Keras 是一个用 Python 编写的高级神经网络 API,它以Tensorflow为后端但是比Tensorflow更易于操作,但是在方便编写的同时也少了很多灵活性。如果我们需要定义一个Keras中没有的操作,对于简单、无状态的自定义操作,你也许可以通过layers.core.Lambda层来实现。但是对于那些包含了可训练权重的自定义层,你应该自己实现这种层。
环境
- Python 3.6
- Keras 2.2.2
- Tensorflow-gpu 1.8.0
官方示例
这是一个Keras2.0中,Keras层的骨架(如果你用的是旧的版本,请你更新)。你只需要实现三个方法即可:
build(input_shape): 这是你定义权重的地方。这个方法必须设self.built = True,可以通过调用super([Layer], self).build()完成。
call(x): 这里是编写层的功能逻辑的地方。你只需要关注传入call的第一个参数:输入张量,除非你希望你的层支持masking。
compute_output_shape(input_shape):如果你的层更改了输入张量的形状,你应该在这里定义形状变化的逻辑,这让Keras能够自动推断各层的形状。
from keras import backend as K
from keras.engine.topology import Layer
import numpy as np
class MyLayer(Layer):
def __init__(self, output_dim, **kwargs):
self.output_dim = output_dim
super(MyLayer, self).__init__(**kwargs)
def build(self, input_shape):
# Create a trainable weight variable for this layer.
self.kernel = self.add_weight(name='kernel',
shape=(input_shape[1], self.output_dim),
initializer='uniform',
trainable=True)
super(MyLayer, self).build(input_shape) # Be sure to call this somewhere!
def call(self, x):
return K.dot(x, self.kernel)
def compute_output_shape(self, input_shape):
return (input_shape[0], self.output_dim)
分析Dense层
下面是Keras包中实现的Desne层,我们可以看出这一层是按照官方的标准实现的。
1.初始化
每一个层都要继承基类Layer,这个类在base_layer.py中定义。
在__init__的部分,类对传入的参数进行了检查并对各种赋值参数进行了处理。像初始化、正则化等操作都是使用Keras自带的包进行了包装处理。
2.build()
build()函数首先对输入张量的大小进行了检查,对于Dense层,输入张量的大小为2即(batch_shape, sample_shape)。
然后使用self.add_weight()函数添加该层包含的可学习的参数,对于Dense层其基本操作就是一元线性回归方程y=wx+b,因此定义的两个参数kernel和bias,参数trainable=True是默认的。需要注意的是参数的大小需要我们根据输入与输出的尺寸进行定义,比如输入为n,输出为m,我们需要的参数大小即为(n, m),偏置大小为m,这是一个矩阵乘法。
底层的所有操作都不需要我们处理,self.add_weight()函数会将各种类型的参数进行分配,Tensorflow帮我们完成自动求导和反向传播。
最后调用self.built = True完成这一层的设置,这一句是一定要有的。也可以使用super(MyLayer, self).build(input_shape)调用父类的函数进行替代。
3 .call()
这个函数式一个网络层最为核心的部分,用来进行这一层对应的运算,其接收上一层传入的张量返回这一层计算完成的张量。
output = K.dot(inputs, self.kernel)这里完成矩阵点乘的操作
output = K.bias_add(output, self.bias, data_format='channels_last')这里完成矩阵加法的操作
output = self.activation(output)这里调用激活函数处理张量
4. compute_output_shape()
compute_output_shape()函数用来输出这一层输出尺寸的大小,尺寸是根据input_shape以及我们定义的output_shape计算的。这个函数在组建Model时会被调用,用来进行前后层张量尺寸的检查。
4. get_config()
get_config()这个函数用来返回这一层的配置以及结构。
class Dense(Layer):
"""Just your regular densely-connected NN layer.
`Dense` implements the operation:
`output = activation(dot(input, kernel) + bias)`
where `activation` is the element-wise activation function
passed as the `activation` argument, `kernel` is a weights matrix
created by the layer, and `bias` is a bias vector created by the layer
(only applicable if `use_bias` is `True`).
Note: if the input to the layer has a rank greater than 2, then
it is flattened prior to the initial dot product with `kernel`.
# Example
```python
# as first layer in a sequential model:
model = Sequential()
model.add(Dense(32, input_shape=(16,)))
# now the model will take as input arrays of shape (*, 16)
# and output arrays of shape (*, 32)
# after the first layer, you don't need to specify
# the size of the input anymore:
model.add(Dense(32))
```
# Arguments
units: Positive integer, dimensionality of the output space.
activation: Activation function to use
(see [activations](../activations.md)).
If you don't specify anything, no activation is applied
(ie. "linear" activation: `a(x) = x`).
use_bias: Boolean, whether the layer uses a bias vector.
kernel_initializer: Initializer for the `kernel` weights matrix
(see [initializers](../initializers.md)).
bias_initializer: Initializer for the bias vector
(see [initializers](../initializers.md)).
kernel_regularizer: Regularizer function applied to
the `kernel` weights matrix
(see [regularizer](../regularizers.md)).
bias_regularizer: Regularizer function applied to the bias vector
(see [regularizer](../regularizers.md)).
activity_regularizer: Regularizer function applied to
the output of the layer (its "activation").
