YOLOv4 详解版!一句话总结:速度差不多的精度碾压,精度差不多的速度碾压!
关注
点击关注上方![]() “AI深度视线”,并“星标”公号
“AI深度视线”,并“星标”公号
技术硬文,第一时间送达!
精彩内容
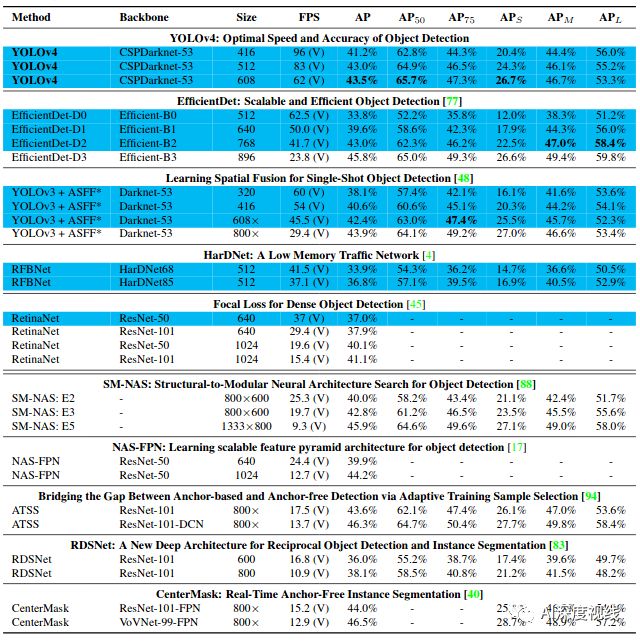
YOLOv4来了!43.5%mAP+65FPS 精度速度最优平衡, 各种调优手段释真香!
作者团队:Alexey Bochkovskiy&中国台湾中央研究院
论文链接:
https://arxiv.org/pdf/2004.10934.pdf
代码链接:
https://github.com/AlexeyAB/darknet
这个很重要!预训练模型 + 作者训练好的模型 链接:
YOLOV4 预训练模型 yolov4.conv.137 + yolov4-weights 网盘链接
1 Introduction

/可以说有许多技巧可以提高卷积神经网络(CNN)的准确性,但是某些技巧仅适合在某些模型上运行,或者仅在某些问题上运行,或者仅在小型数据集上运行;我们来码一码这篇文章里作者都用了哪些调优手段:
-
加权残差连接(WRC)
-
跨阶段部分连接(CSP)
-
跨小批量标准化(CmBN)
-
自对抗训练(SAT)
-
Mish激活
-
马赛克数据增强
-
CmBN
-
DropBlock正则化
-
CIoU Loss
有没有被惊到!
经过一系列的堆料,终于实现了目前最优的实验结果:43.5%的AP(在Tesla V100上,MS COCO数据集的实时速度约为65FPS)。
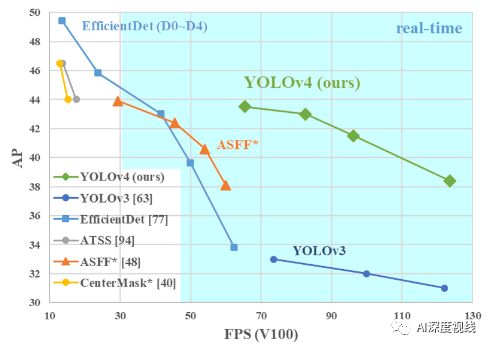
这篇文章的贡献如下:
-
开发了一个高效、强大的目标检测模型。它使每个人都可以使用1080 Ti或2080 TiGPU来训练一个超级快速和准确的目标探测器。
-
验证了在检测器训练过程中,最先进的Bag-of-Freebies和Bag-of-Specials 的目标检测方法的影响。
-
修改了最先进的方法,使其更有效,更适合于单GPU训练,包括CBN、PAN、SAM等。
总之一句话:速度差不多的精度碾压;精度差不多的速度碾压。
2 Relate Works
作者对现有目标检测算法进行了总结: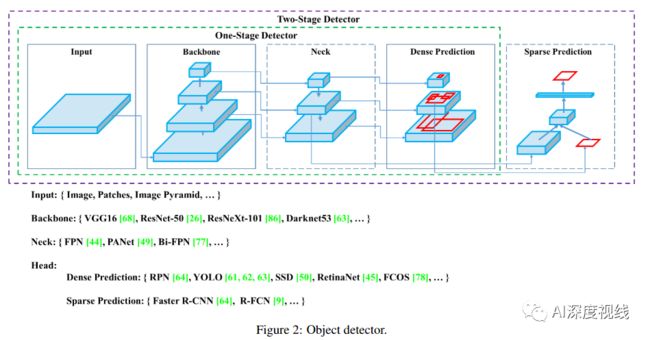
目前检测器通常可以分为以下几个部分,不管是two-stage还是one-stage都可以划分为如下结构,只不过各类目标检测算法设计改进侧重在不同位置:

作者把所有的调优手段分为了两大类“Bag of freebies(免费礼包)”和“Bag of specials(特价包)”,细品 还真形象。
-
Bag of freebies
