攻防视角下的信息收集
信息收集是指通过各种方式获取所需的信息。信息收集是信息得以利用的第一步,也是关键的一步。—百度百科
信息收集是指黑客为了更加有效地实施渗透攻击而在攻击前或攻击过程中对目标的所有探测活动。
背景: 不论曾经作为白帽子、安全服务工程师还是现在作为甲方安全工程师,都明白信息收集这项工作的重要性。目前网络上关于信息收集的文章数不胜数,那么为什么还要老生常谈?主要是目前网络上的文章更多是站在白帽子或者攻击者的视角下进行展开讨论,但甲方做信息收集的话题没有被提及,本文抛砖引玉,希望更多大佬提出意见。其实是对自己曾经做过的信息收集内容进行一个总结。
本文通过两个角度来讨论信息收集:攻击方、防守方,它们二者之间在信息收集方向的关系如下图:
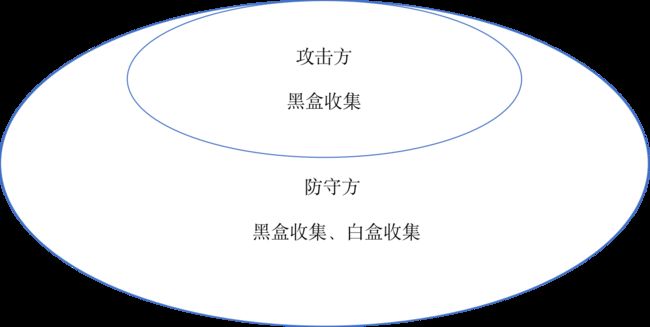
不论是攻击方还是防守方做信息收集工作主要是四种方法:
- 社会工程:
- Google Hacking(不一定是Google);
- 社交软件(微信、QQ、朋友圈等等);
site:example.com
site:example.com 登录
site:example.com login
- 花式工具:各种扫描器与漏洞利用工具、爬虫;
- 奇葩技巧:这个主意是靠经验的积累与多看看大佬的文章;
- 手工:坚持+耐心
攻击方视角下的信息收集
网络上关于攻击方做信息收集的工具、方法都有了很不错的文章,大家搜索"信息收集"关键字就可以获取。攻击方做信息收集讨论两个问题:为什么做信息收集?收集什么与如何收集?
为什么做信息收集?
要明白的是知己知彼百战百胜,攻击方做信息收集就是一个知彼的过程。做好了这项工作更有利于我们去开展后续的工作。
举个例子:我们要在SRC平台进行漏洞挖掘,首先我们要做的就是明确SRC平台收录的漏洞范围,其次就是收集收录范围内的可攻击目标("万物"皆可被攻击),最后才是对这些目标进行分析漏洞挖掘或渗透的工作。
其实攻击方在各个阶段做信息收集工作的意义都是为了获取攻击面。在做信息收集之前,你掌握的信息是一个攻击点,通过信息收集你掌握了多个攻击点,这些攻击点有可利用的也有不可利用的,然后通过将这些攻击点连接起来汇成一个攻击面。当我们拥有一个攻击面时就能利用自己掌握的攻击方法找到攻击面中的薄弱点进行攻击,如果我们拥有的攻击面越宽广,那么我们攻击成功的概率也就越高。
对于信息收集结果来说分为:直接可用、间接可用、未来可用三个状态。
- 直接可用:结果可以直接进行利用,比如:数据库配置文件泄露等;
- 间接可用:结果不能直接进行利用,但是可以间接的产生产生效果,比如:后台登录地址;
- 未来可用:结果当前时间不能进行可用,但是未来某个时间点可用,比如:新系统上线公告(别疑惑,如果你知道某个系统下周一上线,万一他们没有做安全测试就上线了呢!你的机会就来了);
收集什么与如何收集?
