =33 00000000000000000000000000100001
temp=1 00000000000000000000000000000001
answer=2 00000000000000000000000000000010
i =34 00000000000000000000000000100010
temp=2 00000000000000000000000000000010
answer=4 00000000000000000000000000000100
i =61 00000000000000000000000000111101
temp=29 00000000000000000000000000011101
answer=536870912 00100000000000000000000000000000
i =62 00000000000000000000000000111110
temp=30 00000000000000000000000000011110
answer=1073741824 01000000000000000000000000000000
i =63 00000000000000000000000000111111
temp=31 00000000000000000000000000011111
answer=-2147483648 10000000000000000000000000000000
浅析上面的对应表:
1.求十进制0-N对应在数组a中的下标:
十进制0-31,对应在a[0]中,先由十进制数n转换为与32的余可转化为对应在数组a中的下标。比如n=24,那么 n/32=0,则24对应在数组a中的下标为0。又比如n=60,那么n/32=1,则60对应在数组a中的下标为1,同理可以计算0-N在数组a中的下标。
2.求0-N对应0-31中的数:
十进制0-31就对应0-31,而32-63则对应也是0-31,即给定一个数n可以通过模32求得对应0-31中的数。
3.利用移位0-31使得对应32bit位为1.
四、编程实现
解析本例中的void set(int i) { a[i>>SHIFT] |= (1<<(i & MASK)); }
1.i>>SHIFT:
其中SHIFT=5,即i右移5为,2^5=32,相当于i/32,即求出十进制i对应在数组a中的下标。比如i=20,通过i>>SHIFT=20>>5=0 可求得i=20的下标为0;
2.i & MASK:
其中MASK=0X1F,十六进制转化为十进制为31,二进制为0001 1111,i&(0001 1111)相当于保留i的后5位。
比如i=23,二进制为:0001 0111,那么
0001 0111
& 0001 1111 = 0001 0111 十进制为:23
比如i=83,二进制为:0000 0000 0101 0011,那么
0000 0000 0101 0011
& 0000 0000 0001 0000 = 0000 0000 0001 0011 十进制为:19
i & MASK相当于i%32。
3.1<<(i & MASK)
相当于把1左移 (i & MASK)位。
比如(i & MASK)=20,那么i<<20就相当于:
0000 0000 0000 0000 0000 0000 0000 0001 >>20
=0000 0000 0000 1000 0000 0000 0000 0000
4.void set(int i) { a[i>>SHIFT] |= (1<<(i & MASK)); }等价于:
void set(int i)
{
a[i/32] |= (1<<(i%32));
}
问题:
解决法案:
遍历法
直接寻址表法
| a | 0 | 1 | 2 | ...... | 1000022 | ..... | 100000030 | ... | 2*32- 1 |
| flag | 0 | 1 | 1 | 1 | 0 | 0 | 1 | 0 | 1 |
Bit-Map
| a | 0 | 1 | ...... | 2*32 / 8- 1 |
| bit | 0 1 2 3 4 5 6 7 | 0 1 2 3 4 5 6 7 | ...... | 0 1 2 3 4 5 6 7 |
| flag | 0 0 0 0 0 0 0 0 | 0 0 1 0 0 0 0 0 | ...... | 0 0 0 0 0 0 0 0 |
BitMap 应用
枚举
1.全组合
字符串全组合枚举(对于长度为n的字符串,组合方式有2^n种),如:abcdef,可以构造一个从字符串到二进制的映射关系,通过枚举二进制来进行全排序。
null --> 000000
f --> 000001
e --> 000010
ef --> 000011
……
abcedf --> 111111
2.哈米尔顿距离
给定N(1<=N<=100000)个五维的点A(x1,x2,x3,x4,x5),求两个点X(x1,x2,x3,x4,x5)和Y(y1,y2,y3,y4,y5),使得他们的哈密顿距离(d=|x1-y1| + |x2-y2| + |x3-y3| + |x4-y4| + |x5-y5|)最大。
搜索
爬虫系统中常用的URL去重(Bloom Filter算法)
压缩
在2.5亿个整数中找出不重复的整数,注,内存不足以容纳这2.5亿个整数?
给40亿个不重复的unsigned int的整数,没排过序的,然后再给一个数,如何快速判断这个数是否在那40亿个数当中?
位排序
(以上摘抄自http://blog.csdn.net/qq_26891045/article/details/51137589)
另:可以看看KMP(字符串匹配算法)