博士学位论文 | 机器阅读理解与文本问答技术研究

作者丨胡明昊
学校丨国防科技大学博士生
研究方向丨机器阅读理解
引言
文本问答是自然语言处理中的一个重要领域,随着一系列大规模高质量数据集的发布和深度学习技术的快速发展,文本问答技术在近年来引起了学术界与工业界的广泛关注。如图 1 所示,近几年文本问答相关论文数量增长迅速,同时问答任务的种类也越来越多样化。

▲ 图1. 近年来基于深度学习的文本问答学术论文数量随年份变化情况统计(数据统计于ACL、EMNLP、NAACL、NIPS、AAAI等各大顶级学术会议)
机器阅读理解(Machine Reading Comprehension)是文本问答的一个子类,旨在令机器阅读并理解一段自然语言组成的文本,并回答相关问题。通过这种任务形式,我们可以对机器的自然语言理解水平进行评估,因此该任务具有重要的研究价值。
早期的阅读理解研究受限于数据集规模以及自然语言处理技术的发展,进展较为缓慢。直到 2015 年,谷歌发布首个大规模完形填空类阅读理解数据集 CNN/Daily Mail [1],引发了基于神经网络的阅读理解研究热潮。2016 年,SQuAD 数据集 [2] 被斯坦福大学发布,并迅速成为了抽取式阅读理解的基准测试集。
随后至今,机器阅读理解领域发展迅速,各类任务如开放域式、多选式、聊天式和多跳式等不断涌现。此外,阅读理解模型性能也不断刷新记录,在 SQuAD 数据集上甚至达到了超越人类的性能指标,如图 2 所示。

▲ 图2. SQuAD排行榜上代表性模型性能走势图
尽管取得了如此成就,机器阅读理解仍然面临着许多挑战,如:1)当前方法的模型结构和训练方法中存在着制约性能的问题;2)当前具备顶尖性能的集成模型在实际部署时效率低下;3)传统方法无法有效处理原文中找不到答案的情况;4)当前大部分模型是针对单段落场景设计的,无法有效扩展至开放域问答;5)当前大部分模型无法有效支持离散推理和多答案预测等情况。
针对上述存在的挑战,本文从以下五个方面开展研究:
强化助记阅读器(Reinforced Mnemonic Reader)
针对抽取式阅读理解任务,我们提出了强化助记阅读器,如图 3 所示。

▲ 图3. 强化助记阅读器总体架构示意图
该模型主要包含两点改进。第一,我们提出一个重关注机制(re-attention),该机制通过直接访问历史注意力来精炼当前注意力的计算,以避免注意力冗余与缺乏的问题。第二,我们在训练时采用动态-评估的强化学习(dynamic-critic reinforcement learning)方法,该方法总是鼓励预测一个更被接受的答案来解决传统强化学习算法中的收敛抑制问题。在 SQuAD1.1 和两个对抗数据集上的实验显示了我们的模型取得了提交时的先进性能。
注意力指导的答案蒸馏方法(Attention-Guided Answer Distillation)
针对当前阅读理解集成模型效率低下的问题,我们提出了注意力-指导的答案蒸馏方法来进行阅读理解模型压缩,如图 4 所示。
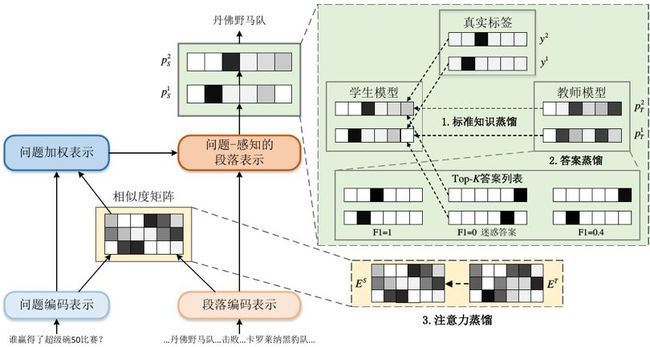
▲ 图4. 注意力指导的答案蒸馏总体示意图
我们发现在使用标准知识蒸馏过程中存在有偏蒸馏现象,为解决该问题,我们提出答案蒸馏(answer distillation)来惩罚模型对于迷惑答案的预测。为了进一步高效蒸馏中间表示,我们提出注意力蒸馏(attention distillation)来匹配教师与学生之间的注意力分布。在 SQuAD1.1 上的实验显示学生单模型相比于教师集成模型只有 0.4% F1 的性能损失,却获得了 12 倍的推理加速。学生模型甚至在对抗 SQuAD 和 NarrativeQA 数据集上超过了教师模型性能。
阅读+验证架构(Read + Verify Architecture)
针对面向无答案问题的阅读理解任务,我们提出了阅读+验证架构,如图 5 所示。

