python爬虫(廖雪峰商业爬虫)
文章目录
- day01
- http
- Request Headers
- Response Headers
- 其他
- 爬虫工作原理
- demo
- day02
- 1.get传参
- 2.post请求
- 3.User-Agent:
- 4.IP代理
- 5.IP分类
- 6.handler:处理器的自定义
- demo
- day03
- 添加付费代理
- 访问内网
- day04
- 手动添加cookie
- 自动登陆获取cookie
- 报错类型
- requests库
- day07
- day08
- day09-10
- MongoDB
- day11
- redis
- 数据操作
- day 12
- MySQL
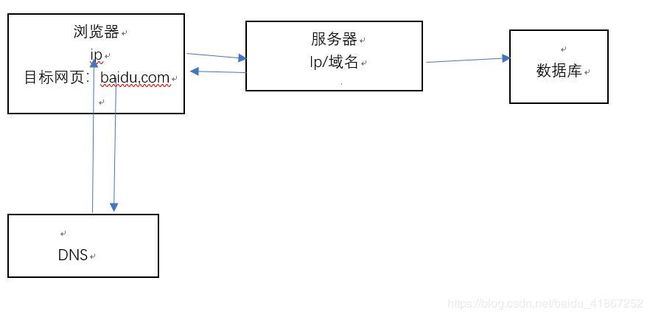
day01
http
hyper text transfer protocol
- 地址栏中输入网址
- 请求方式
(1)get方式 : 便捷;缺点(不安全、明文、账号密 码易泄露,参数长度有限制)
如:https://www.baidu.com/s?wd=http与https图解
(2)post:安全、非明文、数据大小无限制、上传文件(百度云)
注:
发送网络请求需要带(也可不带)一定的数据(放在request headers里)给服务器(返回数据:response)
注:
Request Headers
- Accept:返回的格式
- Accept-Encoding:编码方式,gzip
- Connection:长短连接,leep-alive
- Cookie:缓存,验证用
- Host:域名,www.baidu.com
- Refer:标志从哪个页面跳转来的
- User-Agent:浏览器和用户信息
Response Headers
1.cache-control:缓存大小
2. Date:发送请求的时间
3. Expires:发送请求结束时间
其他
爬虫价值:
- 买卖数据
- 数据分析,出分析报告
- 流量
合法性:
没有法律规定时是否合法或违法(公司概念:公司让爬数据库,窃取机密,责任在公司)
注:不能获取任意数据,只能获取用户可以访问到的;爱奇艺视频(vip和非vip),普通用户只能爬取非vip资源
爬虫分类:
- 通用爬虫:使用搜索引擎;优势:开放性,速度快 劣势:目标不明确
- 聚焦爬虫:又称主题网络爬虫 优势:目标明确,对用户需求精准,返回内容明确
- 增量式:翻页,从第一页到最后一页
robots:
规定是否允许其他爬虫爬取某些内容;聚焦爬虫不遵守robots; 查看方法:www.baidu.com/robots.txt
爬虫与反爬虫作斗争:资源对等时,爬虫胜利
爬虫工作原理
爬虫的步骤:
- 确认目标url
- 使用python代码发送请求获取数据(其他语言也行,go,java)
- 解析数据,得到精确的数据 (找到新的url,回到第一步:循环此步骤直到所有页面都已抓取)
- 数据持久化,保存到本地或数据库
其他知识点:
python3原生模块 urllib.request
a. urlopen 返回response对象;response.read()读出数据.或response.read().decode(‘utf8’)
b. get传参:汉字会报错(解释器的ascii没有汉字,url中的汉字需要转码)
demo
抓取图片并保存
import requests
url = 'https://ss0.baidu.com/73x1bjeh1BF3odCf/it/u=1855917097,3670624805&fm=85&s=C110C5384B62720D4068C5D7030080A3'
r = requests.get(url, timeout=30)
#显示None为正常
print(r.raise_for_status())
r.encoding = r.apparent_encoding
with open('图片.jpg','wb') as fp:
#注意不是r.text
fp.write(r.content)
抓取百度
import urllib.request
def load_data():
url = 'https://www.baidu.com/'
#get请求,http请求
response = urllib.request.urlopen(url)
print(response)
data = response.read()
#发现data为字节串
str_data = data.decode('utf8')
print(str_data)
load_data()
同上
import urllib.request
def load_data():
url = 'http://www.baidu.com/'
#get请求,http请求
response = urllib.request.urlopen(url)
# print(response)
data = response.read()
#发现data为字节串
str_data = data.decode('utf8')
# print(str_data)
#打开的网页是本地的,不能搜索
with open('baidu.html','w',encoding='utf8') as fp:
fp.write(str_data)
#将字符串转换为bytes
str_name = 'hello'
bytes_name = str_name.encode('utf8')
print(bytes_name)
load_data()
get请求
import urllib.request
import urllib.parse
import string
def get_method():
# url = 'https://www.baidu.com/s?wd=%E7%BE%8E%E5%A5%B3'
url = 'http://www.baidu.com/s?wd='
#网致里包含汉字,必须转义,否则报错
name = '美女'
final_url = url+name