是指在离线训练阶段为了提升精度而广泛使用的调优手段,而这种技巧并不在推断中使用,不会增加推断时间。
-
数据类:
数据增强(random erase/CutOut/hide-and-seek/grid mask/MixUp/CutMix/GAN)
数据分布:two-stage的有难例挖掘,one-stage的有focal loss。
-
特征图类:
DropOut/DropConnect/DropBlock
-
Bounding Box目标函数类:
MSE/ IoU loss/l1、l2 loss/GIoU loss/DIoU loss/CIoU loss
-
Bag of specials
是指在推断过程中增加的些许成本但能换来较大精度提升的技巧。
-
增大感受野类:
SPP/ASPP/RFB
-
注意力类:
Squeeze-and-Excitation (SE)/Spa-tial Attention Module (SAM)
-
特征集成类:
SFAM/ASFF/BiFPN
-
激活函数类:
ReLu/LReLU/PReLU/ReLU6/Scaled ExponentialLinear Unit (SELU)/Swish/hard-Swish/Mish
-
后处理类:
soft NMS/DIoU NMS
3 YOLOv4 Method
3.1 架构选择

作者选择架构主要考虑几方面的平衡:输入网络分辨率/卷积层数量/参数数量/输出维度。
一个模型的分类效果好不见得其检测效果就好,想要检测效果好需要以下几点:
-
更大的网络输入分辨率——用于检测小目标
-
更深的网络层——能够覆盖更大面积的感受野
-
更多的参数——更好的检测同一图像内不同size的目标
假设符合上面几点要求的backboone就是预期的backbone,作者对CSPResNext50和CSPDarknet53进行了比较,如表1所示,表明CSPDarknet53神经网络是作为目标检测backbone的最优选择。
为了增大感受野,作者使用了SPP-block,使用PANet代替FPN进行参数聚合以适用于不同level的目标检测。
最终YOLOv4的架构出炉:
-
backbone:CSPResNext50
-
additional block:SPP-block
-
path-aggregation neck:PANet
-
heads:YOLOv3的heads
3.2 BoF(免费礼包)和BoS(特价包)的选择
CNN常用的通用技巧:

-
对于训练激活函数,由于PReLU和SELU更难训练,而ReLU6是专门为量化网络设计的,因此将上述其余激活函数从候选列表中删除。
-