▲ 图5. 阅读+验证架构总体示意图
该系统不仅利用一个神经网络阅读器来抽取候选答案,还使用了一个答案验证器(answer verifier)来判断预测答案是否被输入文本所蕴含。此外,我们引入了两个辅助损失函数(auxiliary losses)来解决传统方法采用共享归一化操作时产生的概率互相干扰问题,并且探索了针对答案验证任务的三种不同网络结构。在 SQuAD 2.0 数据集上的实验显示,我们的系统在提交时取得了先进性能。
检索-阅读-重排序网络(Retrieve-Read-Rerank Network)
在开放域问答任务中,传统流水线方法面临训练-测试不一致以及重复编码等问题。为解决这些问题,我们提出了检索-阅读-重排序网络,如图 6 所示。
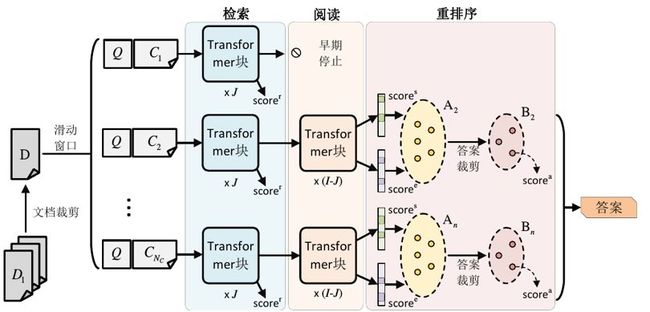
▲ 图6. 检索-阅读-重排序网络示意图
该模型包含一个早期停止的检索器(early-stopped retriever)、一个远程监督的阅读器(distantly-supervised reader)、以及一个跨度级答案重排器(span-level answer reranker)。这些组件被集成到一个统一的神经网络中以便进行端到端训练来缓解训练-测试不一致问题。另外,编码表示能在多个组件之间被复用以避免重复编码。在四个开放域问答数据集上的实验显示,该模型相比流水线方法性能更优,同时效率更高。
多类型-多跨度网络(Multi-Type Multi-Span Network)
针对离散推理阅读理解任务,当前方法通常面临答案类型覆盖不全、无法支持多答案预测以及孤立预测算术表达式等问题。为解决这些问题,我们提出了多类型-多跨度网络,如图 7 所示。