# print(final_url)
#使用代码发送网络请求
encode_url=urllib.parse.quote(final_url,safe=string.printable)
print(encode_url)
response = urllib.request.urlopen(encode_url)
print(response)
#读取内容
data = response.read().decode('utf8')
print(data)
with open('meinv.html','w',encoding='utf8') as fp:
fp.write(data)
get_method()
day02
1.get传参
(1)汉字报错:解释器ascii没有汉字,url汉字转码
urllib.parse.quote(url,dafe=string.printabal)
(2)字典传参
urllib.parse.urlencode(url)
2.post请求
urllib.request.urlopen(url,data=“服务器接收的数据”)
3.User-Agent:
1).模拟真实浏览器发送请求(使用场合:百度批量搜索 )
2).如何获取:浏览器的审查元素里,或百度user-agent大全
3).设置方法:request.add_header(动态添加user-agent)
4).响应头:response.headers
4.IP代理
1)免费IP:时效性差,错误率高
2)收费IP:拥有失效不能用的
5.IP分类
1)透明:对方知道我们真实的IP
2)匿名:对方不知道我们真实的IP,但知道使用了代理
3)高匿:对方不知道我们真实的IP,也不道使用了代理
6.handler:处理器的自定义
1)系统的urlopen()不支持添加代理
2)需要创建对应的处理器(handler)
方法:A 代理处理器ProxyHandler(proxy);B 拿着代理处理器创建opener:build_opener();C opener.open(url)发送请求
demo
01
import urllib.request
import urllib.parse
import string
def get_params():
url = 'http://www.baidu.com/s?'
params = {'wd':'中文','key':'zhang','value':'san'}
#冒号变成=
str_params = urllib.parse.urlencode(params)
print(str_params)
final_url = url+str_params
print(final_url)
# 有了urllib.parse.urlencode(),可以省略此步
end_url = urllib.parse.quote(final_url,safe=string.printable)
print(end_url)
response = urllib.request.urlopen(end_url)
data = response.read().decode()
print(data)
get_params()
02
import urllib.request
def load_baidu():
url = 'http://www.baidu.com'
#创建请求对象
request = urllib.request.Request(url)
# print(request.headers)
response = urllib.request.urlopen(request)
data = response.read().decode('utf8')
# 响应头
# print(response.headers)
#获取请求头信息
request_headers = request.headers
print(request_headers)
with open('02_baidu.html','w',encoding='utf8') as fp:
fp.write(data)
load_baidu()
03
import urllib.request
def load_baidu():
url = 'https://www.baidu.com'
header = {
"User-Agent":'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36 QIHU 360SE',
"haha":"jeje"
}
# 创建请求对象
request = urllib.request.Request(url,headers=header)
# 动态添加
# request = urllib.request.Request(url)
# request.add_header("User-Agent",'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36 QIHU 360SE')
# print(request.headers)
response = urllib.request.urlopen(request)
data = response.read().decode('utf8')
# 获取完整的url
final_url = request.get_full_url()
print(final_url)
# 响应头
# print(response.headers)
# 获取请求头信息
#打印所有头的信息
request_headers = request.headers
print(request_headers)
# 第二种方式打印头信息,注意:首字母大写,其余小写
request_headers2 = request.get_header('User-agent')
print(request_headers2)
with open('02_baidu.html','w',encoding='utf8') as fp:
fp.write(data)
load_baidu()
04