(see [regularizer](../regularizers.md)).
kernel_constraint: Constraint function applied to
the `kernel` weights matrix
(see [constraints](../constraints.md)).
bias_constraint: Constraint function applied to the bias vector
(see [constraints](../constraints.md)).
# Input shape
nD tensor with shape: `(batch_size, ..., input_dim)`.
The most common situation would be
a 2D input with shape `(batch_size, input_dim)`.
# Output shape
nD tensor with shape: `(batch_size, ..., units)`.
For instance, for a 2D input with shape `(batch_size, input_dim)`,
the output would have shape `(batch_size, units)`.
"""
@interfaces.legacy_dense_support
def __init__(self, units,
activation=None,
use_bias=True,
kernel_initializer='glorot_uniform',
bias_initializer='zeros',
kernel_regularizer=None,
bias_regularizer=None,
activity_regularizer=None,
kernel_constraint=None,
bias_constraint=None,
**kwargs):
if 'input_shape' not in kwargs and 'input_dim' in kwargs:
kwargs['input_shape'] = (kwargs.pop('input_dim'),)
super(Dense, self).__init__(**kwargs)
self.units = units
self.activation = activations.get(activation)
self.use_bias = use_bias
self.kernel_initializer = initializers.get(kernel_initializer)
self.bias_initializer = initializers.get(bias_initializer)
self.kernel_regularizer = regularizers.get(kernel_regularizer)
self.bias_regularizer = regularizers.get(bias_regularizer)
self.activity_regularizer = regularizers.get(activity_regularizer)
self.kernel_constraint = constraints.get(kernel_constraint)
self.bias_constraint = constraints.get(bias_constraint)
self.input_spec = InputSpec(min_ndim=2)
self.supports_masking = True
def build(self, input_shape):
assert len(input_shape) >= 2
input_dim = input_shape[-1]
self.kernel = self.add_weight(shape=(input_dim, self.units),
initializer=self.kernel_initializer,
name='kernel',
regularizer=self.kernel_regularizer,
constraint=self.kernel_constraint)
if self.use_bias:
self.bias = self.add_weight(shape=(self.units,),
initializer=self.bias_initializer,
name='bias',
regularizer=self.bias_regularizer,
constraint=self.bias_constraint)
else:
self.bias = None
self.input_spec = InputSpec(min_ndim=2, axes={-1: input_dim})
self.built = True
def call(self, inputs):
output = K.dot(inputs, self.kernel)
if self.use_bias:
output = K.bias_add(output, self.bias, data_format='channels_last')
if self.activation is not None:
output = self.activation(output)
return output
def compute_output_shape(self, input_shape):
assert input_shape and len(input_shape) >= 2
assert input_shape[-1]
output_shape = list(input_shape)
output_shape[-1] = self.units
return tuple(output_shape)
def get_config(self):
config = {
'units': self.units,
'activation': activations.serialize(self.activation),
'use_bias': self.use_bias,
'kernel_initializer': initializers.serialize(self.kernel_initializer),
'bias_initializer': initializers.serialize(self.bias_initializer),
'kernel_regularizer': regularizers.serialize(self.kernel_regularizer),
'bias_regularizer': regularizers.serialize(self.bias_regularizer),
'activity_regularizer': regularizers.serialize(self.activity_regularizer),
'kernel_constraint': constraints.serialize(self.kernel_constraint),
'bias_constraint': constraints.serialize(self.bias_constraint)
}
base_config = super(Dense, self).get_config()
return dict(list(base_config.items()) + list(config.items()))
实现自定义的FM层
因子分解机(Factorization Machines,FM)是常用在CTR中的一种模型,可以与深度模型进行拼接。FM的矩阵形式公式如下:
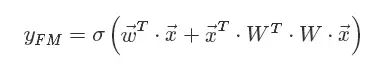
FM通过内积进行无重复项与特征平方项的特征组合过程公式如下:

定义一个FM层,其包含三个可学习参数,分别是一次项、二次交叉项和偏置项。这三个参数在build函数中定义。
根据FM的计算公式,在call函数中定义张量间的数学运算。这些运算可以在keras backend中进行调用,使用方法与Tensorflow中的类似。
import keras.backend as K
from keras import activations
from keras.engine.topology import Layer, InputSpec
class FMLayer(Layer):
def __init__(self, output_dim,
factor_order,
activation=None,
**kwargs):
if 'input_shape' not in kwargs and 'input_dim' in kwargs:
kwargs['input_shape'] = (kwargs.pop('input_dim'),)
super(FMLayer, self).__init__(**kwargs)
self.output_dim = output_dim
self.factor_order = factor_order
self.activation = activations.get(activation)
self.input_spec = InputSpec(ndim=2)
def build(self, input_shape):
assert len(input_shape) == 2
input_dim = input_shape[1]
self.input_spec = InputSpec(dtype=K.floatx(), shape=(None, input_dim))