在reqularization方法上,发表Drop-Block的人将其方法与其他方法进行了详细的比较,其regularization方法取得了很大的成果。因此,作者毫不犹豫地选择DropBlock作为regularization方法。
-
在归一化方法的选择上,由于关注的是只使用一个GPU的训练策略,所以没有考虑syncBN。
3.3 其他改进
为了使设计的检测器更适合于单GPU上的训练,作者做了如下的附加设计和改进:
-
介绍了一种新的数据增强Mosaic法和Self-AdversarialTraining
自对抗训练法。 -
应用遗传算法选择最优超参数。
-
改进SAM,改进PAN,和交叉小批量标准化(CmBN),使我们的设计适合于有效的训练和检测
-
Mosaic法
是一种将4张训练图片混合成一张的新数据增强方法,这样可以丰富图像的上下文信息。如下图所示:

这种做法的好处是允许检测上下文之外的目标,增强模型的鲁棒性。此外,在每一层从4个不同的图像批处理标准化计算激活统计,这大大减少了对大mini-batch处理size的需求。
-
AdversarialTraining自对抗训练
这是一种新的数据扩充技术,该技术分前后两个阶段进行。
在第一阶段,神经网络改变原始图像而不是网络权值。通过这种方式,神经网络对自身执行一种对抗性攻击,改变原始图像,从而造成图像上没有目标的假象。
在第二阶段,训练神经网络对修改后的图像进行正常的目标检测。
-
CmBN
表示CBN的修改版本,如下图所示,定义为跨微批量标准化(CmBN)。这仅收集单个批中的小批之间的统计信息。
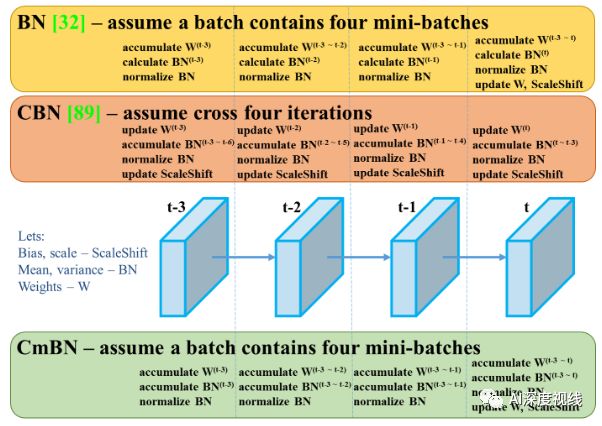
-
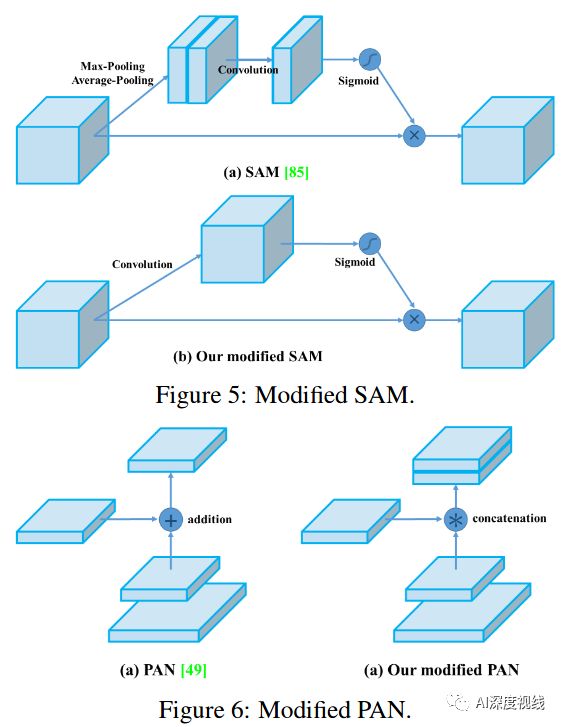
SAM改进
将SAM从空间上的attention修改为点上的attention,并将PAN的short-cut连接改为拼接,分别如图5和图6所示:
3.4 YOLOv4架构总结
-
YOLOv4 架构:
Backbone: CSPDarknet53
Neck: SPP [25], PAN
Head: YOLOv3
-
YOLOv4 使用的调优技巧:
BoF:
backbone:CutMix和mosaic数据增强,DropBlock正则化,类标签平滑。
detector:ciu -loss,CmBN, DropBlock正则化,Mosaic数据增强,自对抗训练,消除网格敏感性,为单个groundtruth使用多个anchors,余弦退火调度器,最优超参数,随机训练形状
BoS:
backbone:Mish激活、跨级部分连接(CSP)、多输入加权剩余连接(MiWRC)。
detector:Mish activation,SPP-block, SAM-block, PAN path-aggregation block,DIoU-NMS.