import urllib.request
import random
def load_baidu():
url = 'http://www.baidu.com'
user_agent_list =[
'Mozilla/5.0(Macintosh;U;IntelMacOSX10_6_8;en-us)AppleWebKit/534.50(KHTML,likeGecko)Version/5.1Safari/534.50',
'Mozilla/5.0(Windows;U;WindowsNT6.1;en-us)AppleWebKit/534.50(KHTML,likeGecko)Version/5.1Safari/534.50',
'Mozilla/4.0(compatible;MSIE8.0;WindowsNT6.0;Trident/4.0)',
'Mozilla/5.0(WindowsNT6.1;rv:2.0.1)Gecko/20100101Firefox/4.0.1'
]
request = urllib.request.Request(url)
# 每次使用不同浏览器请求
random_user_agent = random.choice(user_agent_list)
request.add_header('User-Agent',random_user_agent)
# 请求数据
response = urllib.request.urlopen(request)
print(request.get_header('User-agent'))
load_baidu()
05
import urllib.request
def handler_opener():
# urllib.request.urlopen()没有添加代理的功能,需要自定义
# http 80端口 https 443端口
# urlopen为什么可以请求数据:handler处理器;opener请求数据
url = 'https://blog.csdn.net/apassion1/article/details/5807039'
# 创建处理器
handler = urllib.request.HTTPHandler()
# 创建opener
opener = urllib.request.build_opener(handler)
# 利用自己的opener请求数据
response = opener.open(url)
data = response.read().decode()
print(data)
handler_opener()
06
import urllib.request
def create_proxy_handler():
url = 'https://blog.csdn.net/baidu_41867252/article/details/86821355'
# 添加代理
proxy = {
# 免费的代理
# 'http':'http://125.123.140.120:9999'
#或
'http':'125.123.140.120:9999'
}
#代理处理器
proxy_handler = urllib.request.ProxyHandler(proxy)
#创建opener
opener = urllib.request.build_opener(proxy_handler)
#用代理IP发送请求
data = opener.open(url).read().decode()
print(data)
create_proxy_handler()
07
import urllib.request
def proxy_user():
url = 'https://blog.csdn.net/baidu_41867252/article/details/86821355'
proxy_list = [
{'http':'125.123.140.120:9999'},
{'http':'59.62.164.83:9999'},
{'http':'59.62.167.172:5312'},
{'http':'162.105.87.211:8118'},
{'http':'110.52.235.197:9999'}
]
for proxy in proxy_list:
print(proxy)
proxy_handler = urllib.request.ProxyHandler(proxy)
opener = urllib.request.build_opener(proxy_handler)
try:
data = opener.open(url, timeout=1).read().decode()
print('haha')
except Exception as e:
print(e)
day03
添加付费代理
第一种方式 :
money_proxy = {
'http':'username:[email protected]:8080'
}
handler = urllib.request.ProxyHandler(money_proxy)
opener =urllib.request.build_opener(handler)
opener.open(url)
第二种方式:
username = 'abc'
pwd = '123'
proxy_money = '128.98.45.32:8888'
#创建密码管理器
password_manager = urllib.request.HTTPPasswordMgrWithDefaultRealm()
password_manager.add_password(realm=None, uri=proxy_money, user=username, passwd=pwd)
handler_auth = urllib.request.ProxyBasicAuthHandler(password_manager)
opener = urllib.request.build_opener(handler_auth)
response = opener.open(url)
