Flume初始篇之flume安装及简单测试
Flume安装及简单测试
一、Flume简介
flume 作为 cloudera 开发的实时日志收集系统,受到了业界的认可与广泛应用。Flume 初始的发行版本目前被统称为 Flume OG(original generation),属于 cloudera。但随着 FLume 功能的扩展,Flume OG 代码工程臃肿、核心组件设计不合理、核心配置不标准等缺点暴露出来,尤其是在 Flume OG 的最后一个发行版本 0.94.0 中,日志传输不稳定的现象尤为严重,为了解决这些问题,2011 年 10 月 22 号,cloudera 完成了 Flume-728,对 Flume 进行了里程碑式的改动:重构核心组件、核心配置以及代码架构,重构后的版本统称为 Flume NG(next generation);改动的另一原因是将 Flume 纳入 apache 旗下,cloudera Flume 改名为 Apache Flume。
1、Flume的特点
flume是一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统。支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(比如文本、HDFS、Hbase等)的能力。

flume的数据流由事件(Event)贯穿始终。事件是Flume的基本数据单位,它携带日志数据(字节数组形式)并且携带有头信息,这些Event由Agent外部的Source生成,当Source捕获事件后会进行特定的格式化,然后Source会把事件推入(单个或多个)Channel中。你可以把Channel看作是一个缓冲区,它将保存事件直到Sink处理完该事件。Sink负责持久化日志或者把事件推向另一个Source。
2、Flume的可靠性
当节点出现故障时,日志能够被传送到其他节点上而不会丢失。Flume提供了三种级别的可靠性保障,从强到弱依次分别为:end-to-end(收到数据agent首先将event写到磁盘上,当数据传送成功后,再删除;如果数据发送失败,可以重新发送。),Store on failure(这也是scribe采用的策略,当数据接收方crash时,将数据写到本地,待恢复后,继续发送),Besteffort(数据发送到接收方后,不会进行确认)。
3、Flume的可恢复性
还是靠Channel。推荐使用FileChannel,事件持久化在本地文件系统里(性能较差)。
4、Flume基本概念
Agent |
一个Agent包含 source ,channel,sink 和其他组件。 |
Source |
Source 负责接收event或通过特殊机制产生event,并将events批量的放到一个或多个Channel |
Channel |
Channel位于Source和Sink之间,用于缓存进来的event |
Sink |
Sink负责将event传输到下一个source或最终目的地,成功后将event从channel移除 |
Client |
Client 是一个将原始log包装成events并且发送他们到一个或多个agent的实体,目的是从数据源系统中解耦Flume,在flume的拓扑结构中不是必须的。 |
Events |
Event是Flume数据传输的基本单元。可以是日志记录、 avro 对象等。 |
5、Flume三大组件
Flume主要由3个重要的组件购成:
· Source:完成对日志数据的收集,分成transtion 和 event 打入到channel之中。
· Channel:主要提供一个队列的功能,对source提供中的数据进行简单的缓存。
· Sink:取出Channel中的数据,进行相应的存储文件系统,数据库,或者提交到远程服务器。
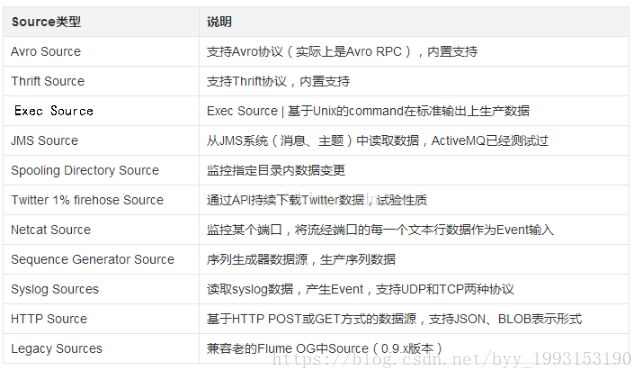
(1) Source
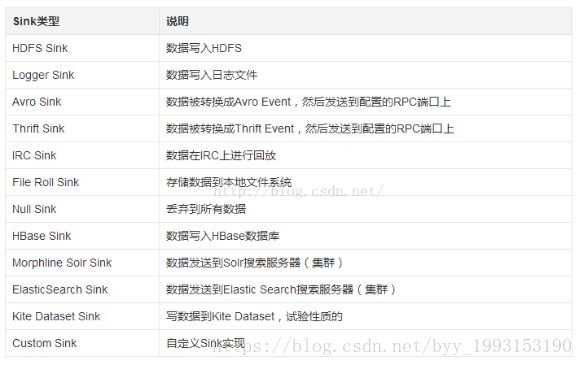
(2) Sink
(3)Channel

二、Flume的安装及测试
背景介绍:linux系统,虚拟机伪分布式集群,已安装hadoop-2.6.4,flume版本为flume-1.6.0
1、网上下载flume安装包,并将安装包上传至安装目录(例:hadoop)
2、解压文件至指定目录(例:hadoo文件夹下)
tar -zxvf apache-flume-1.6.0-bin.tar.gz注:为方便操作,解压后将文件改名为 flume-1.6.0
mv apache-flume-1.6.0-bin flume-1.6.03、配置环境变量
vi /etc/profileexport JAVA_HOME=/hadoop/jdk1.7.0_75
export HADOOP_HOME=/hadoop/hadoop-2.6.4
export FLUME_HOME=/hadoop/flume-1.6.0
export SQOOP_HOME=/hadoop/sqoop-1.4.4
export HIVE_HOME=/hadoop/hive-1.2.1
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$FLUME_HOME/bin:$HIVE_HOME/bin:$SQOOP_HOME/bin保存退出后,刷新profile
source /etc/profile4、验证
#查看版本
[root@hadoop bin]# ./flume-ng version
flume-ng flume-ng.cmd flume-ng.ps1
出现以下信息,表示安装成功
Flume 1.6.0
Source code repository: https://git-wip-us.apache.org/repos/asf/flume.git
Revision: 2561a23240a71ba20bf288c7c2cda88f443c2080
Compiled by hshreedharan on Mon May 11 11:15:44 PDT 2015
From source with checksum b29e416802ce9ece3269d34233baf43f三、测试:实时采集案例
1、创建测试文件夹,用以测试数据(例:/hadoop/testdata/flume)
2、创建配置文件(例:f2.conf)
vi f2.conf#定义agent名, source、channel、sink的名称
f2.sources = r1
f2.channels = c1
f2.sinks = k1
#具体定义source
f2.sources.r1.type = exec
f2.sources.r1.command = tail -f /hadoop/testdata/flume/server.log #指定采集目录
#具体定义channel
f2.channels.c1.type = memory
f2.channels.c1.capacity = 1000
f2.channels.c1.transactionCapacity = 100
#具体定义sink
f2.sinks.k1.type = logger
#组装source、channel、sink
f2.sources.r1.channels = c1
f2.sinks.k1.channel = c1执行agent:
flume-ng agent -n f2 -c conf -f /wishedu/testdata/flume/f2.conf -Dflume.root.logger=INFO,console
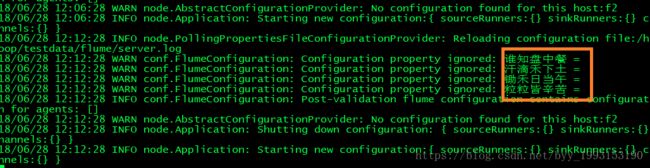
执行成功等待数据ing...
3、创建文本,采集数据(复制一个窗口)
vi server.log 添加信息

保存退出,查看数据,采集成功