self.w = self.add_weight(name='one',
shape=(input_dim, self.output_dim),
initializer='glorot_uniform',
trainable=True)
self.v = self.add_weight(name='two',
shape=(input_dim, self.factor_order),
initializer='glorot_uniform',
trainable=True)
self.b = self.add_weight(name='bias',
shape=(self.output_dim,),
initializer='zeros',
trainable=True)
super(FMLayer, self).build(input_shape)
def call(self, inputs, **kwargs):
X_square = K.square(inputs)
xv = K.square(K.dot(inputs, self.v))
xw = K.dot(inputs, self.w)
p = 0.5 * K.sum(xv - K.dot(X_square, K.square(self.v)), 1)
rp = K.repeat_elements(K.reshape(p, (-1, 1)), self.output_dim, axis=-1)
f = xw + rp + self.b
output = K.reshape(f, (-1, self.output_dim))
if self.activation is not None:
output = self.activation(output)
return output
def compute_output_shape(self, input_shape):
assert input_shape and len(input_shape) == 2
return input_shape[0], self.output_dim
使用一个keras官方的二分类模型作为对比模型,将其中的一个Dense层替换为FM层:
import numpy as np
from keras.datasets import imdb
from keras.preprocessing import sequence
from keras.layers import Dense, Input, Dropout, Embedding, Conv1D, GlobalMaxPooling1D
from keras.models import Model
def test_model(x_train, x_test, y_train, y_test, train=False):
inp = Input(shape=(100,))
x = Embedding(20000, 50)(inp)
x = Dropout(0.2)(x)
x = Conv1D(250, 3, padding='valid', activation='relu', strides=1)(x)
x = GlobalMaxPooling1D()(x)
x = Dense(250, activation='relu')(x)
x = Dropout(0.2)(x)
x = Dense(1, activation='sigmoid')(x)
model = Model(inputs=inp, outputs=x)
if train:
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
model.fit(x_train, y_train,
batch_size=32,
epochs=2,
validation_data=(x_test, y_test))
model.save_weights('model.h5')
return model
def fm_model(x_train, x_test, y_train, y_test, train=False):
inp = Input(shape=(100,))
x = Embedding(20000, 50)(inp)
x = Dropout(0.2)(x)
x = Conv1D(250, 3, padding='valid', activation='relu', strides=1)(x)
x = GlobalMaxPooling1D()(x)
x = FMLayer(200, 100)(x)
x = Dropout(0.2)(x)
x = Dense(1, activation='sigmoid')(x)
model = Model(inputs=inp, outputs=x)
if train:
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
model.fit(x_train, y_train,
batch_size=32,
epochs=2,
validation_data=(x_test, y_test))
model.save_weights('model.h5')
return model
if __name__ == '__main__':
x_train, x_test, y_train, y_test = get_data()
test_model(x_train, x_test, y_train, y_test, train=True)
model = fm_model(x_train, x_test, y_train, y_test, train=True)
print(model.summary())
基准模型训练结果:
Epoch 1/2
25000/25000 [==============================] - 26s 1ms/step - loss: 0.4457 - acc: 0.7778 - val_loss: 0.3932 - val_acc: 0.8219
Epoch 2/2
25000/25000 [==============================] - 25s 1ms/step - loss: 0.2512 - acc: 0.8969 - val_loss: 0.3503 - val_acc: 0.8462
将基准模型中的全连接层替换为FM层:
Train on 25000 samples, validate on 25000 samples
Epoch 1/2
25000/25000 [==============================] - 36s 1ms/step - loss: 0.4646 - acc: 0.7628 - val_loss: 0.3324 - val_acc: 0.8516
Epoch 2/2
25000/25000 [==============================] - 26s 1ms/step - loss: 0.2608 - acc: 0.8954 - val_loss: 0.3508 - val_acc: 0.8538
使用FM层的模型结构:
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_4 (InputLayer) (None, 100) 0
_________________________________________________________________
embedding_4 (Embedding) (None, 100, 50) 1000000
_________________________________________________________________
dropout_6 (Dropout) (None, 100, 50) 0
_________________________________________________________________
conv1d_3 (Conv1D) (None, 98, 250) 37750
_________________________________________________________________
global_max_pooling1d_3 (Glob (None, 250) 0
_________________________________________________________________
fm_layer_3 (FMLayer) (None, 200) 75200
_________________________________________________________________
dropout_7 (Dropout) (None, 200) 0
_________________________________________________________________
dense_4 (Dense) (None, 1) 201
=================================================================
Total params: 1,113,151
Trainable params: 1,113,151
Non-trainable params: 0
_________________________________________________________________
None
可以看出我们定义的FM层可以在模型中良好的运行,同时FM层在没有增加模型复杂度的情况下,提升了模型的分类准确性。