访问内网
user = 'admin'
pwd = '123'
nei_url = 'http://192.168.12.64'
#创建密码管理器
pwd_manager = urllib.request.HTTPPasswordMgrWithDefaultRealm()
pwd_manager.add_password(None,nei_url,user,pwd)
#创建认证处理器
auth_handler = urllib.request.HTTPBasicAuthHandler(pwd_manager)
opener = urllib.request.build_opener(auth_handler)
response = opener.open(nei_url)
day04
手动添加cookie
为获取个人中心的信息,复制cookie,放在请求头里
header = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36',
'Cookie':'cna=tuxEE3P7Ah4CATsurIJv/hNX; thw=cn; miid=82973328358325713; hng=CN%7Czh-CN%7CCNY%7C156; enc=kRhiJJnvm93D0rrXU7wRBAaqd%2FIu5LOUzL12ixGWG7mDUwOyqHNGcPQhxt%2BpZYJvk7OKyIoTwXjjdWJS7nXYpw%3D%3D; UM_distinctid=168d4da25ce206-02459feb9-3b664008-1fa400-168d4da25cf36b; v=0; _tb_token_=eb3533565b383; unb=652498984; sg=54b; t=d67352809c9dfb1dc94c606e4d904faf; _l_g_=Ug%3D%3D; skt=0457744f2cebfa42; cookie2=59fbade39ff2795b3bae1040d518612d; cookie1=ACi9bWtE9Swd%2B7nwwIWMZefTwl6qKUcepd4lYB%2B9GhY%3D; csg=d905bd39; uc3=vt3=F8dByEzaZ25JtIrFM94%3D&id2=VWojfdPOsPRO&nk2=FPjanhY%2Fn9CxQYviMZUN&lg2=WqG3DMC9VAQiUQ%3D%3D; existShop=MTU1MDgzNDUxNg%3D%3D; tracknick=wangmin69323585; lgc=wangmin69323585; _cc_=V32FPkk%2Fhw%3D%3D; dnk=wangmin69323585; _nk_=wangmin69323585; cookie17=VWojfdPOsPRO; tg=0; mt=ci=9_1; ubn=p; ucn=unshyun; l=bBSQZo7cvM7X8RE2BOfalurza77OwIRb4PVzaNbMiICPOafeSQ1lWZZhyqLwC3GVw1YpR3JY9i9vBeYBqSf..; isg=BH9_ASiVH9kGVR1_dokonvm8DlMJZNMGQCRZRRFMpi51IJ-iGTF1VsqyYrB7fat-; uc1=cart_m=0&cookie14=UoTZ5OgAB6aJAA%3D%3D&lng=zh_CN&cookie16=U%2BGCWk%2F74Mx5tgzv3dWpnhjPaQ%3D%3D&existShop=true&cookie21=VT5L2FSpdet1EftGlDZ1Vg%3D%3D&tag=8&cookie15=UtASsssmOIJ0bQ%3D%3D&pas=0'
}
#构建请求对象
request = urllib.request.Request(url,headers=header)
自动登陆获取cookie
1.代码登陆,登陆成功得到有效的cookie
1.1 登陆的网址
1.2 登陆的参数
1.3发送登陆请求 post
2.自动带着cookie去请求个人中心
报错类型
两个错误类型:HTTPError(URLError的子类) URLError
try:
response = urllib.request.urlopen(url)
except urllib.request.HTTPError as error:
print(error.code)
except urllib.request.URLError as error:
print(error)
except :
print('其他错误')
requests库
优点:
简单易用
url自动转译
python2 python3 代码一样,无需修改
发送get请求:
requests.get(url)
#content属性,返回类型是bytes
data = response.content.decode('utf-8')
#text属性,返回字符串,编码为空,会进行推测
data = response.text
各种属性
# 1.获取请求头
request_headers = self.response.request.headers
print(request_headers)
# 2.获取响应头
response_headers = self.response.headers
print(response_headers)
# 3.响应状态码
code = self.response.status_code
print(code)
# 4.请求的cookie
request_cookie = self.response.cookies
print(request_cookie)
# 5.响应的cookie
response_cookie = self.response.cookies
print(response_cookie)
# 6.实际请求的url
url = self.response.url
print(url)
地址拼接
url = 'https://www.baidu.com/s?'