4 Experiments
-
4.1 实验建立
在ImageNet图像分类实验中,默认的超参数如下:
-
训练步骤为8,000,000;
-
批量尺寸为128,
-
小批量尺寸为32;
-
采用多项式衰减学习速率调度策略,
-
初始学习速率为0.1,
-
热身步骤为1000;
-
momentum和weight衰减分别设置为0.9和0.005。
在BoF实验中,还增加了50%的训练步骤,验证了混合、切分、镶嵌、模糊数据增强和标签平滑正则化方法。
在BoS实验中,使用与默认设置相同的超参数。比较了LReLU、Swish和Mish激活函数的作用。所有实验均使用1080Ti或2080Ti GPU进行训练。
MS COCO目标检测实验中,默认的超参数为:
-
训练步骤为500500;
-
采用初始学习速率0.01的步长衰减学习速率策略,在400000步和450000步分别乘以因子0.1;
-
momentum衰减为0.9,weight衰减为0.0005。
-
所有的架构都使用一个GPU来执行批处理大小为64的多尺度训练,而小批处理大小为8或4取决于架构和GPU内存限制。
除了使用遗传算法进行超参数搜索实验外,其他实验均使用默认设置。
-
遗传算法利用YOLOv3-SPP进行带GIoU损失的训练,搜索300个epoch的min-val5k集。
-
遗传算法实验采用搜索学习率0.00261、momentum0.949、IoU阈值分配ground truth 0.213、损失归一化器0.07。
对于所有实验,只使用一个GPU训练,因此不会使用syncBN等优化多个gpu的技术。
-
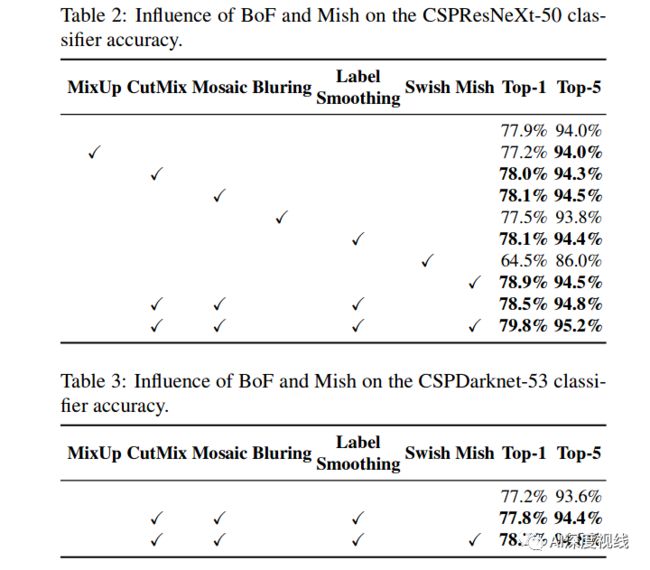
4.2 不同特征对分类器训练的影响

具体来说,如Fugure7所示,类标签平滑、不同数据增强技术、双侧模糊、MixUp、CutMix和Mosaic的影响,以及不同激活的影响,如Leaky-ReLU(默认)、Swish和Mish。结果如下表所示:
