Dual Attention Network for Scene Segmentation
论文链接:https://arxiv.org/pdf/1809.02983.pdf CVPR2019的一篇文章
代码链接:https://github.com/junfu1115/DANet/
主要思想:按照文中的说法就是we append two types of attention modules on top of dilated FCN, which model the semantic interdependencies in spatial and channel dimensions respectively,感觉就是把non local改成在channel和position角度来用到分割中。
看下面的结构图会非常清晰,resnet之后的feature经过两个分支,分别做position attention和channel attention,最后在进行sum fusion,其实就是相加。不过相加之前其实两个attention输出的feature C*H*W分别会乘以一个系数,这个系数初始化为0,最后通过网络学习所得。
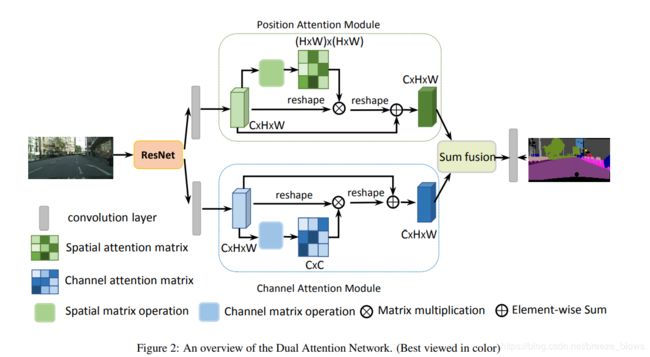
两个attention的详细结构图

对于position attention,首先求得位置相关矩阵S
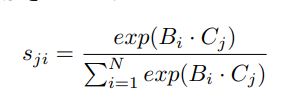
接着得到输出
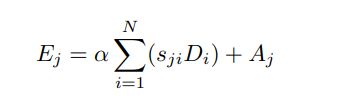
这里的alpha是一个可以学习的参数,初始值为0
对于channel attention,也是先得到channel相关矩阵
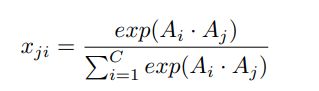
得到输出

这里的beta跟上面的alpha一样都是初始化为0,最后进行学习。
最后将两个attention的输出直接wise-sum就是相加,然后经过conv得到整个模块的输出
代码:https://github.com/junfu1115/DANet/blob/c7a2f608f5f11e2f2d3c0760dd98dfe12e32a408/encoding/nn/attention.py
两个attention的代码
###########################################################################
# Created by: CASIA IVA
# Email: [email protected]
# Copyright (c) 2018
###########################################################################
import numpy as np
import torch
import math
from torch.nn import Module, Sequential, Conv2d, ReLU,AdaptiveMaxPool2d, AdaptiveAvgPool2d, \
NLLLoss, BCELoss, CrossEntropyLoss, AvgPool2d, MaxPool2d, Parameter, Linear, Sigmoid, Softmax, Dropout, Embedding
from torch.nn import functional as F
from torch.autograd import Variable
torch_ver = torch.__version__[:3]
__all__ = ['PAM_Module', 'CAM_Module']
class PAM_Module(Module):
""" Position attention module"""
#Ref from SAGAN
def __init__(self, in_dim):
super(PAM_Module, self).__init__()
self.chanel_in = in_dim
self.query_conv = Conv2d(in_channels=in_dim, out_channels=in_dim//8, kernel_size=1)
self.key_conv = Conv2d(in_channels=in_dim, out_channels=in_dim//8, kernel_size=1)
self.value_conv = Conv2d(in_channels=in_dim, out_channels=in_dim, kernel_size=1)
self.gamma = Parameter(torch.zeros(1))
self.softmax = Softmax(dim=-1)
def forward(self, x):
"""
inputs :
x : input feature maps( B X C X H X W)
returns :
out : attention value + input feature
attention: B X (HxW) X (HxW)
"""
m_batchsize, C, height, width = x.size()
proj_query = self.query_conv(x).view(m_batchsize, -1, width*height).permute(0, 2, 1) #[bs, w*h, c]
proj_key = self.key_conv(x).view(m_batchsize, -1, width*height) #[bs, c, w*h]
energy = torch.bmm(proj_query, proj_key) #[bs, w*h, w*h]
attention = self.softmax(energy)
proj_value = self.value_conv(x).view(m_batchsize, -1, width*height) #[bs, c, w*h]
out = torch.bmm(proj_value, attention.permute(0, 2, 1)) #[bs, c, w*h]
out = out.view(m_batchsize, C, height, width)
out = self.gamma*out + x
return out
class CAM_Module(Module):
""" Channel attention module"""
def __init__(self, in_dim):
super(CAM_Module, self).__init__()
self.chanel_in = in_dim
self.gamma = Parameter(torch.zeros(1))
self.softmax = Softmax(dim=-1)
def forward(self,x):
"""
inputs :
x : input feature maps( B X C X H X W)
returns :
out : attention value + input feature
attention: B X C X C
"""
m_batchsize, C, height, width = x.size()
proj_query = x.view(m_batchsize, C, -1)
proj_key = x.view(m_batchsize, C, -1).permute(0, 2, 1)
energy = torch.bmm(proj_query, proj_key)
energy_new = torch.max(energy, -1, keepdim=True)[0].expand_as(energy)-energy
attention = self.softmax(energy_new)
proj_value = x.view(m_batchsize, C, -1)
out = torch.bmm(attention, proj_value)
out = out.view(m_batchsize, C, height, width)
out = self.gamma*out + x
return out
整个DAnet
https://github.com/junfu1115/DANet/blob/c7a2f608f5f11e2f2d3c0760dd98dfe12e32a408/encoding/models/danet.py#L58
class DANetHead(nn.Module):
def __init__(self, in_channels, out_channels, norm_layer):
super(DANetHead, self).__init__()
inter_channels = in_channels // 4
self.conv5a = nn.Sequential(nn.Conv2d(in_channels, inter_channels, 3, padding=1, bias=False),
norm_layer(inter_channels),
nn.ReLU())
self.conv5c = nn.Sequential(nn.Conv2d(in_channels, inter_channels, 3, padding=1, bias=False),
norm_layer(inter_channels),
nn.ReLU())
self.sa = PAM_Module(inter_channels)
self.sc = CAM_Module(inter_channels)
self.conv51 = nn.Sequential(nn.Conv2d(inter_channels, inter_channels, 3, padding=1, bias=False),
norm_layer(inter_channels),
nn.ReLU())
self.conv52 = nn.Sequential(nn.Conv2d(inter_channels, inter_channels, 3, padding=1, bias=False),
norm_layer(inter_channels),
nn.ReLU())
self.conv6 = nn.Sequential(nn.Dropout2d(0.1, False), nn.Conv2d(inter_channels, out_channels, 1))
self.conv7 = nn.Sequential(nn.Dropout2d(0.1, False), nn.Conv2d(inter_channels, out_channels, 1))
self.conv8 = nn.Sequential(nn.Dropout2d(0.1, False), nn.Conv2d(inter_channels, out_channels, 1))
def forward(self, x):
feat1 = self.conv5a(x)
sa_feat = self.sa(feat1)
sa_conv = self.conv51(sa_feat)
sa_output = self.conv6(sa_conv)
feat2 = self.conv5c(x)
sc_feat = self.sc(feat2)
sc_conv = self.conv52(sc_feat)
sc_output = self.conv7(sc_conv)
feat_sum = sa_conv+sc_conv
sasc_output = self.conv8(feat_sum)
output = [sasc_output]
output.append(sa_output)
output.append(sc_output)
return tuple(output)