params = {'wd':'美女'}
headers = {
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Mobile Safari/537.36'
}
response = requests.get(url ,headers=headers,params=params)
r.json()将json字符串转换成python的字典或列表
day07
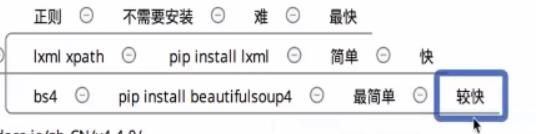
- 正则,xpath,bs4对比
-XML与HTML
XML是JSON前身,数据交互格式, < k e y > v a l u e < / k e y > <key>value</key> <key>value</key>形式,比JSON要重量级(一对尖括号)
HTML用来展示数据,有固定的标签,经过浏览器渲染展示给用户看
day08
day09-10
MongoDB
- 显示所有的数据库
show dbs 或
show databases
admin 0.000GB
config 0.000GB
local 0.000GB
-
启动
mongod.exe --dbpath E:\mongodb\data\db
或
管理员权限 net start mongodb -
连接
命令行输 mongo -
使用某数据库
use 库名
可使用未创建的数据库(后期加入数据,就创建成功了) -
显示当前数据库
db -
查看所有的集合(mysql里称为表)
show collections -
增删查改
1
use student
stu = {name:‘Tom’, age:20, gender:‘male’}
db.student.insert(stu)
或
db.student.insert({name:‘Tom’, age:20, gender:‘male’})
2
db.student.find() 查看所有 或 db.student.find({})
db.student.findOne() 查看所第一条 大写的O
db.stu.find({name:‘张三’}) 条件查找(所有叫张三的人)
db.stu.findOne({name:‘张三’}) 条件查找(一个叫张三的人)
比较运算
< < < $lt
≤ \le ≤ $lte
> > > $gt
≥ \ge ≥ $gte
≠ \neq ̸= $ne
db.stu.find({age:{$gt:12}})
逻辑运算
$and
$ or
db.stu.find({ $and:[{_id:{$gte:2}},{gender:true}]})
等价于
db.stu.find({_id:{$gte:2},gender:true})
找出id ≥ \ge ≥ 2或age=54的男性
db.stu.find({$or:[{_id:{$gte:2}},{age:54}],gender:true})
等价于
db.stu.find({$and:[{$or:[{_id:{$gte:2}},{age:54}]},{gender:true}]})
范围运算
$in
$nin
db.stu.find({_id:{$in:[1,0]}}) 取出id为0或1的人
正则
db.stu.find({name:{$regex:'张'}})) 找出名字中含李的人
等价于
db.stu.find({name:/张/})
db.stu.find({name:/a/}) 找出名字中含a的人 或
db.stu.find({name:{$regex:'a'}})
db.stu.find({name:/a/i}) 忽略大小写 或
db.stu.find({name:{$regex:'a',$options:'i'}})
定义函数
找出年龄大于等于18的
db.stu.find(
{
$where:function()
{
return this.age>=18
}
})
3
a=db.student.findOne()
a.name=‘Tom1’
db.student.update({name:‘Tom’}, {name:‘Tom1’})
结果变成 {name:‘Tom1’)
db.student.update({name:‘Tom’},a)
结果变成 {name:‘Tom1’, age:20, gender:‘male’})
a.career=‘teacher’
db.student.update({name:‘Tom1’},a)
结果变成 {name:‘Tom1’, age:20, gender:‘male’, career=‘teacher’})
db.abc.update({_id:1},{$set:{name:'xiaowang’}}) 仅变动姓名其他不变
db.abc.update({gender:true},{$set:{age:66}}) 结果只修改了一处
db.abc.update({gender:true},{$set:{age:45}},{multi:true}) 所有男性的年龄都改为45
db.stu.update({_id:1},{$unset:{gender:’’}}) 仅删除此行的gender
4
db.student.remove({name:‘Tom1’}) 删除name为Tom1(只有一个)的那一行
db.student.remove({name:‘Tom1’},{justOne:true}) 删除符合条件的一个数据(默认删除所有)
db.student.remove({}) 删除所有
-
新建集合
use newdb (新数据库)
show collections 显示空
db.createCollection(‘newname’)
show collections 显示newname或
db.newname2.insert({name;‘tom’}) 插入数据后自动创建该集合 -
删除数据库
use newdb
db.dropDatabase() -
删除集合
use newdb
show collections 显示abc
sb.abc.drop() -
存储类型
ObjectId
string