-
4.3不同特征对检测器训练的影响
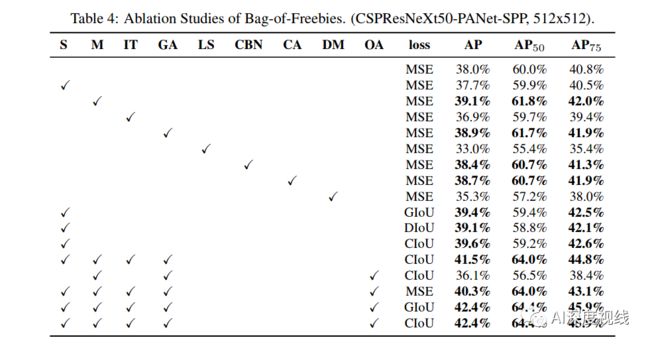
进一步研究不同的Bag-of-Freebies (BoF-detector)对detector训练精度的影响,如表4所示。通过研究在不影响FPS的情况下提高检测精度的不同特征。
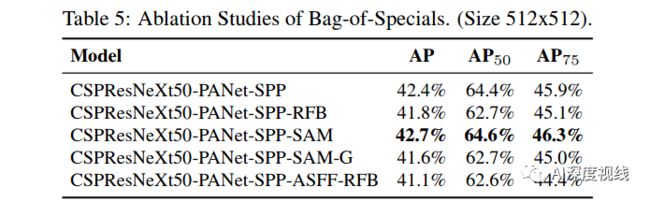
进一步研究不同的bag-specials(boss-detector)对检测器训练精度的影响,包括PAN、RFB、SAM、Gaussian YOLO(G)、ASFF,如表5所示。
-
4.4 不同的backbone和预先训练的重量对检波器训练的影响
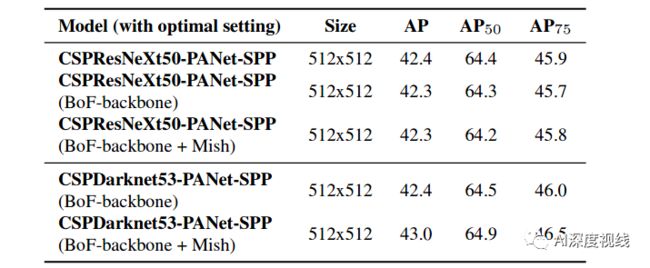
-
4.5 不同的mini-batch size对检测器训练的影响

5 Results
-
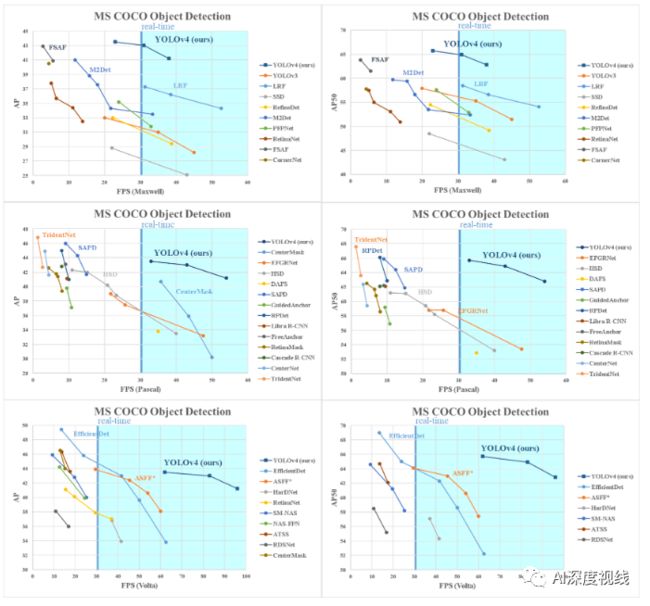
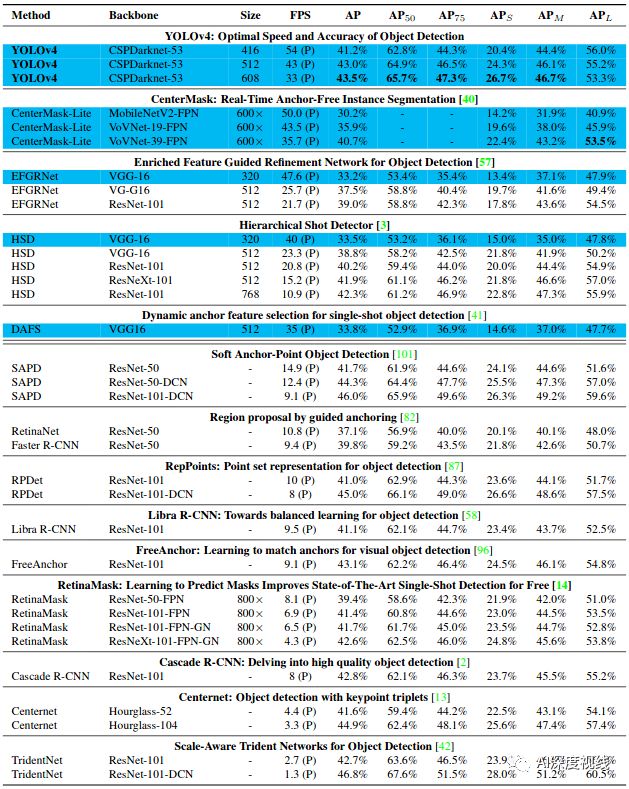
与目前较前沿检测模型的比较:
由于不同的方法使用不同架构的gpu进行推理时间验证,我们将yolov4运行在通常采用的Maxwell架构、Pascal架构和Volta架构的gpu上,并将其与其他最先进的方法进行比较。
-
表8列出了使用Maxwell GPU的帧率比较结果,可以是GTX Titan X (Maxwell)或者Tesla M40 GPU。

-
表9列出了使用Pascal GPU的帧率比较结果,可以是Titan X (Pascal)、Titan Xp、GTX 1080 Ti或Tesla P100 GPU。
-
表10列出了使用VoltaGPU的帧率比较结果,可以是Titan Volta,也可以是Tesla V100 GPU。