随机请求头设置练习
设置爬虫访问 http://httpbin.org/user-agent
- 创建scrapy项目 scrapy startproject useragent_demo
- 创建爬虫 scrapy genspier httpbin "httpbin.org/user-agent"
- 设置机器人协议False
- DEFAULT_REQUEST_HEADERS中设置为访问网页上的请求头,print(response.text)查看
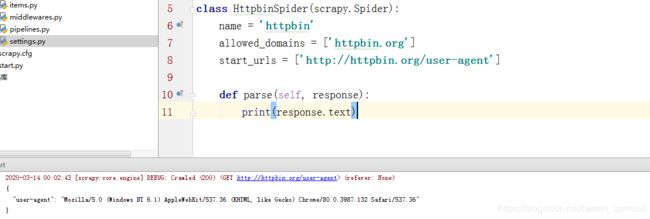
 一致
一致 - 设置中间键,定义process_request方法,如图:

- 在useragentspring网站中随便复制一些请求头定义一个数组。。。如图:

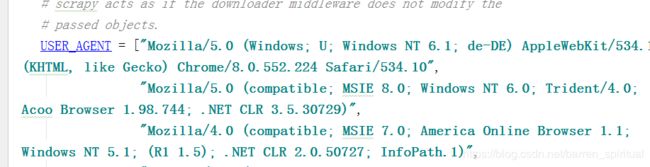
- 打开下载器中间键功能

- 设置等待时长1S

- 运行爬虫打印请求头数据:
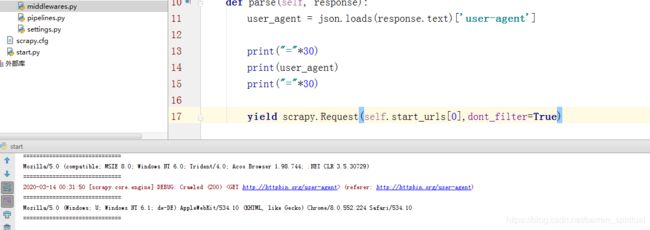
-
完整代码: # -*- coding: utf-8 -*- import scrapy import json class HttpbinSpider(scrapy.Spider): name = 'httpbin' allowed_domains = ['httpbin.org'] start_urls = ['http://httpbin.org/user-agent'] def parse(self, response): user_agent = json.loads(response.text)['user-agent'] print("="*30) print(user_agent) print("="*30) yield scrapy.Request(self.start_urls[0],dont_filter=True)