▲ 图7. 多类型-多跨度网络总体示意图
该模型使用一个多类型答案预测器(multi-type answer predictor)以支持对四种答案类型的预测,采用一个多跨度抽取(multi-span extraction)方法以动态地抽取指定个数的文本跨度,并使用一个算术表达式重排名(arithmetic expression reranking)机制来对若干候选表达式进行排序以进一步确定预测。在 DROP 数据集上的实验表明,该模型显著提高了答案类型覆盖度和多答案预测精度,相比之前方法性能获得了大幅度提升。
研究展望
机器阅读理解已经成为自然语言处理领域的热门研究方向之一。虽然近几年在该领域的研究进展迅速,但是该领域仍有大量未解决的问题与挑战亟待研究人员探索。本文在此对未来研究工作提出几点展望:
阅读理解模型的常识推理能力
当前阅读理解模型主要关注回答事实类问题(factoid questions),问题答案往往能直接在原文中找到。然而,如何基于常识和背景知识进行推理以获得答案仍旧是一个巨大的挑战。为了促进该方向的发展,若干数据集如 CommonsenseQA [3] 和 CosmosQA [4] 相继被提出。在这些数据集中,机器需要结合常识知识来回答诸如“我可以站在河上的什么地方看水流淌而不湿身?”这样的问题,因此更具挑战性。
阅读理解模型的可解释性
当前的阅读理解模型往往是一个大的黑盒(black-box)神经网络,导致的问题是模型可解释性差。一个好的阅读理解系统应该不仅能提供最终答案,还要能够提供做出该预测背后的逻辑。因此,如何推进阅读理解模型的可解释性也是未来很有前景的一个研究方向。幸运的是,我们已经看到有若干工作 [5-6] 在朝着这个方向努力。
开放域问答系统的实时性
构建一个快速响应的开放域问答系统对于实际部署线上应用至关重要。然而,由于开放域问答需要经历检索-阅读的流水线过程,且需要为每个问题-文档样例重新编码,导致这些系统面临实时性方面的严峻挑战。虽然当前有工作 [7-8] 通过预先构建问题-无关的段落表示来节约运算开销,然而这些方法普遍会导致不同程度的性能下降。因此,如何令开放域问答系统达到实时响应同时保持模型性能也是一个重要的研究方向。
跨语种机器阅读理解
虽然当前机器阅读理解取得了快速的发展,但是大部分工作都是在英语语料下开展的,其他语种因为缺乏足够的语料而进展缓慢。因此,如何利用源语言如英语来辅助目标语言如中文的训练就是一个亟待探索的方向。我们已经看到有初步的工作 [9-10] 在该方向上进行探索。
博士学位论文链接:
https://github.com/huminghao16/thesis/blob/master/thesis.pdf
Reference
[1] Hermann K M, Kocisky T, Grefenstette E, et al. Teaching Machines to Read and Comprehend. NIPS 2015: 1693-1701.
[2] Rajpurkar P, Zhang J, Lopyrev K, et al. SQuAD: 100,000+ Questions for Machine Comprehension of Text. EMNLP 2016: 2383-2392.
[3] Talmor A, Herzig J, Lourie N, et al. CommonsenseQA: A Question Answering Challenge Targeting Commonsense Knowledge. NAACL 2019: 4149-4158.
[4] Huang L, Le Bras R, Bhagavatula C, et al. Cosmos QA: Machine Reading Comprehension with Contextual Commonsense Reasoning. EMNLP-IJCNLP 2019: 2391-2401.
[5] Gupta N, Lin K, Roth D, et al. Neural Module Networks for Reasoning over Text[J]. arXiv preprint arXiv:1912.04971, 2019.
[6] Jiang Y, Bansal M. Self-Assembling Modular Networks for Interpretable Multi-Hop Reasoning. EMNLP-IJCNLP 2019: 4464-4474.
[7] Seo M, Kwiatkowski T, Parikh A, et al. Phrase-Indexed Question Answering: A New Challenge for Scalable Document Comprehension. EMNLP 2018: 559-564.
[8] Seo M, Lee J, Kwiatkowski T, et al. Real-Time Open-Domain Question Answering with Dense-Sparse Phrase Index[J]. arXiv preprint arXiv:1906.05807, 2019.
[9] Lewis P, Oğuz B, Rinott R, et al. Mlqa: Evaluating cross-lingual extractive question answering[J]. arXiv preprint arXiv:1910.07475, 2019.
[10] Cui Y, Che W, Liu T, et al. Cross-Lingual Machine Reading Comprehension. EMNLP-IJCNLP 2019: 1586-1595.
后记
如果你对机器阅读理解感兴趣,想从事这方面的研究,那么请不要犹豫,赶快联系我吧。
联系邮箱:
![]()
点击以下标题查看更多往期内容:
从Word2Vec到BERT
万能的Seq2Seq:基于Seq2Seq的阅读理解问答
ICLR 2020:从去噪自编码器到生成模型
训练技巧 | NLP中的对抗训练 + PyTorch实现
后BERT时代的那些NLP预训练模型
从三大顶会论文看百变Self-Attention
 #投 稿 通 道#
#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
???? 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
???? 投稿邮箱:
• 投稿邮箱:[email protected]
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
????
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。
▽ 点击 | 阅读原文 | 下载论文