array
timestamp
Boolean
object
date
double
integer -
查询结果显示
显示前几行
db.stu.find().limit(2) 显示前2行
显示跳过前几行后的结果
db.stu.find().skip(3)
混合使用
跳过前2行后,看3个
db.stu.find().skip(2).limit(3)
db.stu.find().limit(3).skip(2) 结果同上。优先执行skip
仅查看部分字段(投影)(没有特殊的方法)
db.stu.find({},{name:1,age:1}) 或
db.stu.find({},{name:true,age:1})
统计
db.stu.find({age:18}).count() 年龄18的个数 或
db.stu.count({age:18})
db.stu.count() 查询数据库总共有多少条数据
排序
db.stu.find().sort({age:1}) 按年龄升序
db.stu.find().sort({age:-1}) 按年龄降序
db.stu.find().sort({age:1,_id:-1}) 年龄相同时按id降序
去重
db.stu.distinct('age',{})
db.stu.distinct('age',{_id:{$gt:6}})
db.stu.distinct('name',{})
复合查询
(1) aggregate 聚合查询
db.stu.aggregate([
{管道1},
{管道2}
])
(2) $group 分组
表达式 $sum $avg $first $last $max $min $push
分组求年龄之和
db.stu.aggregate([{$group:{_id:'$gender',sum:{$sum:'$age'}}}])
分组求年龄平均
db.stu.aggregate([{$group:{_id:'$gender',ave:{$avg:'$age'}}}])
分组求年龄最大值
db.stu.aggregate([{$group:{_id:'$gender',maximum:{$max:'$age'}}}])
分组求年龄第一次出现的
db.stu.aggregate([{$group:{_id:'$gender',first:{$first:'$age'}}}])
分组求年龄最后一次出现的
db.stu.aggregate([{$group:{_id:'$gender',last:{$last:'$age'}}}])
分组求各自喜欢的(push所有放在一起)
db.stu.aggregate([{$group:{_id:'$gender',like_animal:{$push:'$like'}}}])
$match == find
宠物是狗的人有哪些
db.stu.find({like:'dog'})
db.stu.aggregate({$match:{like:'dog'}})
年龄大于20岁的男女的平均值
db.stu.aggregate([{$match:{age:{$gt:20}}},{$group:{_id:'$gender',average:{'$avg':'$age'}}}])
$project 投影,显示的字段,显示1或true
求年龄小于40,按爱好分组,求年龄之和,及平均值
db.stu.aggregate([{$match:{age:{$lt:40}}},
{$group:{_id:'$like',average:{'$avg':'$age'},sum:{$sum:'$age'}}}])
求年龄小于40,按爱好分组,求年龄之和,及平均值,只显示平均值
db.stu.aggregate([{$match:{age:{$lt:40}}},
{$group:{_id:'$like',average:{'$avg':'$age'},sum:{$sum:'$age'}}},
{$project:{average:1}}
])
$sort排序
按年龄降序
db.stu.aggregate([{$sort:{age:-1}}])
求年龄小于40,按爱好分组,求年龄之和,及平均值,只显示平均值,降序
db.stu.aggregate([{$match:{age:{$lt:40}}},
{$group:{_id:'$like',average:{'$avg':'$age'},sum:{$sum:'$age'}}},
{$project:{average:1}},
{$sort:{average:-1}}
])
$skip 跳过
$limit 限制个数
两者顺序有影响
db.stu.aggregate([
{$skip:1},
{$limit:2}
])
db.stu.aggregate([
{$limit:2},
{$skip:1},
])
db.stu.aggregate([
{$match:{age:{$lt:40}}},
{$group:{_id:'$like',average:{'$avg':'$age'},sum:{$sum:'$age'}}},
{$project:{average:1}},
{$sort:{average:-1}},
{$skip:1},
{$limit:2}
])
$unwind 拆分列表
男女分组后,所有人的名字
db.stu.aggregate([
{$group:{_id:'$gender',allname:{$push:'$name'}}}
])
男女分组后,各自的名字
db.stu.aggregate([
{$group:{_id:'$gender',allname:{$push:'$name'}}},
{$unwind:'$allname'}
])
年龄小于60,男女分组,取出喜欢的宠物,拆分文档
db.stu.aggregate([
{$match:{age:{$lt:60}}},
{$group:{_id:'$gender',animals:{$push:'$like'}}},
{$unwind:'$animals'}
])
-
注
_id 是主键
mongodb属于文档型数据库 -
查询效率
批量插入数据