企业信息
- 企业组织架构:获取攻击入口。
- 企业组成:集团、下属单位等信息;
- 部门划分
- 人员信息:姓名、手机号、工号、邮箱(邮箱命名格式:[email protected]、[email protected]、[email protected])、身份证号、工作职能、所属部门、内部OA默认密码等信息;
- 企业的供应商或合作商:方便钓鱼或社工时使用。
- 软硬件供应商等信息;
- 供应商对接人员信息;
- 企业备案信息:ICP信息查看、天眼查获取等。
IT信息
收集IT信息主要是为了扩大攻击面。
域名信息
- 主域名
- 在sitemap、about或SRC的公告上查找企业主域名或业务信息,比如:https://www.pingan.com/homepage/sitemap.shtml等;
- 通过HTTPS的证书查看主域名信息;
- 通过whois反向查询主域名信息,包括:注册人反查、联系电话反查、联系邮箱反查等;
- 通过图片、JS、CSS等文件或URL跳转地址获取主域名信息;
- 通过反编译APP查看代码获取主域名与子域名信息,推荐工具:ApkIDE;
- 子域名
- 域名信息查询:nslookup、dig等;
- DNS区域传输漏洞:
dig @dns-server domain -T axfr; - 域名暴力破解:subDomainBrute、Layer等等;
- 搜索引擎:
site: example.com,如果是搜索国内的域名多用Bing与Baidu有的时候比Google效果更好; - https://www.shodan.io/、https://fofa.so/等类似站点;
- 其他:crossdomain.xml、爬虫(慎用爬虫);
网络信息
- IP及IP网段:服务器真实IP、是否有C段IP或B段IP;如果没有CDN或F5等类似设备的情况下,可以直接ping获取服务器真实IP,如果有CDN或F5等类似设备的情况下,可以通过以下方法获取,但是结果不一定准确:
- 超级ping、多地ping:https://ping.chinaz.com/, 判断是否有CDN也可以通过此种方式。
- 通过二级域名:只要不是所有的二级域名都处于CDN的接入中,可以通过二级域名来获取真实IP;
- nslookup:找一些国外偏僻的DNS解析服务器进行DNS查询,大部分CDN只针对国内市场。
- traceroute
- 透过F5获取服务器真实IP](http://www.lewisec.com/2017/06/13/Get_the_real_IP_through_F5/);
- 收集常用的CDN IP、云SLB IP、云弹性IP等IP集合;
- XSS漏洞、DDoS、邮件订阅等;
- 网络架构
- 应用系统访问架构(Client --> [CDN] --> [SLB] --> Server)等信息;
- 网络设备:路由器、交换机、防火墙等网络与网络安全设备信息;
服务器信息
- 服务器操作系统
- 操作系统类型与版本信息:操作系统识别工具;
- 操作系统补丁信息:服务器安全扫描工具;
- 服务器开放端口及服务
- 端口信息:端口扫描工具
- 服务版本信息:服务识别工具;
- 服务是否存在未授权访问:未授权访问扫描;
应用信息
- Web应用
- CMS信息:CMS识别工具;
- 中间件、Web容器、Web服务器指纹:默认文件或路径、报错信息、HTTP Response信息、Chrome Wappalyzer插件等其他指纹识别工具;
- WAF判断:是否有WAF,WAF指纹识别(wafw00f、sqlmap的waf脚本、nmap的http-waf-detect和http-waf-fingerprint脚本);
- 移动应用:APP、H5、公众号、小程序:关键字搜索
- 其他应用信息
敏感信息
收集敏感信息更多是找到比较精准的攻击入口或直接利用信息收集结果。
- 代码信息
- GitHub、码云等代码托管平台;
- 代码备份文件(以前存在打包备份的代码文件存放在网站目录下);
- 代码文件:网站对代码脚本未执行解析导致可以直接下载;
- 敏感文件
- 测试文件:robots.txt、test.php、info.php等;
- 配置文件:数据库配置文件等;
- PDF或图片:很多PDF或图片中包含敏感信息,比如:PDF文件中包含保单完整信息;图片中包含身份证信息等;
- 前端代码:HTML源代码、JS代码中泄露敏感信息;
- 敏感目录
- 仓库托管默认文件夹:.git、.svn、.bzr等;
- 管理后台目录:目录扫描工具;
- 接口目录与地址;
- 文档信息
- 合同、产品或项目文档、人力资源文档、战略规划文档等;
- 账号密码信息
- 内部运维开发系统账号密码,比如:Zabbix、Jenkins、GitLab等平台的账号密码;
- 使用的第三方系统账号密码,比如:堡垒机、防火墙等其他网络设备与网络安全设备账号密码;
- 默认密码信息:比如:OA、邮箱、通讯工具等;
- 云平台Token:阿里云、亚马逊云、七牛云等;
- 其他信息
- 敏感数据:某些企业内部没有大文件共享平台时,会使用网盘、U盘等类似工具共享敏感数据;
- 历史漏洞信息:乌云镜像、历史漏洞中暴露出来的信息;
防守方视角下的信息收集
防守方做信息收集也讨论两个问题:为什么做信息收集?收集什么与怎么收集?
为什么要做信息收集
要明白的是知己知彼百战百胜,防守方做信息收集就是一个知己的过程。做这项工作的目的主要是为了安全摸底,了解企业安全现状与探知未知风险。
例1:了解服务器端口开放信息、补丁信息等,是为了了解服务器所面临的安全风险,方便我们后续推进安全措施。
例2:收集情报信息,是为了了解企业正在面对或即将面对的风险,根据情报作出安全响应动作。
防守方在做信息收集的过程就是在不断摸清安全风险,然后通过安全方案来解决风险。当防守方得到的信息收集结果越丰富,对自身安全状况了解也就越清晰,通过对抗的思路防守者也就明白应该如何最优的去解决这些安全风险。
收集什么与如何收集?
如开篇中的图片,防守方信息收集的内容是包含攻击方的信息收集内容的。所以攻击方收集的内容防守方也必须收集,而且信息准确度要求更高。
对于防守方做信息收集主要有两个途径:
- 黑盒收集:主要就是攻击方做信息收集的方法;
- 白盒收集:利用内部平台和已知信息做收集;
对于防守方做信息收集内容主要包括两个大的方向:管理类与技术类。
在本文中主要从技术角度出发,分析容易出现安全风险的项:
IT资产
域名资产
- 关注内容:
- 域名基础信息:注册邮箱、注册联系人、注册时间、过期时间(防止出现域名过期被抢注);
- 域名是否使用HTTPS(监管要求以及防止网络嗅探攻击);
- 收集方式:
- 黑盒收集;
- 从域名注册商直接查看;
- 从Nginx或其他Web服务器、网关配置文件中查看;
服务器资产
- 关注内容
- 操作系统:类型及详细的版本信息、操作系统补丁信息等;
- 服务信息:系统运行服务、服务版本信息与配置信息、服务绑定端口信息等;
- 运行状态:CPU、网络IO、磁盘IO等信息;
- 细粒度信息:软件库版本信息等;
- 收集方式:
- 黑盒收集;
- 手工Excel整理;
- 云管理平台查看或自动获取(可以使用API进行自动获取);
- 利用入侵检测系统等获取服务器信息;
- 利用运维监控系统收集服务器信息;
网络资产
- 关注内容:
- 网络架构:IP与网段信息、网络划分信息(生产、测试、办公、DMZ)
- 网络访问控制信息;
- 收集方式:
- 内部网络拓扑图;
- 查看防火墙规则;
设备资产
- 关注内容:网络设备、安全设备、IDC机房等;
- 收集方式:采购合同、实施方案、网络拓扑图等;
应用资产
- 关注内容:应用系统、APP、小程序、H5等;
- 收集方式:
- 黑盒收集;
- 查看版本管理系统、发版邮件、持续集成系统等获取;
代码资产
- 关注内容:代码引入的第三方包、代码依赖的组件等
- 收集方式:代码白盒审计与扫描等;
账号资产
- 关注内容:特权帐号owner;
- 收集方式:人工调研、登录系统查看等;
数据信息
- 关注内容:数据采集方式及内容、数据传输方式、数据存储与使用、数据销毁等;
- 收集方式:人工调研数据流、查看数据安全产品等;
情报信息
- 漏洞情报
- 关注内容:各渠道提交的相关漏洞、爆发的新漏洞等;
- 收集方式:SRC、漏洞平台、应急响应服务、朋友圈、exploitdb、CNVD等;
- 威胁情报
- 关注内容:羊毛党、恶意攻击(恶意APP、恶意链接)等;
- 收集方式:社交群聊(聊天机器人)、查看相关论坛贴吧、爬虫等;
- 事件情报
- 关注内容:针对性的攻击事件,比如:蠕虫、病毒、DDoS、勒索等;
- 收集方式:事件报告等;
汇总来说防守方做信息收集应该关注企业的所有信息,信息收集也要做所有安全关注而未知的项(security should focus on all aspects)。
但是目前以自己的能力能想到的就这么多,欢迎大家留言补充。
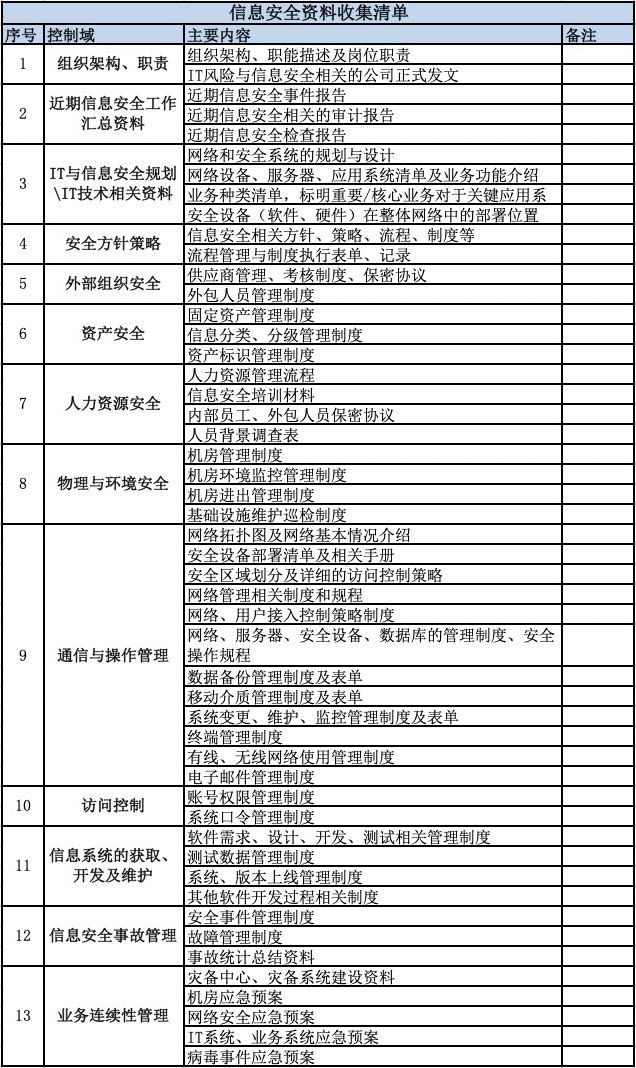
附带一张管理视角的信息收集:
信息收集,一直在谈,却一直未做好的话题。 未完待续(欢迎加我沟通:Lzero2012)~~~