for (var i=1;i<=500000;i++){
db.data.insert({
_id:i,
user:'user'+i,
age:i%20
})
}
28ms
db.data.find({_id:333333}).explain('executionStats')
224ms
db.data.find({user:'userr333333'}).explain('executionStats')
201ma
db.data.find({age:333333%20}).explain('executionStats')
设置某个key为索引,提高查询速度
db.data.ensureIndex({age:1})
db.data.ensureIndex({user:1})
查看索引
db.data.getIndexes()
删除索引
db.data.dropIndex('key_1')
db.data.dropIndex('user_1') 名称由user变成user_1
db.data.dropIndex('age_1') 名称由age变成age_1
数据库备份
mongodump -h 127.0.0.1:27017 -d three -o E:\360Downloads\backup
数据库恢复
(路径需具体到库名)
mongorestore -h 127.0.0.1:27017 -d four --dir E:\360Downloads\backup\three
导出文件
mongoexport -h 127.0.0.1:27017 -d four -c stu -o data.json (恢复到当前文件夹)
mongoexport -h 127.0.0.1:27017 -d four -c stu -o E:\360Downloads\backup\three\data.json
mongoexport -h 127.0.0.1:27017 -d four -c stu -o E:\360Downloads\backup\three\data.csv --type csv -f _id,name
导入文件
mongoimport -h 127.0.0.1:27017 -d five -c student --file E:\360Downloads\backup\three\data.json
mongoimport -h 127.0.0.1:27017 -d five -c student --file E:\360Downloads\backup\three\data.csv --type csv -f _id,name
结论:查询主键耗时最短
day11
与python交互
- 启动mongodb
mongo_py = pymongo.MongoClient()
增:
insert_one()
insert_many)
删:
delete_one()
delete_many()
改:
update_one()
update_many()
查:
find_one()
find()
不存在find_many
redis
基于内存的key-value型数据库
启动服务端
redis-server
注:先添加环境变量;此命令提示框不能关
启动客户端
redis-cli
清空所有数据库
flushall
清空当前数据库
flushdb
查看所有的键
keys *
查看含y的键:
keys *y* 含y的键
keys *y 以y结尾的键
keys y* 以y开头的键
查看键是否存在
exists two
exists one
设置过期时间(所有键都能用)
expire key time 单位为秒
expire one 10
expire two 30
注:共有16个数据库,编号0~15
选择数据库
select 0
数据操作
1.字符串string(一个string类型最大能容512M)
增加:set (一次增加一个), mset(一次增加多个)
读取 :get mget
设置过期时间:setex key time value
追加写:append key value
set one 1
set two 2
get one
get two
mset one 1 two 2 three 3
mget one two three
setex one 5 abc
append two 456 (two之前为2)(之后为2456)
2.hash(存对象)
- 存对象和属性值
- 最终存在硬盘内,只是在内存中存在过一段时间
存:hset key field value (单个属性)
hmset key field value field value … (多个属性)
取:hget key field
hmget key field field …
查看字段:hkeys key
查看值:hvals key
删除属性:hdel key field field (属性可一个可多个)
hset person name zhangsan
hset person age 18
hset person gender
hget person name
hget person age
hget person gender
hmset student name xiaoming age 18 gender true
hmget student name age gender
hkeys person
hkeys student
hvals person
hvals student
hdel person age name
- list
- 存: lpush key value value …(新加的在左侧)(l代表left)(从左往右推)
rpush key value value …(新加的在右侧)(从右往左推) - 取:lrange key start end (l代表list)
- 删:lpop 从左删一个
rpop 从右删一个 - 插入:linsert key before/after pivot value
- 下标修改:lset key index value
- 删除:lrem key count value
count > 0 : 从表头开始向表尾搜索,移除与 VALUE 相等的元素,数量为 COUNT 。
count < 0 : 从表尾开始向表头搜索,移除与 VALUE 相等的元素,数量为 COUNT 的绝对值。
count = 0 : 移除表中所有与 VALUE 相等的值。
lpush one 1 2 3
lpush one 4 5 6
lrange one 0 -1
lpop one
rpop one
linsert one after 1 A
linsert one before 3 B
lset one 2 B
lrem one 2 3 (删除2个3)
- 注:查看key 的类型 使用 type key
删除键,del key key
type one
type two
del one two
- set
无序性、互异性
添加:sadd key member member …
查看:smembers key
删除:srem key member …
成员检测:sismember key member (属于返回1,否则0
sadd setone 3 1 4 5 9 2 6
smembers setone
srem setone 3 1
sismember setone 2
- zset
有序集合
增加:zadd key score memberr …(score 代表权重
查看:zrange key start stop
根据权重筛选值:zrangebyscore key min max
查看值的权重:zscore key member
删除:zrem key member …
按权值范围删除:zremrangebyscore key min max
zadd one 1 a 3 b 4 c 2 d
zrange one 0 -1
zrangebyscore one 2 4
zscore one a
zrem one a b
zremrangebyscore one 5 9
day 12
MySQL
默认端口号:3306
服务名: MySQL80
账号密码:root root
-
E-R模型
Entity Relationship 实体关系模型
E代表“表”,表之间存在关系(1对1,1对多,多对多) -
三范式
1NF:字段不可分;
例如:联系人表(姓名,电话),一个联系人有家庭电话和公司电话,则不符合1NF,应拆分为(姓名,家庭电话,公司电话).
2NF:有主键,非主键字段依赖主键;
3NF:非主键字段不能相互依赖,只能依赖主键; -
字段类型
int decimal 数字
char varchar text 字符串
datetime 日期
bit 二进制的位 0或1
注:char(M)类型的数据列里,每个值都占用M个字节,如果某个长度小于M,MySQL就会在它的右边用空格字符补足.(在检索操作中那些填补出来的空格字符将被去掉)在varchar(M)类型的数据列里,每个值只占用刚好够用的字节再加上一个用来记录其长度的字节(即总长度为L+1字节) -
约束
primary key 主键
not null 非空(必须有值)
unique 唯一
default 默认
foreign key 外键 -
删除
物理删除:从磁盘上真正删除
逻辑删除:删除标识 0 1 -
查看版本
select version(); -
查看时间
select now(); -
数据库的基本操作
显示所有数据库
show databases;
使用某数据库
use test1;
查看其中包含的表
show tables;
查看表中所有的信息
select * from new_table1;
删除数据库、
drop database stu;
查看当前使用的数据库
select database();
创建数据库
create database dog charset=utf8; -
表操作
建表
create table dog (
id int auto_increment primary key,
name varchar(10) not null,
gender bit default 0
);
查看表的字段类型
desc dog;
增加字段
alter table dog add age int;
删除字段
alter table dog drop age;
修改字段
alter table dog change age age varchar(12); (name输入两次)修改数据类型
alter table dog change age ageage int(10); 修改名称
alter table dog change ageage age int(12); 修改名称和数据类型
修改表名
rename table dog to cat;
查看建表语句
show create table dog;
删表
表不在,库仍然在,区别于mongodb
drop table dog;
- 数据操作
插入
insert into dog values(1,'拉布拉多',0); 全列插入
insert into dog values(2,'金毛',1);
insert into dog(name) values('田园犬'); 自增用法,缺省插入
若主键自增,可以写0占位实现全列插入
insert into dog values(0,'拉布拉多',0);
插入多条数据
insert into dog values(9,'gou2',1),(12,'gou3',0);
insert into dog(name) values('fou1'),('gou2'),('gou3'),('gou4'); 缺省插入多个
查询
select * from dog;
修改
update dog set name='泰迪' where id=16; 把id为16处的name改为‘泰迪’
删除
delete from dog where name='gou2'; 删除所有name为gou2的项
delete from dog where id=17;
逻辑删除 没有真正删除
alter table dog add isdelete bit;
update dog set isdelete=1 where id=9;